


一、前言
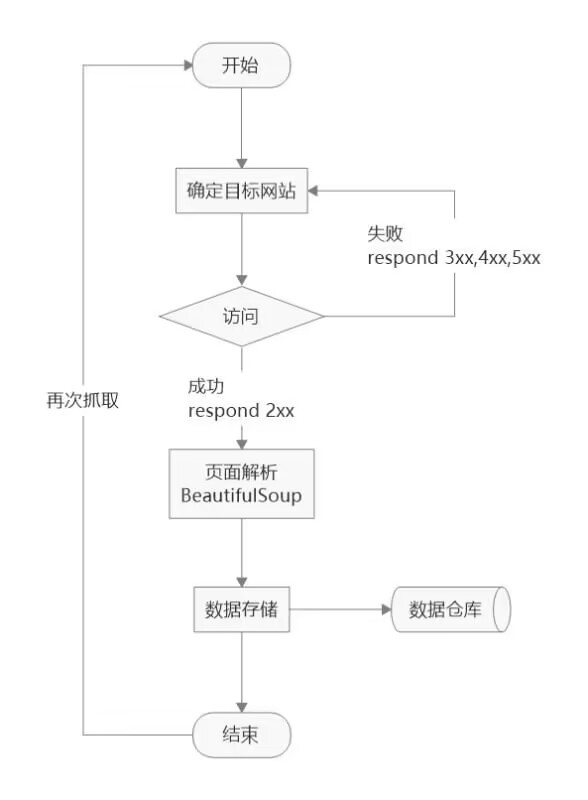
网络爬虫,即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。这样看来,网络爬虫就是一个爬行程序,一个抓取网页的程序,简单的流程图如下。
二、爬虫用到的pip模块以及对应的功能。
|
Pip模块 |
功能 |
|
pip install reqeusts |
用于发送http请求 |
pip install bs4 |
全称是Beatiful Soup,提供一些python式的函数用来处理导航、搜索、修改分析树等功能。通过解析文档为tiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。 |
|
pip install pandas |
基于NumPy的一种工具,提供了大量能使我们快速便捷地处理数据的函数和方法 |
|
pip install selenium |
设置浏览器的参数,浏览器多窗口切换,设置等待时间,文件的上存与下载,Cookies处理以及frame框架操作 |
|
pip install sqlalchemy |
是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作。 |
|
pip install pymongo |
Python中用来操作MongoDB的一个库,MongoDB是一个基于分布式文件存储的数据库,旨在为WEB应用提供可扩展的高性能数据存储解决方案。 |
|
pip install dateparser |
日期解析Python库,支持除用英语编写的日期之外的其它语言 |
|
pip install scrapy |
Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。 |
|
pip install deepspeed |
能够让亿万参数量的模型,能够在自己个人的工作服务器上进行训练推理。 |
|
pip install gerapy_auto_extractor |
是Gerapy的自动提取器模块,可以使用这个包来区分列表页和详细信息页,我们可以使用它来提取 url从列表页中提取datetime,content,而不使用任何XPath或选择器。在对于中文新闻网站来说,它比其他场景更有效。 |
|
pip install gerapy |
可以更方便地控制爬虫运行,更直观地查看爬虫状态,更实时地查看爬取结果,更简单地实现项目部署,更统一地实现主机管理 |
|
pip install scrapyd |
