


前言
参数高效微调(PEFT)的背景:
自2018年BERT模型问世以来,自然语言处理(NLP)领域的主流范式便是“预训练语言模型 + 微调”。在这一趋势下,模型规模变得越来越大,因为通常尺寸越大的模型能带来更好的性能表现。例如,早期的BERT-Base模型参数量仅为0.1B(1亿),而当今意义上的大模型,参数量至少要从6B或7B(60或70亿)起步。
然而,模型规模的急剧扩张也带来了严峻的挑战。若采用传统的全量参数微调方式,需要更新模型中所有的参数,这会消耗极其巨大的计算与存储资源。对于个人开发者或许多中小型机构而言,很难承担如此高昂的训练成本。
为了解决这一困境,参数高效微调(Parameter-Efficient Fine-Tuning, PEFT) 技术应运而生。PEFT的核心思想是,在微调时冻结预训练模型的绝大部分参数,仅对其中极小一部分参数进行训练。这些被训练的参数可能是模型原有的(selective),也可能是额外引入的(additive)。

这种方法带来了显著的优势:
- 性能优越:在很多场景下,PEFT仅用极小的代价就能达到接近甚至不输于全量微调的性能,颇有“四两拨千斤”的效果。
- 算力需求低:由于只训练一小部分参数,极大地降低了对计算资源的需求,甚至在单张显卡上就能完成一些大模型的微调工作。
- 存储成本小:训练后只需保存经过训练的那一小部分参数,其大小与动辄几十GB的原始大模型相比几乎可以忽略不计,极大地节约了存储成本。
PEFT包含了一系列具体的技术方法,如基于Adapter、Prompt-Tuning、LoRA等,它们共同构成了大模型时代下高效、经济的微调解决方案。
BitFit 参数高效微调方法
chatbot_bitfit.ipynb 是在之前学习的“生成式对话机器人”代码基础上直接修改
微调前的困境:显存消耗巨大
在应用高效微调技术之前,我们先要理解为什么要这么做。在原始的 chatbot.ipynb 中,我们对整个模型进行了全量微调。我们来看一下,对于一个像 bloom-1b4-zh 这样拥有约13亿(1.3B)参数的模型,全量微调对显存的消耗有多大。
根据 ipynb 文件中的推算:
- 模型参数本身:一个参数通常用32位浮点数(4个字节)存储。加载模型本身就需要
13亿 * 4字节 ≈ 5.2GB的显存。 - 梯度:在反向传播时,需要为每个参数计算并存储一个梯度,这部分的显存消耗和模型参数一样大,即
13亿 * 4字节 ≈ 5.2GB。 - 优化器状态:如果使用像Adam这样的主流优化器,它会为每个参数维持两个状态(一阶和二阶矩估计),所以需要
13亿 * 4字节 * 2 ≈ 10.4GB的显存。
总计:5.2GB + 5.2GB + 10.4GB = 20.8GB。
这意味着,仅仅是启动全量微调,就需要至少 20.8GB 的显存,这还没有算上数据本身以及激活值等其他开销。这对于大部分个人开发者和研究者来说是一个很高的门槛。
高效微调方案:BitFit
为了解决上述显存困境,这个 Notebook 采用了一种名为 BitFit (Bias-term Fine-tuning) 的参数高效微调方法。
- BitFit是什么?
它是最简洁的高效微调方法之一。它的核心思想非常简单:在微调时,冻结模型中所有的权重(weight)参数,只训练偏置(bias)参数。
- 为什么这样做有效?
