


- 平台:modelarts
- 框架:PyTorch
- 算法:yolov7
- 数据储存:obs-browser
前言:什么是机器学习
有监督学习&无监督学习
无监督学习、有监督学习都是机器学习领域内的概念。机器学习是一种模仿人类学习方式,使用数据和算法来逐渐提高准确性的技术。有监督学习是一种从有标记的训练数据中推导出预测函数的机器学习任务,即通过输入和期望出来预测标签。而无监督学习是一种从无标记的训练数据中推断结论的机器学习任务,即在没有给定正确答案的情况下自主学习。这两种学习方式在数据标注方面存在差异,前者需要标注数据,后者不需要。
有监督学习、无监督学习的使用场景
有监督学习常常被应用于分类、回归等任务,例如垃圾邮件过滤、手写数字识别、语音识别和图像分类。在这些任务中,我们通常有已标记的数据作为输入,以学习如何将未标记的数据映射到预定义的类别或输出。无监督学习则常常被应用于聚类、降维等任务,例如客户细分、图像分割和异常检测。在这些任务中,我们没有显式的训练目标,而是通过从数据中发现模式来自动学习模型。
对于疲劳驾驶,我们选择哪种方式
对于简单的疲劳驾驶,比如只用检测是否长时间闭眼,是否打哈欠这种,可以采用基于人脸识别技术的无监督学习方法进行疲劳检测。通过对驾驶员的面部图像进行实时处理和分析,提取出面部特征点及特征指标作为判断依据(例如经典的64点眼睛检测算法),以此来得出驾驶员是否处于疲劳状态。它不需要显式地训练模型,而是通过从数据中发现模式来自动学习模型。相比之下,有监督学习方法则需要大量标记的数据样本来进行训练,这在实践中可能会更加困难和耗费资源。另外,在有监督学习中,由于需要明确的标签信息,如果标签错误或者标签缺失,都可能导致学习效果的不理想。
但是,我们的比赛需要针对驾驶员的多种行为检测,由于需要对特定动作(如打哈欠、闭眼、左顾右盼、打电话等)进行精确的识别和分类,因此适合使用有监督学习方法进行模型训练。在有监督学习中,需要获取大量已经标注好的数据作为训练集,而这些数据包括了输入图像或视频帧以及对应的标签信息。在驾驶员行为检测任务中,可以采用Dlib等库进行人脸检测和关键点定位,进而通过检测到的人脸区域和关键点来提取面部表达特征,然后将这些信息与预设的驾驶员疲劳行为标签进行匹配,最终让模型学习到如何区分不同的驾驶员行为,接下来讲的yolov7算法也是基于有监督学习的一种目标检测算法。
接下来,进入具体的有监督学习算法
1、视频抽帧
在进行抽帧代码前,我们先来学习一些关于视频帧的理论知识
什么是关键帧
先来看看百度的定义
关键帧指构成一段动画中具有决定性作用的帧。在典型的关键帧动画中,关键帧通常是1秒动画的第一帧和最后一帧,如果动作稍微复杂一些,则会在中间位置加上一帧(不等于中间帧)。可以将关键帧看作是动作起始状态、结束状态或者中间状态之一。在制作动画或视频时,通过调整关键帧的位置和属性,可以控制动画或视频的表现形式和效果。关键帧也是计算机动画、游戏制作等领域中常用的概念。
所以关键帧是一个专业术语,它并不是一个根据需求而改变的东西,比如你只想检测是否打电话,打电话的帧是关键帧,但左顾右盼、闭眼等也属于关键帧。
进行关键帧抽取后,会输出若干张图像文件,这些图像文件即为从原始视频中提取出来的关键帧。这些关键帧是视频的核心部分,也是具有决定性作用的帧,可以代表整个视频中的重要内容和特征,并且可以用来表示该视频的摘要或概括。通过对关键帧的处理和分析,可以实现视频分类、检索、压缩等多种应用。
关键帧抽取的原则
- 表示视频主要内容和特征。关键帧应该代表视频中的重要内容和特征,能够在不失真的情况下尽可能地表现出视频的内容和风格。
- 减小数据量和提高检索效率。选择适当数量的关键帧能够大大减小视频数据量并提高检索效率,避免对全部视频帧进行处理而产生的时间和空间开销。
- 保持视觉连贯性。相邻的关键帧之间应该保持一定的视觉连贯性,使得关键帧之间的过渡自然流畅,能够形成连续的画面效果。
- 尽可能覆盖整个视频。选择的关键帧应该能够尽可能地覆盖整个视频,包括视频的不同部分、不同场景和不同角度等,以充分反映视频的多样性和复杂性。