是一个用来部署和运行Scrapy项目的应用,由Scrapy的开发者开发。其可以通过一个简单的Json API来部署(上传)或者控制你的项目。 |
三、实际操作
一:单网页爬取数据
流程:找到相应的网页(人民网),右键打开检查。查找内容所在HTML的位置,找到div块里的class和a类。打开jupyter notebook,导入requests库,爬取到原始内容,字符可能乱码,我们找到原来的字符编码是GB2312,在mysql里先创建一个database,在建立一个表,修改后更改格式,并建立自增id(表头),就可成功导入my sql,MongoDB类似。
调取所需的库
import requests
from bs4 import BeautifulSoup
import pandas as pd
from urllib import parse
from sqlalchemy import create_engine
import pymongo
import json找到目标网站并对其进行解码
url = "http://health.people.com.cn/GB/408568/index.html"
html = requests.get(url)
html.encoding = "GB2312"用BeautifulSoup对人民网数据进行爬取
soup = BeautifulSoup(html.text,'lxml')
list
data = []
for i in soup.find_all("div",class_="newsItems"):
title = i.a.text
date = i.div.text
url = parse.urljoin(url,i.a["href"])
print(title,date,url)
data.append((title,date,url))把爬取的数据转换成DF格式并存储起来
df = pd.DataFrame(data,columns=["title","date","url"])
写入sql
sql = 'insert into qiushi(title,date,url) values(%s,%s,%s) charset=utf8'
engine = create_engine('mysql+pymysql://root:123456@localhost/test1?charset=utf8')
df.to_sql( 'newlist1', con=engine, if_exists='append') 写入MOngoDB
client = pymongo.MongoClient('127.0.0.1',27017) #连接mongodb
database = client["NewsData"] #建立数据库