直观上可以理解为,一个预训练好的大模型已经学到了丰富的语言知识,这些知识主要存储在庞大的权重矩阵中。我们进行微调,很多时候只是需要对模型进行微小的“校准”或“适配”,让它适应我们的特定任务。而只调整偏置项(bias),就像是给模型的每个神经元输出增加或减少一个固定的偏移量,这种微小的调整在很多任务上已经足够了,并且代价极低。
代码细节解读:如何从全量微调修改为 BitFit
对比原始的 chatbot.ipynb,您会发现,从数据加载到数据预处理的所有步骤都完全一样。唯一的核心改动,就是增加了一个简单的循环来“冻结”大部分参数。
核心改动代码:
# bitfit
# 选择模型参数里面的所有bias部分
num_param = 0
for name, param in model.named_parameters():
if "bias" not in name:
param.requires_grad = False
else:
num_param += param.numel()
print(f"可训练参数数量: {num_param}")
print(f"可训练参数比例: {num_param / sum(p.numel() for p in model.parameters())}")这段代码的作用解读:
for name, param in model.named_parameters():这行代码会遍历模型中的每一个参数,包括它的名字(比如transformer.h.0.self_attention.query_key_value.weight)和参数本身。if "bias" not in name:这是关键的判断。如果参数的名字里不包含 "bias" 这个词,我们就认为它是一个权重参数。param.requires_grad = False对于所有非偏置(non-bias)的参数,我们将其requires_grad属性设置为False。这个操作是在告诉PyTorch的自动求导系统:“在训练时,请忽略这个参数,不要计算它的梯度,也不要更新它。” 这就实现了参数的“冻结”。else:如果参数的名字里包含 "bias",我们就不做任何操作,它默认就是可训练的。
效果如何?
通过这个简单的操作,模型中可训练的参数数量急剧下降。从 Notebook 的计算结果可以看到,可训练的参数(即所有 bias 参数)仅占总参数量的 0.07% 左右!这意味着,我们需要计算和存储的梯度、以及优化器状态都将变得极小,从而大幅降低了对显存的需求。
之后呢?
神奇的是,在完成了上述参数冻结操作后,后续所有的步骤,包括 TrainingArguments 的配置、Trainer 的创建以及 trainer.train() 的调用,都和全量微调完全一样,不需要任何改动! 这也体现了 Hugging Face Trainer 设计的优越性。
总结
从“生成式对话机器人”到“使用BitFit进行微调”,我们只做了一件事:
在模型加载后、开始训练前,增加一个循环,遍历模型所有参数,将非 bias 参数的 requires_grad 属性设为 False。
通过这个简单的改动,我们将一个需要超过 20GB 显存才能进行的“重量级”全量微调任务,变成了一个对硬件要求极低的“轻量级”高效微调任务,但依然能得到一个表现不错的对话机器人。
Prompt Tuning微调法
这份 chatbot_prompt_tuning.ipynb 同样是在“生成式对话机器人”代码的基础上修改而来,它和我们之前学习的 BitFit 是两种不同的高效微调思路。这次我们将借助 Hugging Face 的 PEFT(Parameter-Efficient Fine-Tuning)库来更方便地实现。
核心思想:冻结模型,只训练“提示”
Prompt Tuning 的核心思想:

- 做法:Prompt Tuning 的策略是 完全冻结 预训练大模型的所有原始参数。我们不动模型的任何一层,而是在输入数据的最前端,加入一小段可训练的、连续的“虚拟提示”(Prompt)。训练时,我们只更新这个 Prompt 对应的嵌入(Embedding)向量,而模型的其他部分保持不变。
- 工作原理:如上图所示,原始的输入文本(Input)会被转换成嵌入向量(蓝色的方块)。Prompt Tuning 在这些蓝色方块前,拼接上了一段橙色的、可学习的 Prompt 嵌入向量。在整个训练过程中,蓝色方块固定不变,只有橙色方块会根据任务数据进行学习和更新。这就像是为模型找到了一个最优的“咒语”或“指令前缀”,引导它更好地完成下游任务。
- 两种形式:
- Hard Prompt (硬提示):这个“提示”是由人类可读的、真实的文本构成的。我们用这段文本的嵌入向量来初始化可训练的 Prompt。
- Soft Prompt (软提示):这个“提示”不是真实文本,而是一系列“虚拟令牌”(virtual tokens)。它们没有对应的文字,只是纯粹的、从头开始学习的向量。这种方式更加灵活和通用。