- 根据应用需求进行调整。关键帧的抽取数量和位置必须根据实际应用需求进行调整,例如,可以根据视频的类型、长度、分辨率和相关任务等因素来确定关键帧的数量和抽取方式。
综上所述,关键帧抽取应该在保持核心内容、减小数据量、视觉连贯性、覆盖全局和满足应用需求的基础上进行,以达到最佳的效果。
对140个疲劳驾驶的视频进行关键帧抽取
代码如下
import cv2
import argparse
import json
import os
import numpy as np
import errno
def getInfo(sourcePath):
cap = cv2.VideoCapture(sourcePath)
info = {
"framecount": cap.get(cv2.CAP_PROP_FRAME_COUNT),
"fps": cap.get(cv2.CAP_PROP_FPS),
"width": int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
"heigth": int(cap.get(cv2.CAP_PROP_FRAME_Heigth)),
"codec": int(cap.get(cv2.CAP_PROP_FOURCC))
}
cap.release()
return info
def scale(img, xScale, yScale):
res = cv2.resize(img, None,fx=xScale, fy=yScale, interpolation = cv2.INTER_AREA)
return res
def resize(img, width, heigth):
res = cv2.resize(img, (width, heigth), interpolation=cv2.INTER_AREA)
return res
def extract_cols(image, numCols):
# convert to np.float32 matrix that can be clustered
Z = image.reshape((-1, 3))
Z = np.float32(Z)
# Set parameters for the clustering
max_iter = 20
epsilon = 1.0
K = numCols
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, max_iter, epsilon)
labels = np.array([])
# cluster
compactness, labels, centers = cv2.kmeans(Z, K, labels, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
clusterCounts = []
for idx in range(K):
count = len(Z[np.where(labels == idx)])
clusterCounts.append(count)
rgbCenters = []
for center in centers:
bgr = center.tolist()
bgr.reverse()
rgbCenters.append(bgr)
cols = []
for i in range(K):
iCol = {
"count": clusterCounts[i],
"col": rgbCenters[i]
}
cols.append(iCol)
return cols
def calculateFrameStats(sourcePath, verbose=True, after_frame=0): # 提取相邻帧的差别
cap = cv2.VideoCapture(sourcePath) # 提取视频
data = {
"frame_info": []
}
lastFrame = None
while(cap.isOpened()):
ret, frame = cap.read()
if frame is None:
break
frame_number = cap.get(cv2.CAP_PROP_POS_FRAMES) - 1
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 提取灰度信息
gray = scale(gray, 0.25, 0.25) # 缩放为原来的四分之一
gray = cv2.GaussianBlur(gray, (9, 9), 0.0) # 做高斯模糊
# lastFrame = gray
if frame_number < after_frame:
lastFrame = gray
continue
if lastFrame is not None:
diff = cv2.subtract(gray, lastFrame) # 用当前帧减去上一帧
diffMag = cv2.countNonZero(diff) # 计算两帧灰度值不同的像素点个数
frame_info = {
"frame_number": int(frame_number),
"diff_count": int(diffMag)
}
data["frame_info"].append(frame_info)
if verbose:
cv2.imshow('diff', diff)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Keep a ref to this frame for differencing on the next iteration
lastFrame = gray
cap.release()
cv2.destroyAllWindows()
# compute some states
diff_counts = [fi["diff_count"] for fi in data["frame_info"]]
data["stats"] = {
"num": len(diff_counts),
"min": np.min(diff_counts),
"max": np.max(diff_counts),
"mean": np.mean(diff_counts),
"median": np.median(diff_counts),
"sd": np.std(diff_counts) # 计算所有帧之间, 像素变化个数的标准差
}
greater_than_mean = [fi for fi in data["frame_info"] if fi["diff_count"] > data["stats"]["mean"]]
greater_than_median = [fi for fi in data["frame_info"] if fi["diff_count"] > data["stats"]["median"]]
greater_than_one_sd = [fi for fi in data["frame_info"] if fi["diff_count"] > data["stats"]["sd"] + data["stats"]["mean"]]
greater_than_two_sd = [fi for fi in data["frame_info"] if fi["diff_count"] > (data["stats"]["sd"] * 2) + data["stats"]["mean"]]
greater_than_three_sd = [fi for fi in data["frame_info"] if fi["diff_count"] > (data["stats"]["sd"] * 3) + data["stats"]["mean"]]
# 统计其他信息
data["stats"]["greater_than_mean"] = len(greater_than_mean)
data["stats"]["greater_than_median"] = len(greater_than_median)