table = database["News"]
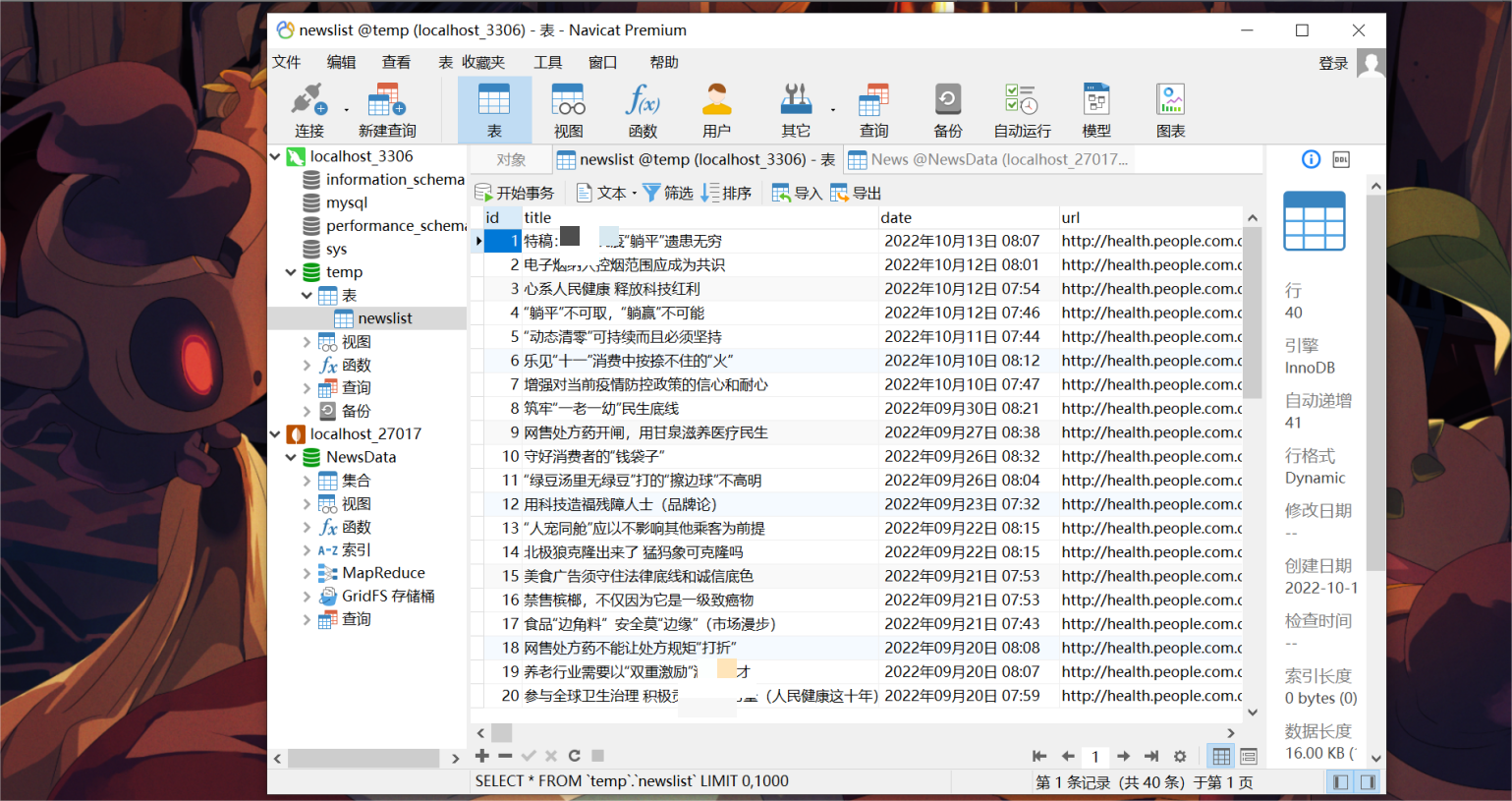
data_ = json.loads(df.T.to_json())导入sql数据库展示:
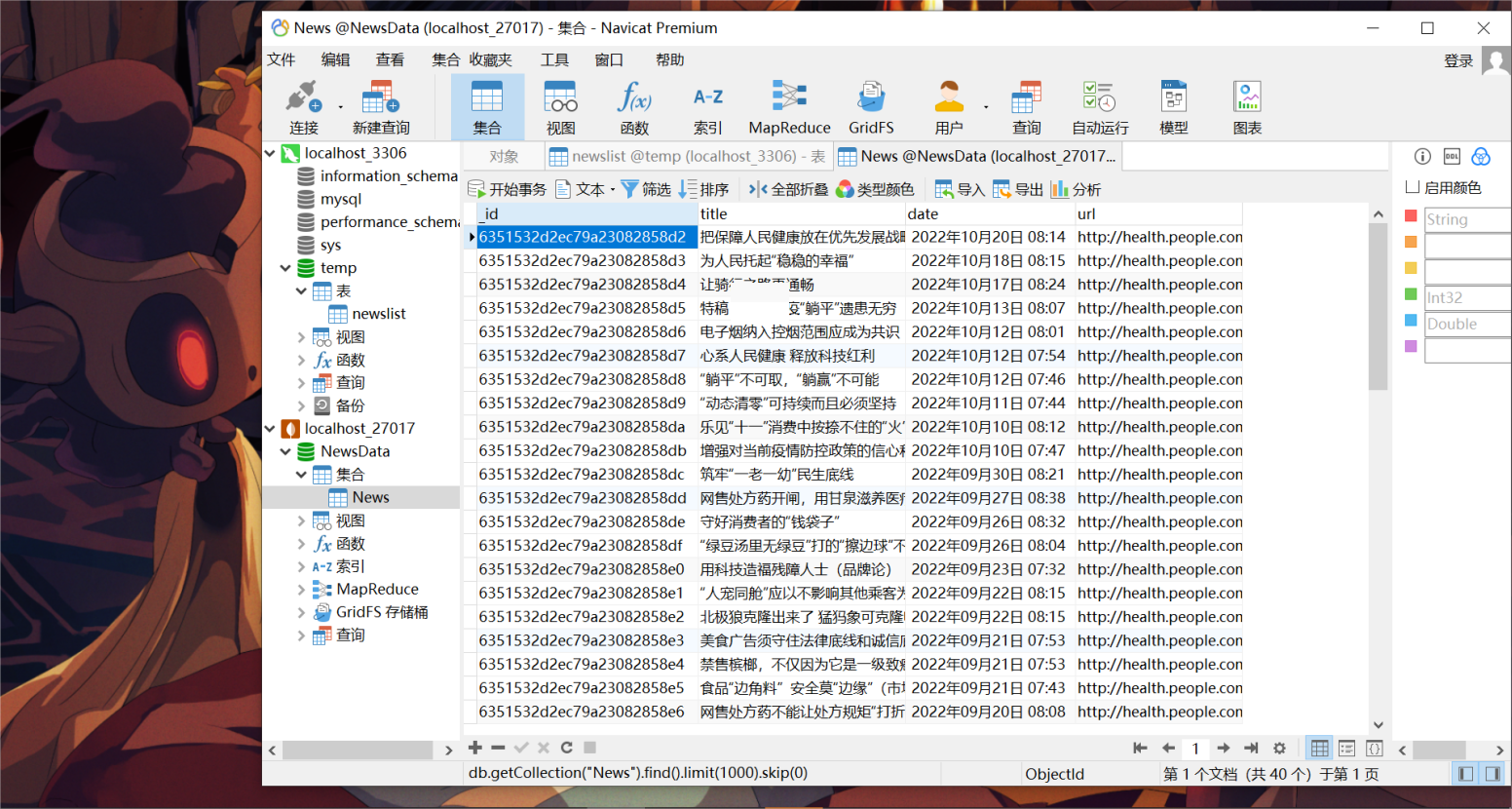
导入MongoDB展示:
遇到的问题:
1 识别不出来pymysql
解决办法:cmd命令下pip install pymysql
2 错误代码1364
解决办法:在mysql里设置自增表头
3 导入MongoDB时出现timeout
解决办法:在bin目录下执行mongod.exe查看存储路径,然后在相应位置建立相应文件
然后在bin目录下cmd执行mongod.exe -dbpath 对应路径,重启电脑,再次导入
发现还是timeout
发现是主机端口27017写错了,改正后导入成功
二:多网页的爬取
1.items,middlewares,pipelines,settings如何配置以及对应代码
Items代码:
把初始代码第九行下面的全部删掉,然后定义想要存储的字段都有什么
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class NewsdataItem(scrapy.Item):
title=scrapy.Field() #文章标题
url=scrapy.Field() #文章链接
date=scrapy.Field() #发布日期
content=scrapy.Field() #文章正文
site=scrapy.Field() #站点
item=scrapy.Field() #栏目
student_id=scrapy.Field() #学号middlewares代码:
我们在初始的基础上添加105行以后的代码
使用中心键调取配置里的信息,随机抽取一个放到USER_AGENT_LIST里
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class NewsdataSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class NewsdataDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
# 添加Header
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
from scrapy.utils.project import get_project_settings
import random