代码细节解读:如何使用 PEFT 库实现 Prompt Tuning
与 BitFit 需要我们手动写循环去冻结参数不同,PEFT 库将这个过程封装得非常好,我们只需要进行一些配置即可。
PEFT Step 1: 配置文件
这是应用 Prompt Tuning 的第一步,也是最关键的一步。
- 关键代码:
from peft import PromptTuningConfig, get_peft_model, TaskType, PromptTuningInit config = PromptTuningConfig( task_type=TaskType.CAUSAL_LM, prompt_tuning_init=PromptTuningInit.TEXT, prompt_tuning_init_text="下面是一段人与机器人的对话。", num_virtual_tokens=len(tokenizer("下面是一段人与机器人的对话。")["input_ids"]), tokenizer_name_or_path="Langboat/bloom-1b4-zh" ) - 作用解读: 我们创建了一个
PromptTuningConfig对象来定义如何进行 Prompt Tuning。task_type=TaskType.CAUSAL_LM: 明确告诉 PEFT 我们的任务是因果语言模型(文本生成)。prompt_tuning_init=PromptTuningInit.TEXT: 指定初始化方式为 Hard Prompt,即用一段真实文本来初始化。prompt_tuning_init_text="...": 这就是我们用来初始化的具体文本。num_virtual_tokens=len(...): 设置虚拟提示的长度。对于 Hard Prompt,这个长度应该和初始化文本的令牌(token)数量一致。
(注:代码中注释掉的
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10)则是 Soft Prompt 的配置方式,更加简洁,直接定义需要10个可学习的虚拟令牌即可。)
PEFT Step 2: 创建模型
- 关键代码:
model = get_peft_model(model, config) model.print_trainable_parameters() - 作用解读:
get_peft_model(model, config): 这是PEFT库的魔法所在。它接收原始的、未做任何修改的model和我们刚刚创建的config,然后自动地为模型注入 Prompt Tuning 所需的模块,并冻结其他所有参数。model.print_trainable_parameters(): 这个方便的函数可以打印出模型的可训练参数信息。从输出结果trainable params: 20,480 || all params: 1,337,334,272 || trainable%: 0.001531...可以看到,可训练参数的数量极小,仅占总参数量的 0.0015%!
训练与推理
- 训练: 和 BitFit 一样,在用
get_peft_model封装好模型后,后续的Trainer定义和trainer.train()调用流程与全量微调完全相同,PEFT库会在后台自动处理好一切。 - 推理:
- 加载模型时,需要先加载原始的、大的基础模型 (
AutoModelForCausalLM.from_pretrained(...))。 - 然后使用
PeftModel.from_pretrained(...)来加载我们训练好的、小巧的 Prompt Tuning 模块(通常只有几十KB),并将其“附加”到基础模型上。 - 推理的调用方式也完全不变,
PEFT模型会自动将学到的“最优提示”加在你的输入前面。
- 加载模型时,需要先加载原始的、大的基础模型 (
总结与对比
- Prompt Tuning vs. BitFit:
- BitFit 是在模型内部,选择一小部分已有的参数(偏置项)进行训练。
- Prompt Tuning 是完全冻结模型内部所有参数,在模型外部(输入层)增加新的参数(Prompt嵌入)进行训练。
- 核心优势:
- 极高的参数效率:可训练参数占比极低,甚至比 BitFit 还要低一个数量级。
- 无需修改模型结构:通过在输入端做文章,完全不改变原模型的内部结构。
- ** checkpoints 极小**:训练后保存的只是那几十个 Prompt 向量的权重,文件非常小,便于存储和分发。
通过使用 PEFT 库,我们可以用几行配置代码就轻松实现 Prompt Tuning,这使得在有限的资源下探索大模型的能力变得前所未有的简单。
P-Tuning微调法