data["stats"]["greater_than_one_sd"] = len(greater_than_one_sd)
data["stats"]["greater_than_three_sd"] = len(greater_than_three_sd)
data["stats"]["greater_than_two_sd"] = len(greater_than_two_sd)
return data
def writeImagePyramid(destPath, name, seqNumber, image):
fullPath = os.path.join(destPath, name + "_" + str(seqNumber) + ".png")
cv2.imwrite(fullPath, image)
def detectScenes(sourcePath, destPath, data, name, verbose=False):
destDir = os.path.join(destPath, "images")
# TODO make sd multiplier externally configurable
# diff_threshold = (data["stats"]["sd"] * 1.85) + data["stats"]["mean"]
diff_threshold = (data["stats"]["sd"] * 2.05) + (data["stats"]["mean"])
cap = cv2.VideoCapture(sourcePath)
for index, fi in enumerate(data["frame_info"]):
if fi["diff_count"] < diff_threshold:
continue
cap.set(cv2.CAP_PROP_POS_FRAMES, fi["frame_number"])
ret, frame = cap.read()
# extract dominant color
small = resize(frame, 100, 100)
cols = extract_cols(small, 5)
data["frame_info"][index]["dominant_cols"] = cols
if frame is not None:
# file_name = sourcePath.split('.')[0]
writeImagePyramid(destDir, name, fi["frame_number"], frame)
if verbose:
cv2.imshow('extract', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
return data
def makeOutputDirs(path):
try:
os.makedirs(os.path.join(path, "metadata"))
os.makedirs(os.path.join(path, "images"))
except OSError as exc: # Python >2.5
if exc.errno == errno.EEXIST and os.path.isdir(path):
pass
else:
raise
getInfo(sourcePath):用于获取视频的信息,包括帧数、帧率、宽度、高度和编码方式。scale(img, xScale, yScale):用于对图片进行缩放。resize(img, width, height):用于对图片进行裁剪。extract_cols(image, numCols):用于提取图片中的主要颜色。calculateFrameStats(sourcePath, verbose=True, after_frame=0):该函数用于计算视频中每一帧相邻帧灰度值不同的像素点个数,包括统计每一帧的差异信息和计算全部帧的标准差等统计数据。writeImagePyramid(destPath, name, seqNumber, image):该函数将提取出的场景图像保存到指定路径。detectScenes(sourcePath, destPath, data, name, verbose=False):该函数用于检测视频中的场景变换,并提取变换后的每一帧图像的主要颜色,并调用writeImagePyramid()将处理后的图像保存到指定路径。makeOutputDirs(path):创建输出文件夹。