settings = get_project_settings()
class RotateUserAgentMiddleware(UserAgentMiddleware):
def process_request(self, request, spider):
referer = request.url
if referer:
request.headers["referer"] = referer
USER_AGENT_LIST = settings.get('USER_AGENT_LIST')
user_agent = random.choice(USER_AGENT_LIST)
if user_agent:
request.headers.setdefault('user-Agent', user_agent)
print(f"user-Agent:{user_agent}")pipelines代码:
这一步是数据存储,这里我们选着存入MongoDB而不是Mysql,因为Mysql只支持一种数据类型的存储,MongoDB就没有这个限制,在初始代码的基础上,加入第十、十一行,表示导入MongoDB的包,并加载其配置,包括ip地址,用户名,密码,端口号。再把class中的内容全部替换,如果MongoDB没有用户名和密码,第24、25行注释掉,并把原27行的连接方式改成28行。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 添加必备包和加载设置
import pymongo
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class NewsdataPipeline:
# class中全部替换
def __init__(self):
host = settings["MONGODB_HOST"]
port = settings["MONGODB_PORT"]
dbname = settings["MONGODB_DATABASE"]
sheetname = settings["MONGODB_TABLE"]
#username = settings["MONGODB_USER"]
#password = settings["MONGODB_PASSWORD"]
# 创建MONGODB数据库链接
#client = pymongo.MongoClient(host=host, port=port, username=username, password=password)
client = pymongo.MongoClient(host=host, port=port)
# 指定数据库
mydb = client[dbname]