P-Tuning,是对Prompt Tuning 的一种重要改进。
这份 chatbot_ptuning.ipynb 文件同样是基于对话机器人代码修改。
核心思想:给 Prompt 加上一个“编码器”
P-Tuning 的思想:

- 出发点:P-Tuning 认为,直接让模型去学习最优的“虚拟提示”(Soft Prompt)有时候是不稳定的,而且效果可能不佳。
- 做法:P-Tuning 在 Prompt-Tuning 的基础上,引入了一个额外的、小型的神经网络模块,称为 Prompt Encoder(提示编码器)。
- 工作原理:
- 和 Prompt Tuning 一样,我们定义一些可学习的“虚拟提示”嵌入向量(Prompt Embedding)。
- 关键区别:这些初始的嵌入向量不会直接送入大模型,而是先经过这个小巧的 Prompt Encoder(通常是一个 LSTM 或 MLP 网络)进行一次加工和计算。
- Prompt Encoder 的输出,才是最终注入到大模型输入层的、用来引导任务的“最优提示”向量。
- 优势:这个 Prompt Encoder 增加了模型的表达能力,它可以学习到虚拟提示之间更复杂的相互关系,从而生成更有效、更稳定的“提示”,最终能加速模型收敛并提升性能。
代码细节解读:如何从 Prompt Tuning 修改为 P-Tuning
在 PEFT 库的帮助下,从 Prompt Tuning 切换到 P-Tuning 非常简单,我们只需要更换一个配置文件即可。
PEFT Step 1: 配置文件
这是 P-Tuning 与 Prompt Tuning 实现上最核心的不同点。
- 关键代码:
from peft import PromptEncoderConfig, TaskType, get_peft_model config = PromptEncoderConfig( task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10, encoder_reparameterization_type="MLP", encoder_dropout=0.1, encoder_num_layers=5, encoder_hidden_size=1024 ) - 作用解读:
PromptEncoderConfig: 我们使用的配置类从PromptTuningConfig换成了PromptEncoderConfig。num_virtual_tokens=10: 同样定义了需要 10 个虚拟令牌。- P-Tuning 专属参数: 后面的一系列
encoder_*参数就是用来定义我们的 Prompt Encoder 的结构。encoder_reparameterization_type="MLP": 指定 Prompt Encoder 的网络类型为 MLP(多层感知机)。encoder_num_layers=5,encoder_hidden_size=1024: 定义了这个 MLP 的具体架构,即它有 5 层,每层的隐藏单元数量为 1024。
PEFT Step 2: 创建模型
- 关键代码:
model = get_peft_model(model, config) model.print_trainable_parameters() - 作用解读:
get_peft_model(model, config): 这一步和之前完全一样。PEFT库会识别出我们传入的是PromptEncoderConfig,并自动为我们构建 P-Tuning 所需的结构(即冻结大模型,并附加上一个可训练的 MLP Prompt Encoder)。model.print_trainable_parameters(): 从输出结果可以看到,P-Tuning 的可训练参数(trainable params: 5,263,360)比 Prompt Tuning(20,480)要多。这是因为我们现在不仅要训练初始的虚拟提示,还要训练整个 MLP Prompt Encoder 网络的参数。尽管如此,它占总参数量的比例(0.39%)依然极小,远远小于全量微调。
训练与推理
和之前所有的高效微调方法一样,一旦通过 get_peft_model 完成了模型的封装,后续的 Trainer 定义、训练过程和推理过程都无需任何改动,PEFT 库会在后台为我们处理好一切。
总结与对比
- P-Tuning vs. Prompt Tuning:
- 结构上:Prompt Tuning 是直接学习“提示”向量;P-Tuning 则是学习一个能生成“提示”向量的小型网络(Prompt Encoder)。
- 参数上:P-Tuning 的可训练参数略多于 Prompt Tuning,因为它包含了 Prompt Encoder 自身的参数。
- 性能上:通过引入 Prompt Encoder,P-Tuning 赋予了“提示”本身更强的表达能力和关联性,因此通常比 Prompt Tuning 更稳定,效果也更好。