# 存放数据的数据库表名
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
# 数据写入
self.post.insert_one(data)
return itemsettings代码:
把第20行的机器人协议由ture改成false,如果遵守很多网站都爬不了。再把53-55行的注释解开,把54行后面的名字改成中心键代码里的那个名字,其中543这个数字决定了爬取的顺序,数字小的先执行。再把66-69行的注释解开,这个不解开就执行不了pipelines方法类。最后在最底下加入客户端信息(92-111行)和MongoDB的设置(114-118行)
# Scrapy settings for NewsData project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'NewsData'
SPIDER_MODULES = ['NewsData.spiders']
NEWSPIDER_MODULE = 'NewsData.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'NewsData (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'NewsData.middlewares.NewsdataSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'NewsData.middlewares.RotateUserAgentMiddleware': 543,
#'NewsData.middlewares.NewsdataDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'NewsData.pipelines.NewsdataPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
USER_AGENT_LIST = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 添加MONGODB数仓设置
MONGODB_HOST = "localhost" # 数仓IP
MONGODB_PORT = 27017 # 数仓端口号
MONGODB_DATABASE = "NewsData" # 数仓数据库
MONGODB_TABLE = "News_Process_A" # 数仓数据表单2.展示抓取网站的频道列表
| 网址 | 网站 | 板块 |
| https://www.easyzw.com/html/xieren/ | 作文题材 | 写人 |
| https://www.easyzw.com/html/xiejing/ | 作文题材 | 写景 |
| https://www.easyzw.com/html/xiangxiang/ | 作文题材 | 想象 |
| https://www.easyzw.com/html/dongwuzuowen/ | 作文题材 | 动物 |
| https://www.easyzw.com/html/zhouji/ | 作文题材 | 周记 |
| https://www.easyzw.com/html/yingyuzuowen/ | 作文题材 | 英语 |
| https://www.easyzw.com/html/huanbaozuowen/ | 作文题材 | 环保 |
| https://www.easyzw.com/html/xinqing/ | 作文题材 | 心情 |
| https://www.easyzw.com/html/zhuangwuzuowen/ | 作文题材 | 状物 |
| https://www.easyzw.com/html/riji/ | 作文题材 | 日记 |
3.描述爬虫启动start_requests、列表解析parse、内容解析parse_detail、以及数据存储的文字描述对应代码。
爬虫启动start_requests部分:
def start_requests(self):
for url in self.start_urls: #不止爬一个网站,所以要循环,self是调用自身的意思
item = NewsdataItem()
item["site"] = url[1]
item["item"] = url[2]
item["student_id"] = "20201905"
# ['http://www.news.cn/politicspro/', '新华网', '时政']
yield scrapy.Request(url=url[0], meta={"item": item}, callback=self.parse) #yield是返回函数,url是目标网址,callback是函数处理方式列表解析parse部分:
def parse(self, response):
item = response.meta["item"]
site_ = item["site"]
item_ = item["item"]
title_list = response.xpath('//li/a/text()').extract() #xpath的解析方式,要从网站的开发者模式查看,extract表示解析成列表的方式