可以把 Prompt Tuning 看作是 P-Tuning 的一个简化特例。在实际应用中,如果追求更好的性能和更稳定的训练过程,P-Tuning 是比 Prompt Tuning 更优的选择。
核心思想:在每一层都加上“前缀”
Prefix-Tuning 的思想:

- 出发点:Prompt-Tuning 和 P-Tuning 都只在模型的输入层(Embedding层)添加可学习的提示,这相当于只在最开始告诉模型“该怎么做”。但模型在进行深层计算时,可能会逐渐“忘记”这个初始指令。
- 做法:Prefix-Tuning 做得更彻底。它不再将可学习的提示(在Prefix-Tuning中称为“前缀”Prefix)仅仅加在输入层,而是将其注入到 Transformer 模型的每一层网络中。
- 工作原理:
- 和 P-Tuning 类似,Prefix-Tuning 也使用一个小型网络(Prefix Encoder)来生成最优的虚拟令牌。
- 关键区别:这些生成的虚拟令牌(前缀),会被当作
past_key_values,在 Transformer 的每一层的自注意力(Self-Attention)计算中,拼接到原始输入的Key和Value之前。 - 效果:这相当于在模型的每一层思考和计算时,都有一个可学习的“助手”(即这个前缀)在旁边进行引导和提示。这种更深层次的干预,使得 Prefix-Tuning 能够更精细地控制模型的行为,通常能带来比 P-Tuning 更好的性能。
代码细节解读:如何使用 PEFT 库实现 Prefix-Tuning
在 PEFT 库的加持下,实现 Prefix-Tuning 同样只需要修改配置文件,非常便捷。
PEFT Step 1: 配置文件
这是实现 Prefix-Tuning 的核心。
- 关键代码:
from peft import PrefixTuningConfig, get_peft_model, TaskType config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10) - 作用解读:
PrefixTuningConfig: 我们这次使用的配置类是PrefixTuningConfig。task_type=TaskType.CAUSAL_LM: 同样,明确任务类型为因果语言模型。num_virtual_tokens=10: 定义了需要注入到每一层的虚拟前缀(Prefix)的长度。
PEFT Step 2: 创建模型
- 关键代码:
model = get_peft_model(model, config) model.print_trainable_parameters() - 作用解读:
get_peft_model(model, config):PEFT库会识别出我们传入的是PrefixTuningConfig,并在后台对原始模型进行“手术”。它会修改 Transformer 的每一层的forward函数,使其能够接收并利用我们定义的可训练前缀,同时冻结所有原始参数。model.print_trainable_parameters(): 从输出结果可以看到,Prefix-Tuning 的可训练参数占比(0.17%)虽然依旧极低,但通常会比 P-Tuning 多一些。这是因为它需要在每一层都生成并应用前缀,涉及到的参数会更多。
训练与推理
和之前一样,一旦通过 get_peft_model 完成了模型的封装,后续的 Trainer 定义、训练过程和推理过程都无需任何改动。PEFT 库已经将向每一层注入前缀的复杂逻辑完全封装好了。
总结与对比:Prompt-Tuning 家族演进
至此,我们可以对 Prompt-Tuning 家族做一个清晰的梳理:
- Prompt-Tuning:最基础的版本。在输入层加入可学习的“提示”。
- 好比:在出发前,给司机一张写着目的地的纸条。
- P-Tuning:Prompt-Tuning 的改进版。用一个小型网络(Prompt Encoder)生成更优的“提示”,但仍然只作用于输入层。
- 好比:找一个聪明的导航员,帮你规划出一条最优路线写在纸条上,再交给司机。
- Prefix-Tuning:更进一步的改进。将可学习的“前缀”注入到模型的每一层,持续影响模型的计算过程。
- 好比:导航员不仅在出发前告诉你路线,还在每一个路口都通过对讲机实时提醒司机“该转弯了”。
总的来说,Prefix-Tuning 通过对模型更深、更持续的干预,通常能够获得最好的性能,是这一系列方法中功能最强大的一个。
Lora微调技术
目前应用最广泛、效果也最出色的参数高效微调方法之一:LoRA (Low-Rank Adaptation)。
chatbot_lora.ipynb 和 inference.ipynb 展示了 LoRA 的训练和部署全过程,特别是它独有的“模型合并”特性。