url_list = response.xpath('//li/a/@href').extract() #双斜杠表示模糊匹配
for each in range(len(title_list)): #取随便哪一个的长度
item = NewsdataItem() #定义字典
item["title"] = title_list[each] #然后开始向里面填充,注意这里面的名字要和items里的一样
item["url"] = "https://www.easyzw.com" + str(url_list[each]) #这一步是相对路径改成绝对路径,有些网站不用改
item["site"] = site_
item["item"] = item_
item["student_id"] = "20201905"
yield scrapy.Request(url=item["url"], meta={"item": item}, callback=self.parse_detail) #这是访问这个循环体内的url,相当于点击操作,处理方法为下面的parse_detail
#meta表示带着已经填充好的url数据内容解析parse_detail:
def parse_detail(self, response):
# data = extract_detail(response.text)
item = response.meta["item"] #重新定义一个字典
item["date"] = ""
strs = response.xpath('//div[@class="content"]').extract_first() #和上面一样从开发者模式定位,first是因为列表无法存入字典
item["content"] = BeautifulSoup(strs, 'lxml').text
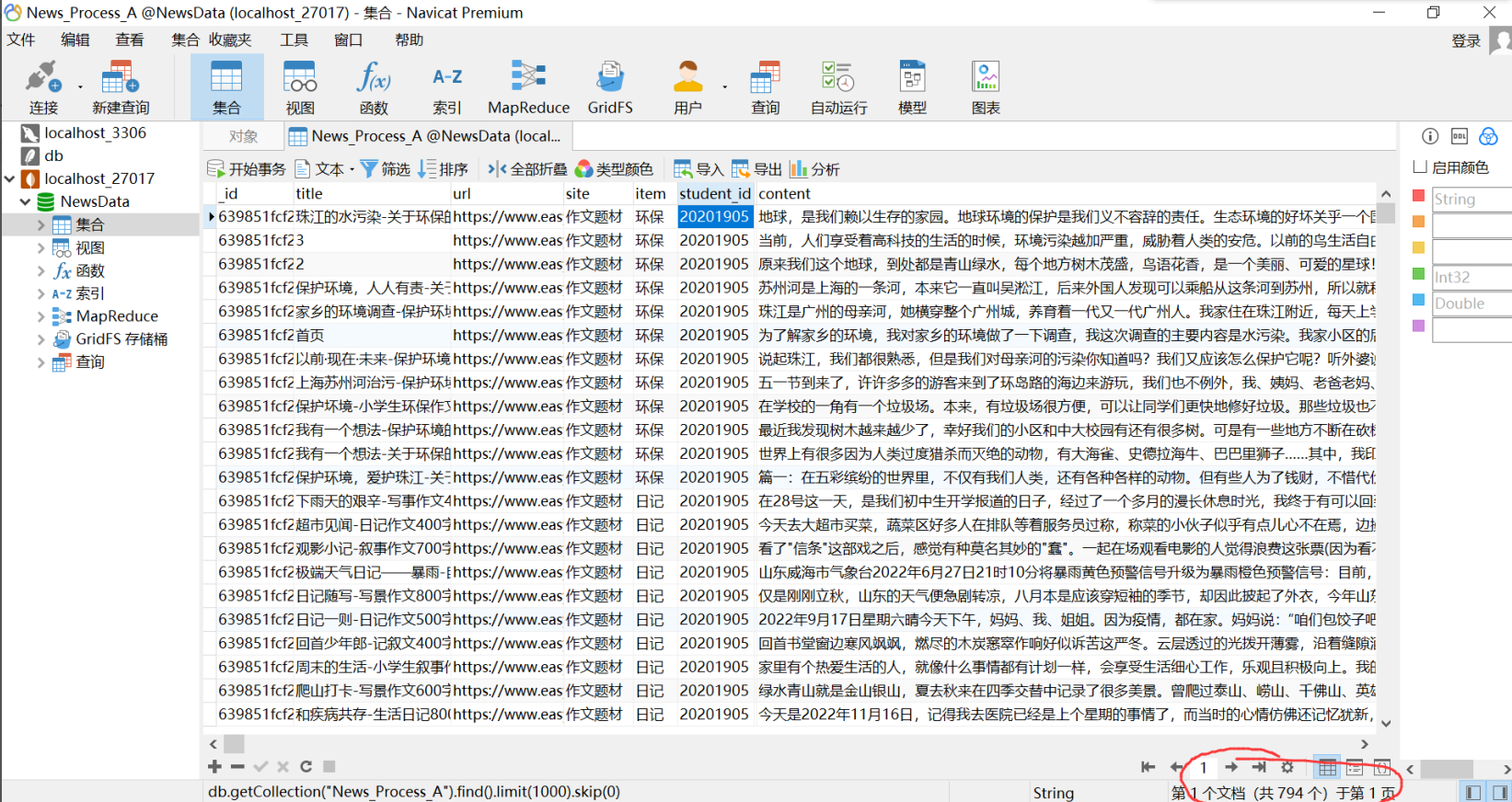
return item #把数据写入MongoDB里4.抓取的数据截图
三:Gerapy的部署、搭建
初始化:
新建一个文件夹,在里面按住shift点右键,输入gerapy init,出现这个表示成功
然后文件夹里会出现这个文件

我们cd进去这个文件,输入cd .\gerapy
然后输入数据迁移命令:gerapy migrate,执行完后会生成很多表单
接下来要初始化一个管理账号,输入命令gerapy initadmin

这里显示密码和账号都是admin
然后启动服务gerapy runserver 0.0.0.0:8000

然后去浏览器输入127.0.0.1:8000,进入这个界面

这里的账号和密码是之前的admin。
主机管理设置:
点击创建
输入下列信息后点创建
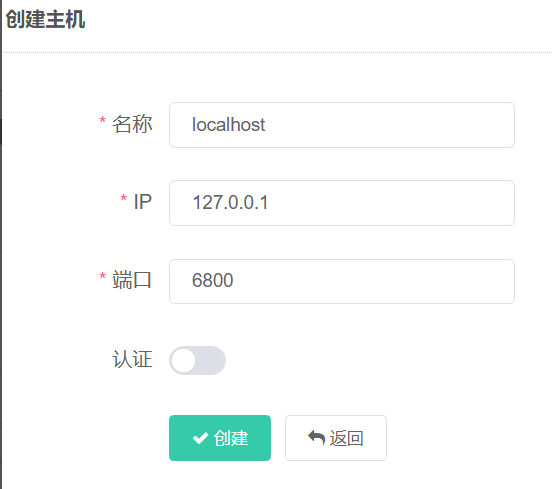
这个时候是不成功的,因为没有启动6800端口服务,我们找到scrapyd.exe所在路径,打开shell脚本,输入.\scrapyd.exe,结果如下,并一直保持该窗口不关闭
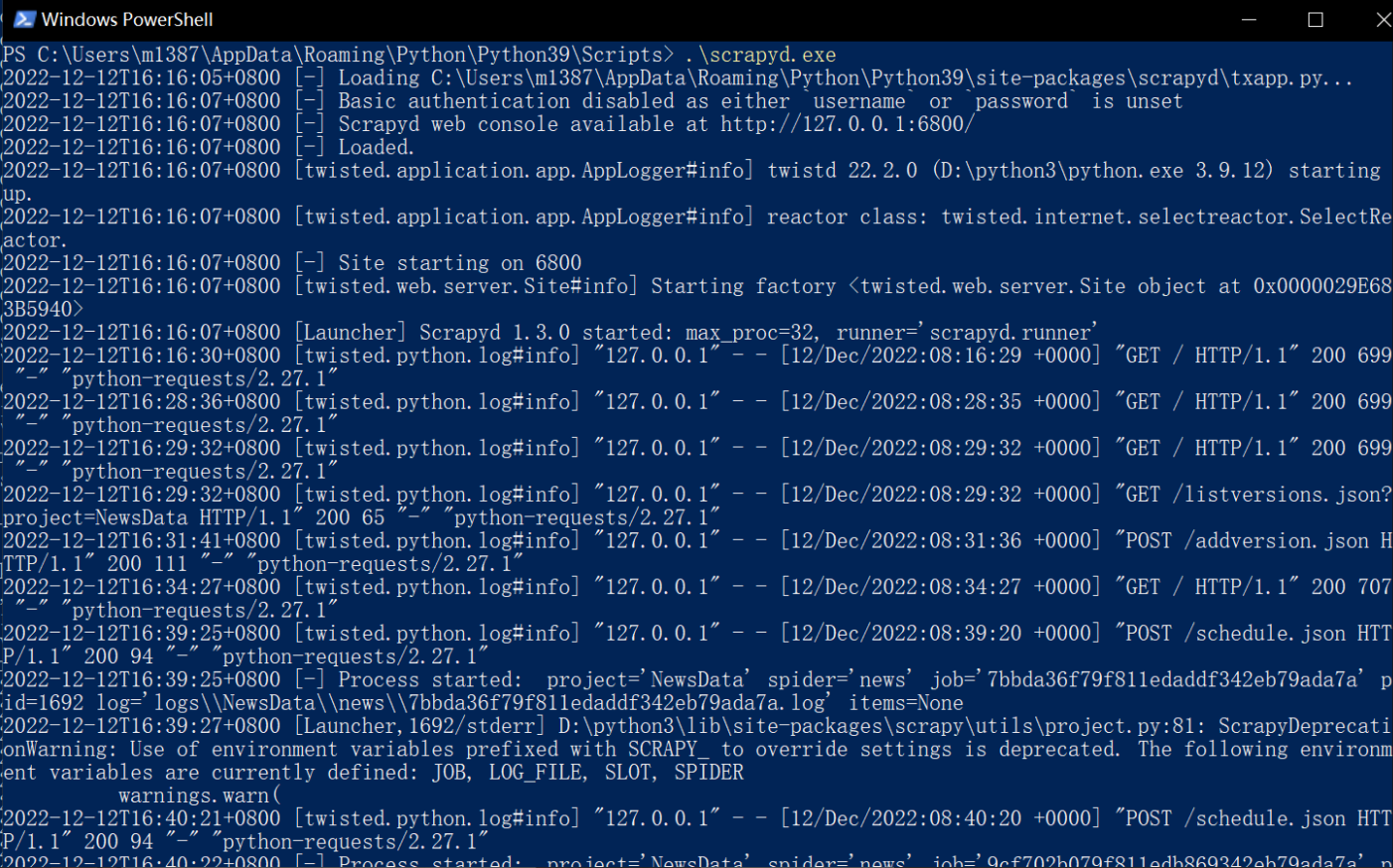
这时主机管理显示正常

项目管理:
我们把之前写的爬虫脚本(NewsData)放到新建文件夹 (5)\gerapy\projects里面,这时候项目管理会出现
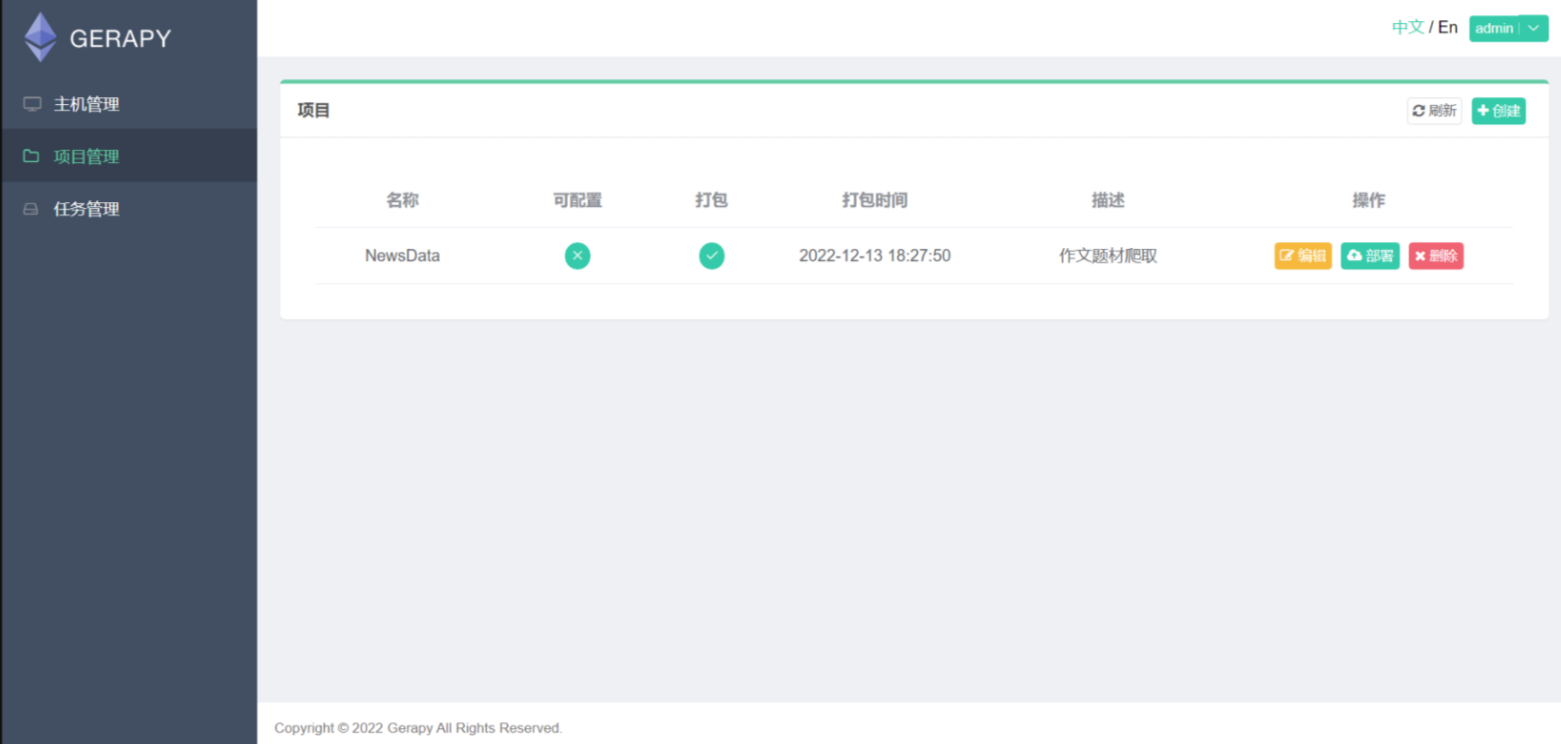
点击部署,输入下方的描述后,点击打包。打包成功后点击部署,会出现主机1部署成功
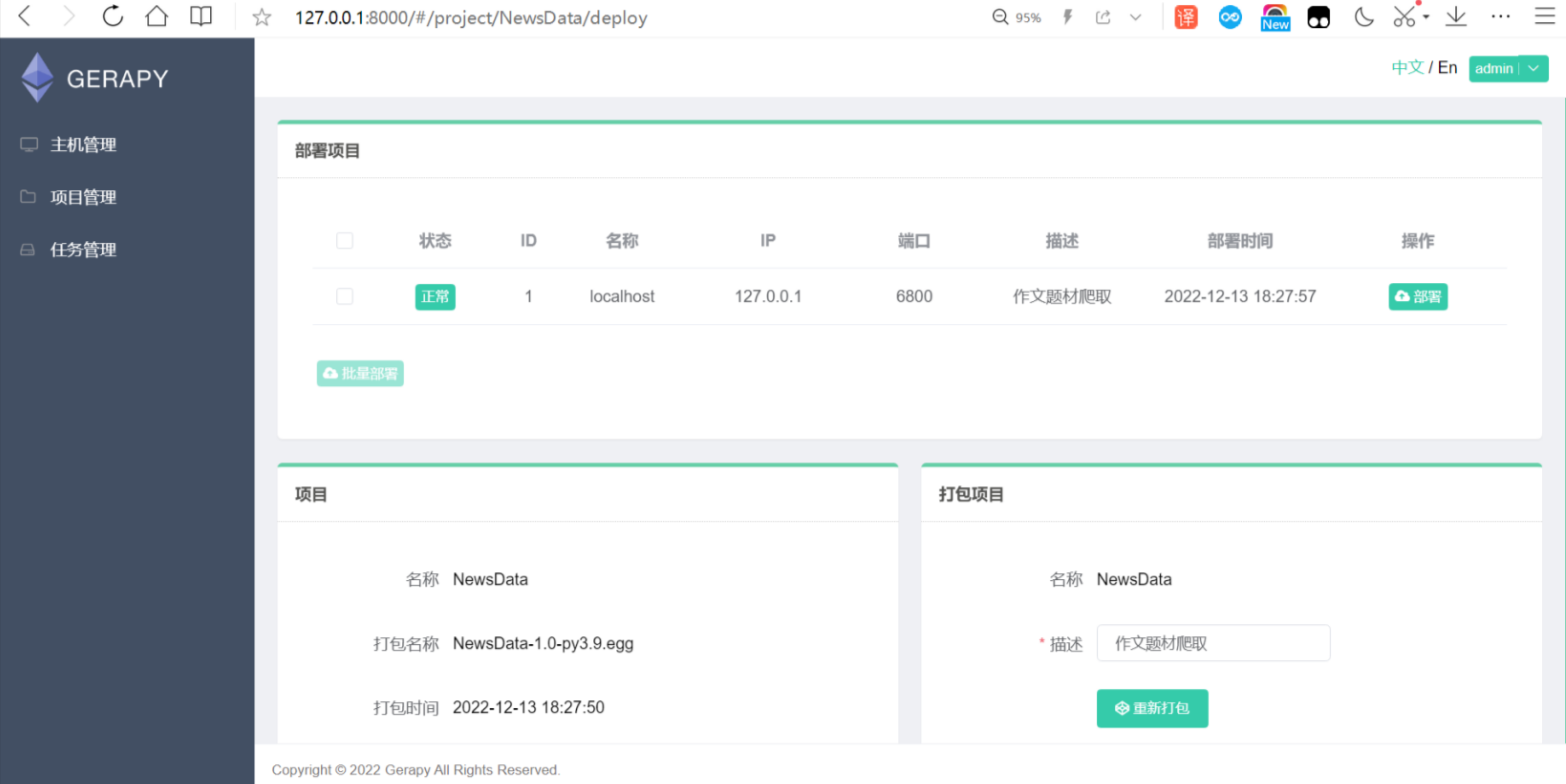
任务管理:
点击创建,开始建立定时任务
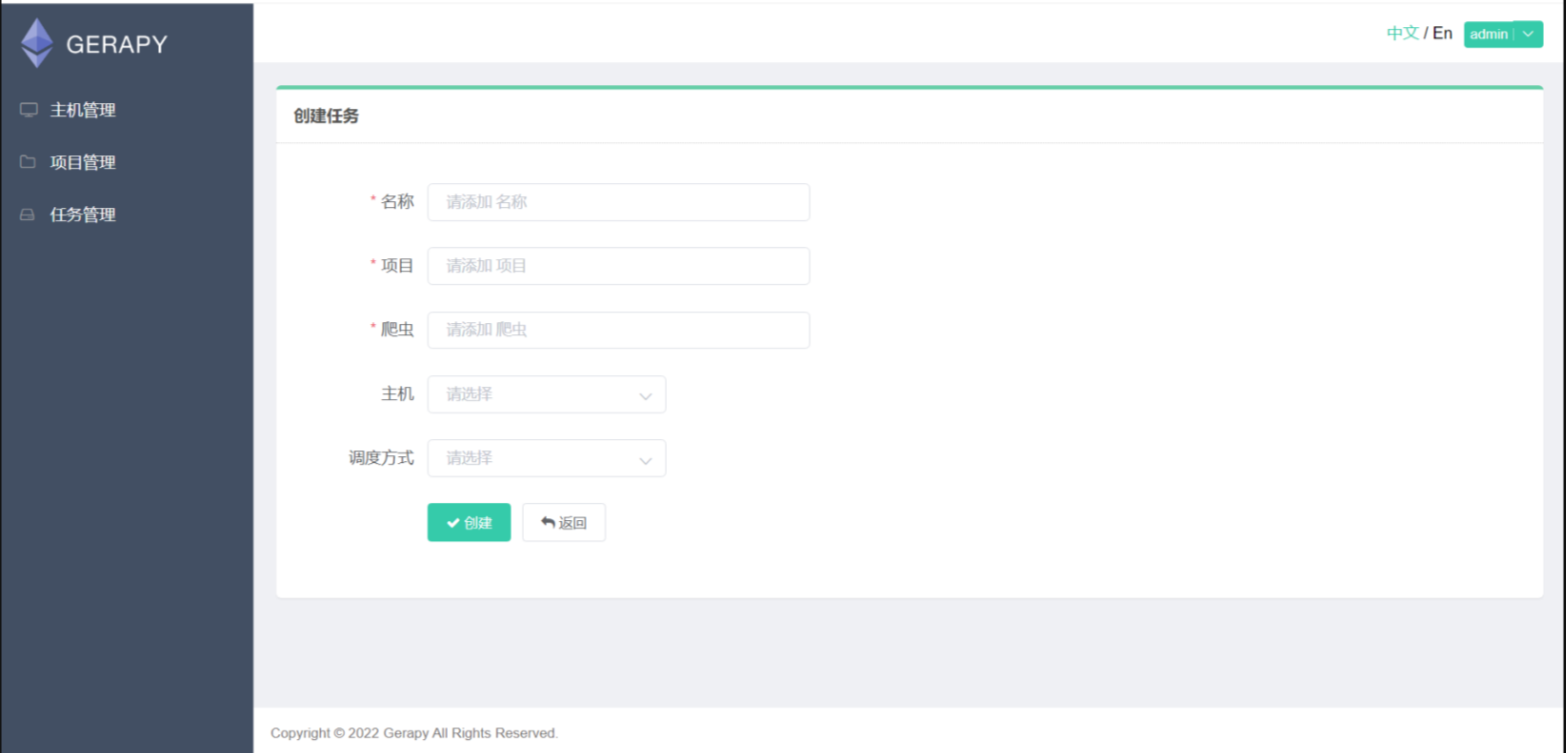
名称自己填,项目名字是projects文件里的名字,爬虫名字是spiders里的py名称,主机选localhost,时间选择亚洲-香港,调度方式选择周期,开始时间和周期可以自己选

创建成功后有这个界面
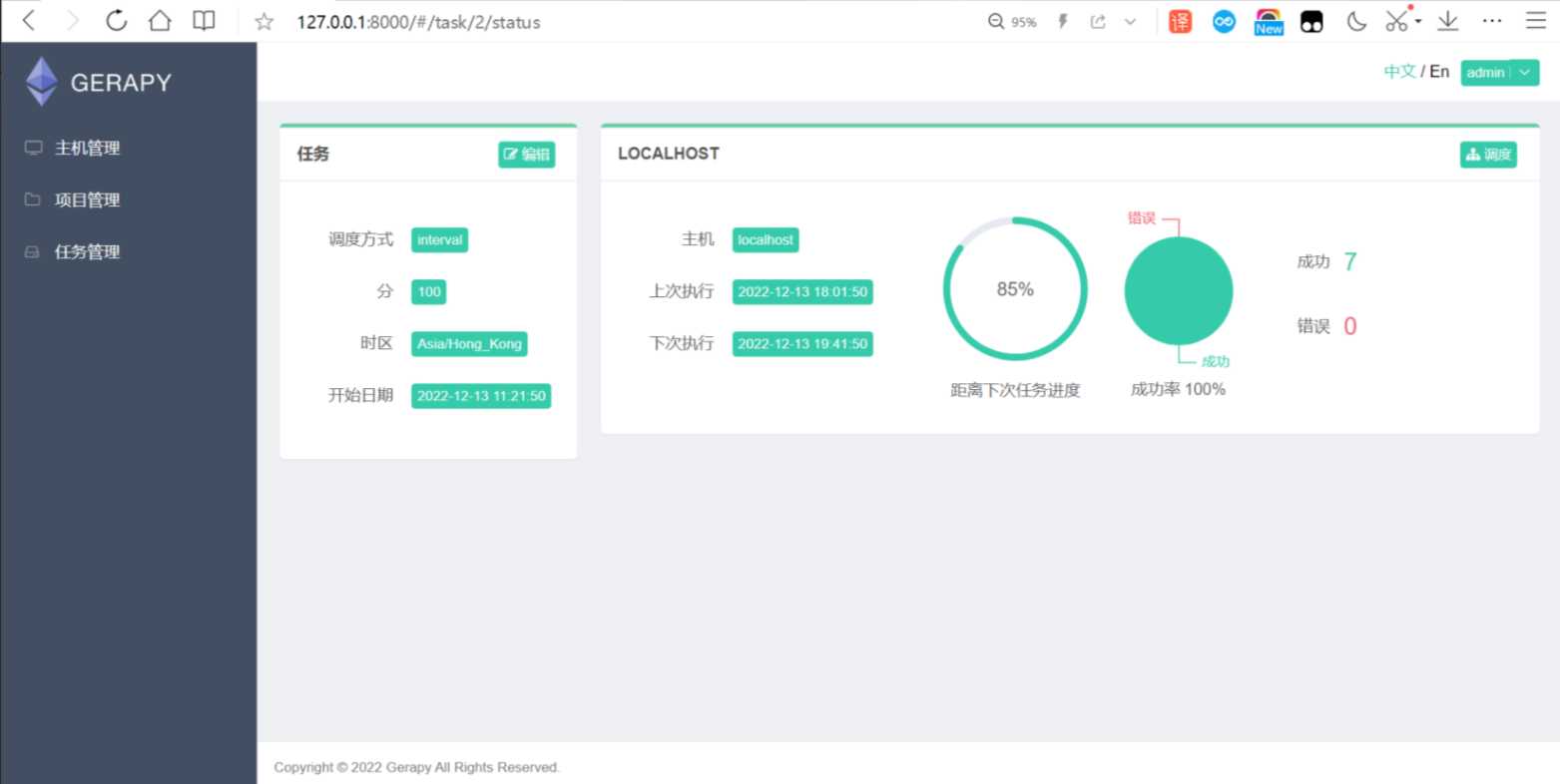
点击状态,可以看执行的情况
点击调度可以看脚本是不是在执行
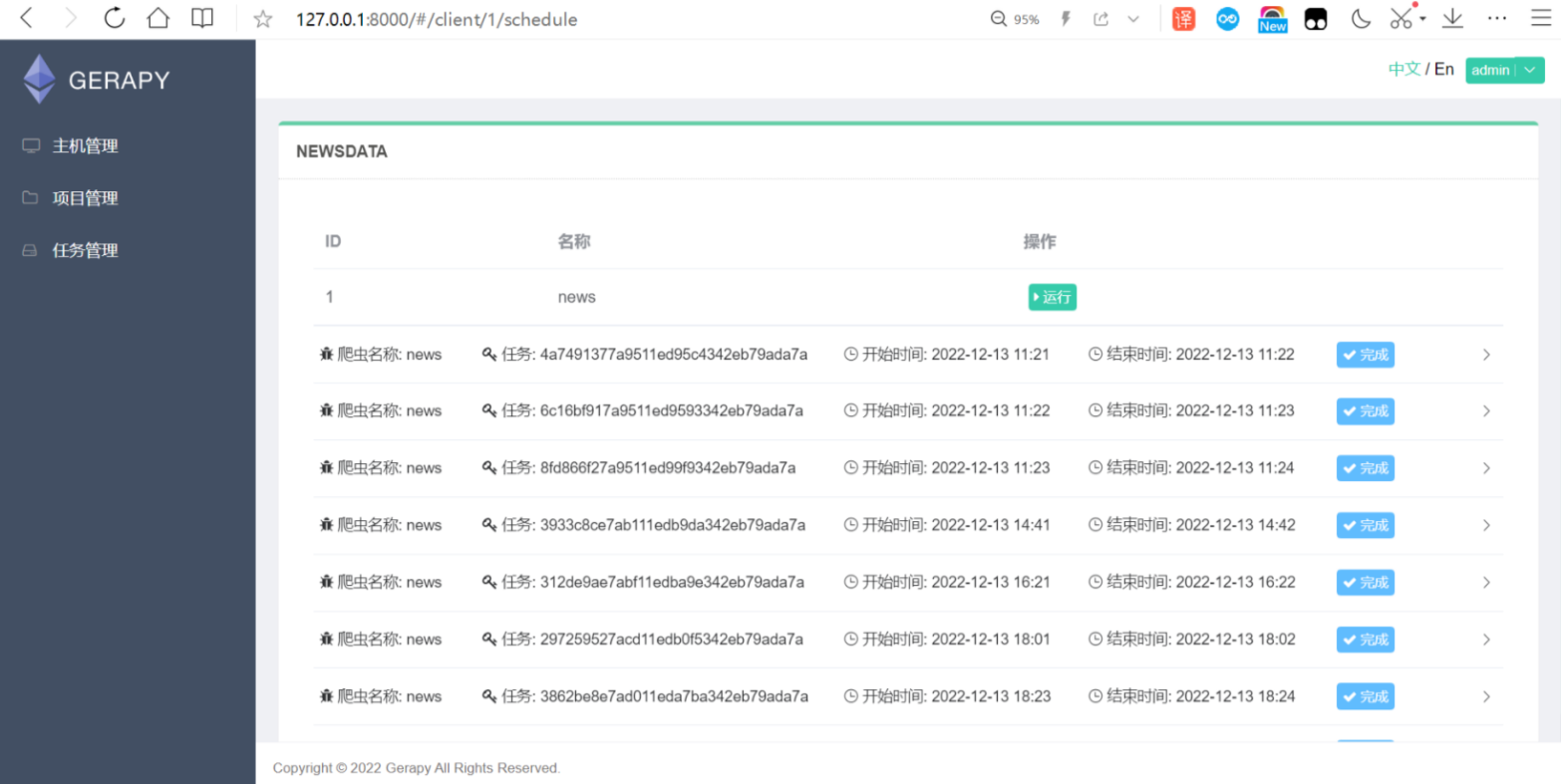
然后等待周期爬取,数据也能导入进来。
遇到的问题:
1 ValueError: Missing scheme in request url
解决办法:这是相对路径和绝对路径的原因,要多进行一步拼接
item["url"] = parse.urljoin(response.url,data[each]["url"])
2 接上条,NameError: name 'parse' is not defined
解决办法:from urllib import parse
3 ZeroDivisionError: division by zero
解决办法:这是没有抓到数据,用自动爬取算法爬取某些网站不可取,需要回网页f12定位
4 在pip install gerapy_auto_extractor时报错
解决办法:去镜像网站下载
pip install gerapy_auto_extractor -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
5 gerapy init初始化显示无法识别gerapy
管理员权限打开cmd卸载重装
Comments NOTHING