核心思想:低秩矩阵分解
LoRA 的核心思想:


- 基本假设:LoRA 基于一个重要的假设:预训练的大语言模型虽然参数量巨大,但在我们对其进行微调时,参数的改变量(即
W_after - W_before)是“低秩”的。通俗地说,就是这个巨大的改动量矩阵,可以用两个非常小的、瘦长的矩阵相乘来近似模拟。 - 做法:
- 在微调时,我们冻结原始的、巨大的权重矩阵
W。 - 我们不直接更新
W,而是在它旁边增加一个“旁路”。这个旁路由两个很小的矩阵A和B组成。 - 训练时,只有
A和B这两个小矩阵的参数会被更新。模型的最终输出是原始模块的输出Wx和这个旁路的输出BAx相加的结果,即h = Wx + BAx。 - 由于矩阵
A和B的维度很小(秩r通常取4, 8, 16等很小的值),可训练的参数量相比原始的W极小,从而实现了高效微调。
- 在微调时,我们冻结原始的、巨大的权重矩阵
- 推理零损耗的优势:这是 LoRA 最吸引人的特点之一。训练完成后,我们可以将学习到的两个小矩阵
A和B相乘,得到一个与W同样大小的矩阵BA,然后将其直接加到原始权重W上,W_merged = W + BA。合并后的模型与原始模型在结构和大小上完全一样,推理时没有任何额外的计算开销。这与需要一直带着“外挂”的 Prompt/Prefix-Tuning 形成了鲜明对比。
代码细节解读 (chatbot_lora.ipynb)
PEFT 库让 LoRA 的实现变得异常简单。
PEFT Step 1: 配置文件
- 关键代码:
from peft import LoraConfig, TaskType, get_peft_model config = LoraConfig( task_type=TaskType.CAUSAL_LM, target_modules=[".*query_key_value.*"], modules_to_save=["word_embeddings"] ) - 作用解读:
LoraConfig: 我们使用LoraConfig来定义如何应用 LoRA。target_modules=[".*query_key_value.*"]: 这是 LoRA 配置中最重要的参数。它用来指定要对模型中的哪些模块应用 LoRA 技术。这里使用了正则表达式,表示要将 LoRA 应用于所有名字中含有query_key_value的模块(即注意力机制中的查询、键、值映射层)。你可以根据需要将其应用到任何线性层(nn.Linear)。modules_to_save=["word_embeddings"]: 这是一个可选参数,表示除了 LoRA 模块外,我们还希望word_embeddings层也是可训练的,并在保存时一并保存。这在需要扩展词表或微调词义的场景下很有用。
PEFT Step 2: 创建模型
- 关键代码:
model = get_peft_model(model, config) model.print_trainable_parameters() - 作用解读:
get_peft_model: PEFT 库会自动找到config中指定的target_modules,并将它们替换为包含“旁路”计算的peft.lora.Linear层。print_trainable_parameters(): 从输出可以看到,可训练参数只占总参数量的0.29%,实现了极高的参数效率。
LoRA 的合并与部署 (inference.ipynb)
这个 Notebook 专门演示了 LoRA 独特的“先分离训练,后合并部署”的流程。
- 加载 LoRA 模型进行推理:
- 首先加载基础模型
model,然后使用PeftModel.from_pretrained(model, model_id=...)加载训练好的 LoRA 适配器权重。 - 此时的
p_model在推理时,会动态地执行h = Wx + BAx的计算。
- 首先加载基础模型
- 模型合并:
- 关键代码:
merge_model = p_model.merge_and_unload() - 作用解读: 这是一个非常强大的功能。它会执行
W_merged = W + BA的计算,将学习到的旁路权重永久地合并到原始权重中,然后卸载掉 LoRA 旁路,返回一个与原始模型结构完全一样的标准Transformer模型。
- 关键代码:
- 使用合并后的模型:
- 合并后的
merge_model不再需要PEFT库就可以直接使用,它的推理速度和原始模型完全一样,没有任何额外开销。 - 可以使用
merge_model.save_pretrained(...)将这个合并后的、已微调好的完整模型保存下来,方便直接部署或分享给他人使用。
- 合并后的
总结
LoRA 是目前参数高效微调领域的“明星技术”,因为它完美地平衡了性能、效率和部署便利性:
- 通过低秩分解,极大地减少了可训练参数。
- 训练效果优异,在很多任务上能媲美全量微调。
- 独有的可合并特性,使其在推理部署时能做到零额外延迟,这是其他很多 PEFT 方法不具备的巨大优势。
IA3 (Infused Adapter by Inhibiting and Amplifying Inner Activations)。
这份 chatbot_ia3.ipynb 教学资料同样是基于对话机器人代码修改的。通过和我们刚学过的 LoRA 对比,您能更好地理解 IA3 的独特之处。
核心思想:不改权重,只调“激活”
IA3 的核心思想:
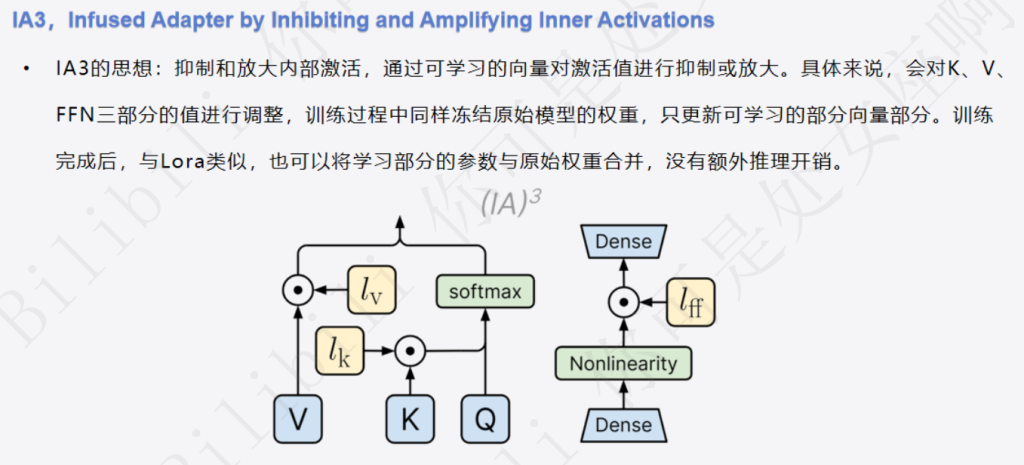
- 出发点:LoRA 是通过增加一个“旁路”来学习权重的增量。而 IA3 另辟蹊径,它认为没必要增加额外的计算路径,我们可以直接对模型内部的信息流动进行微调。
- 做法:IA3 的全称是“通过抑制和放大内部激活值来注入适配器”。它的核心做法是:冻结所有原始权重,只学习几个非常小的“缩放向量”。
- 工作原理:
- 在 Transformer 的关键位置,主要是注意力机制中的 K (Key)、V (Value),以及前馈神经网络(FFN)的部分,IA3 会注入一个可学习的缩放向量(图中的
l_k,l_v,l_ff)。 - 当模型的激活值(Activation,即 K, V, FFN的输出)流经此处时,会被逐元素地乘以这个学习到的缩放向量。
- 如果缩放向量中的某个值大于1,就起到了放大(Amplify) 作用;如果小于1,就起到了抑制(Inhibit) 作用。
- 通过学习如何恰到好处地放大有用的特征、抑制无关的特征,模型就能适应新的任务。
- 在 Transformer 的关键位置,主要是注意力机制中的 K (Key)、V (Value),以及前馈神经网络(FFN)的部分,IA3 会注入一个可学习的缩放向量(图中的
- 类比时间:
- 如果说 LoRA 是给大厨配了个“徒弟”来增加“调整项”。
- 那么 IA3 就像是给了大厨一套“魔法调味瓶”。我们不改变大厨做菜的任何步骤,只教他在处理关键食材(K, V)和最后调味(FFN)时,从不同的瓶子里撒上一点点魔法调味料。这些调味料有的能让鲜味翻倍(放大),有的能盖住腥味(抑制)。我们只学习每个瓶子里的调味料该撒多少。
- 可合并特性:和 LoRA 一样,IA3 训练完成后,学习到的缩放向量也可以被合并到原始权重中,从而实现零额外推理开销。
代码细节解读:PEFT 库中的 IA3 实现
实现 IA3 同样非常简单,甚至比 LoRA 的配置更简洁。
PEFT Step 1: 配置文件
- 关键代码:Python
from peft import IA3Config, TaskType, get_peft_model config = IA3Config(task_type=TaskType.CAUSAL_LM) - 作用解读:
IA3Config: 我们使用IA3Config来进行配置。- 极其简洁:通常情况下,我们只需要告诉它任务类型(
task_type)即可。PEFT库会自动根据模型的结构,在默认的、最有效的位置(通常是 K, V 和 FFN 层)应用 IA3。当然,您也可以通过target_modules等参数进行自定义。
PEFT Step 2: 创建模型
- 关键代码:Python
model = get_peft_model(model, config) model.print_trainable_parameters() - 作用解读:
get_peft_model:PEFT库会找到目标模块,并为它们注入可训练的缩放向量。print_trainable_parameters(): 从输出结果trainable params: 393,216 || all params: 1,337,334,272 || trainable%: 0.0294...可以看到,IA3 的参数效率极高。可训练参数的数量仅仅是几个向量的大小,比 LoRA 通常还要少,仅占总参数量的 0.03% 左右。
训练与推理
和之前的所有 PEFT 方法一样,后续的 Trainer 定义、训练和推理过程都无需任何改动。
总结与对比
- IA3 vs. LoRA:
- 作用方式:LoRA 是通过矩阵加法来学习权重的增量
(Wx + BAx);IA3 则是通过向量乘法来缩放激活值(l*X)。 - 参数效率:两者都非常高效,但 IA3 的可训练参数量通常比 LoRA 更少。
- 可合并性:两者都支持合并,都能实现推理零损耗。
- 作用方式:LoRA 是通过矩阵加法来学习权重的增量
IA3 和 LoRA 是当前最主流的两种可合并的高效微调方法,它们从不同的思路出发,但都达到了相似的、优异的效果。在实际应用中,可以根据具体的任务和模型来选择或进行实验,看看哪种方法表现更好。
Comments NOTHING