前两个函数用于图像处理中的基本操作,后面的函数则是针对视频处理问题的实现。其中,detectScenes()函数是整个脚本的核心,该函数可以检测视频中的场景变化,并提取主要颜色信息,实现了对视频的特征分析。在处理过程中,还使用了OpenCV库中的一些功能函数,如聚类分析和高斯模糊等。
import moxing as mox
mox.file.copy_parallel('obs://obs-aigallery-zc/clf/dataset/Fatigue_driving_detection_video','Fatigue_driving_detection_video')
这段代码是复制obs公共桶里提供的142段疲劳驾驶的视频到notebook本地Fatigue_driving_detection_video文件夹下,如果没有这个文件夹会创建这个文件夹,注意moxing这个库是华为云端特有的,本地用不了,如果想在本地运行请手动下载到本地文件夹
然后我们开始抽帧,这可能需要几分钟
dest = "key frame" # 抽取图像保存路径
makeOutputDirs(dest)
test_path ='Fatigue_driving_detection_video' # 这个是上面复制到notebook本地的视频路径
filenames = os.listdir(test_path)
count = 0
for filename in filenames:
source = os.path.join(test_path, filename)
name = filename.split('.')[0]
data = calculateFrameStats(source, False, 0)
data = detectScenes(source, dest, data, name, False)
keyframeInfo = [frame_info for frame_info in data["frame_info"] if "dominant_cols" in frame_info]
# Write out the results
data_fp = os.path.join(dest, "metadata", name + "-meta.txt")
with open(data_fp, 'w') as f:
f.write(str(data))
keyframe_info_fp = os.path.join(dest, "metadata", name + "-keyframe-meta.txt")
with open(keyframe_info_fp, 'w') as f:
f.write(str(keyframeInfo))
print(count)运行完成后notebook本地会出现一个key frame文件夹,里面都是抽出来的关键帧图片
然后我们将这个文件夹下的image文件里的所有图片复制到自己的obs桶里,同样的,这个moxing库只能在华为云的notebook上使用,无法在本地使用
import moxing as mox
mox.file.copy('/home/ma-user/work/key frame/images', 'obs://testcalling/data/')
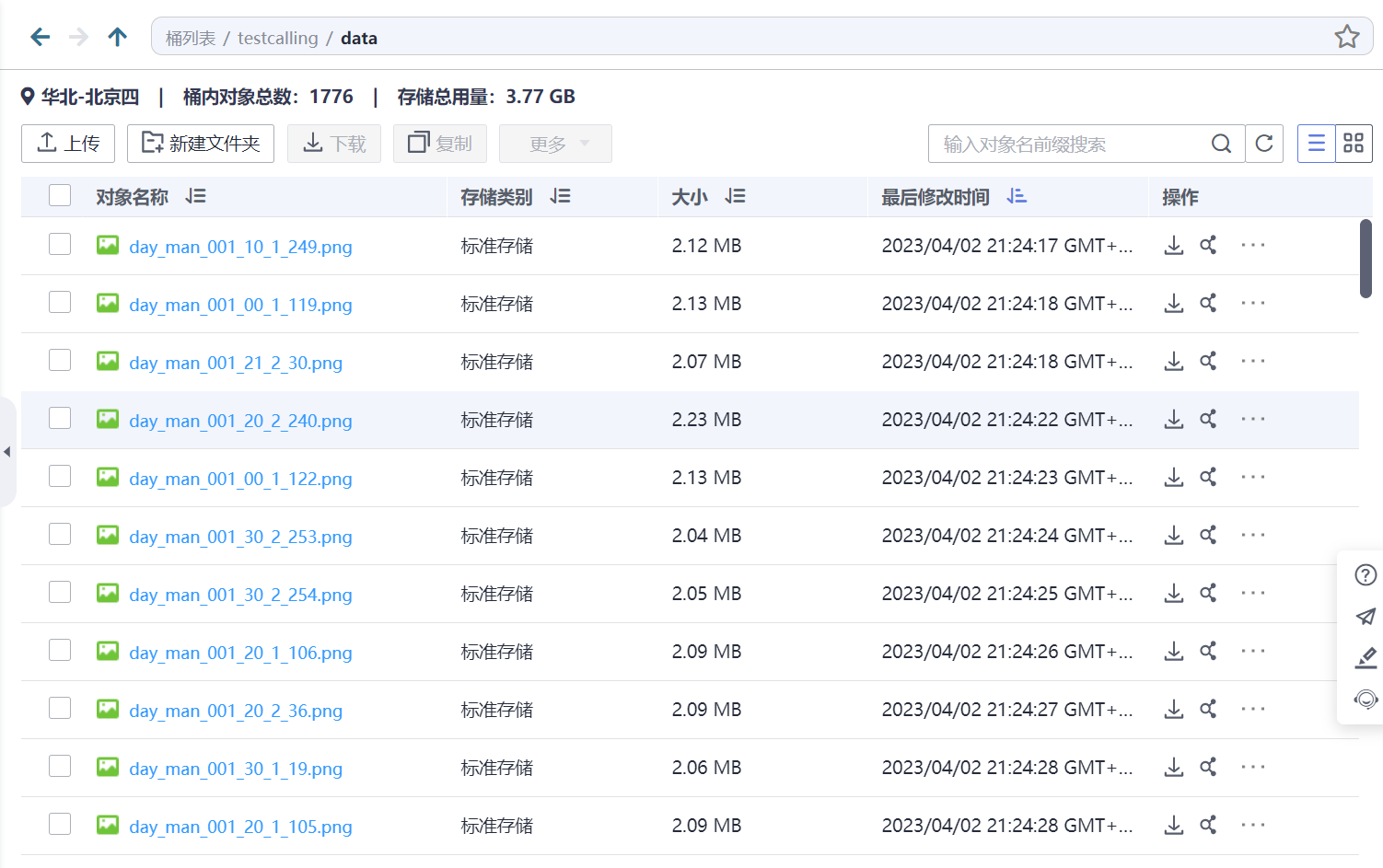
2、图像标注
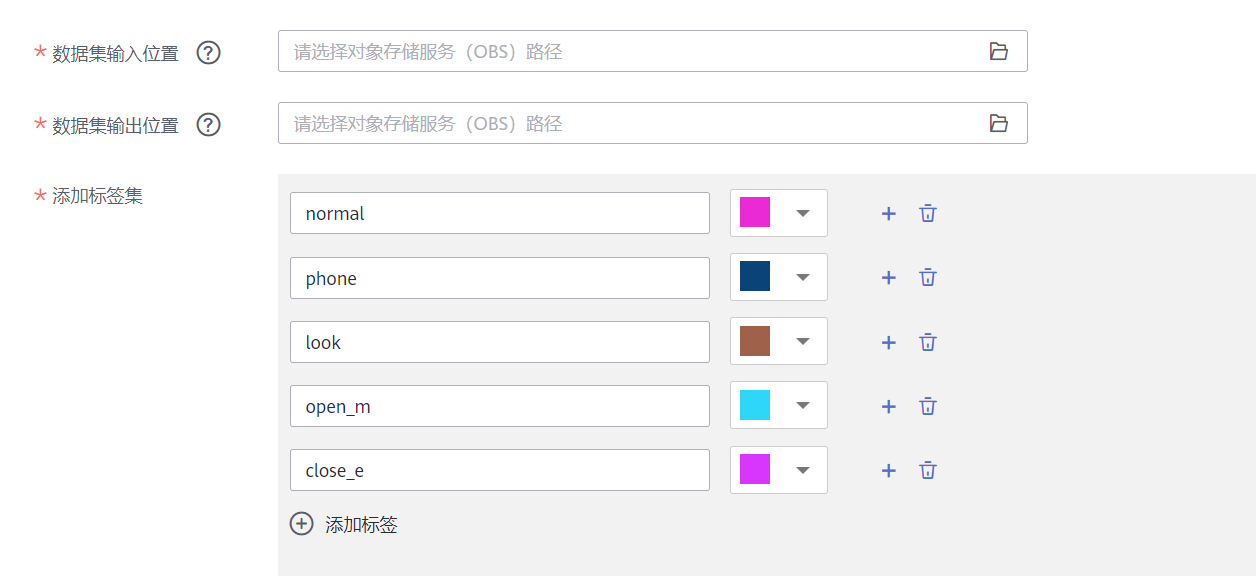
我们可以直接在modelarts上标注
在modelarts上新建数据集,名称随便起,选择标注场景选图片,类型选物体检测
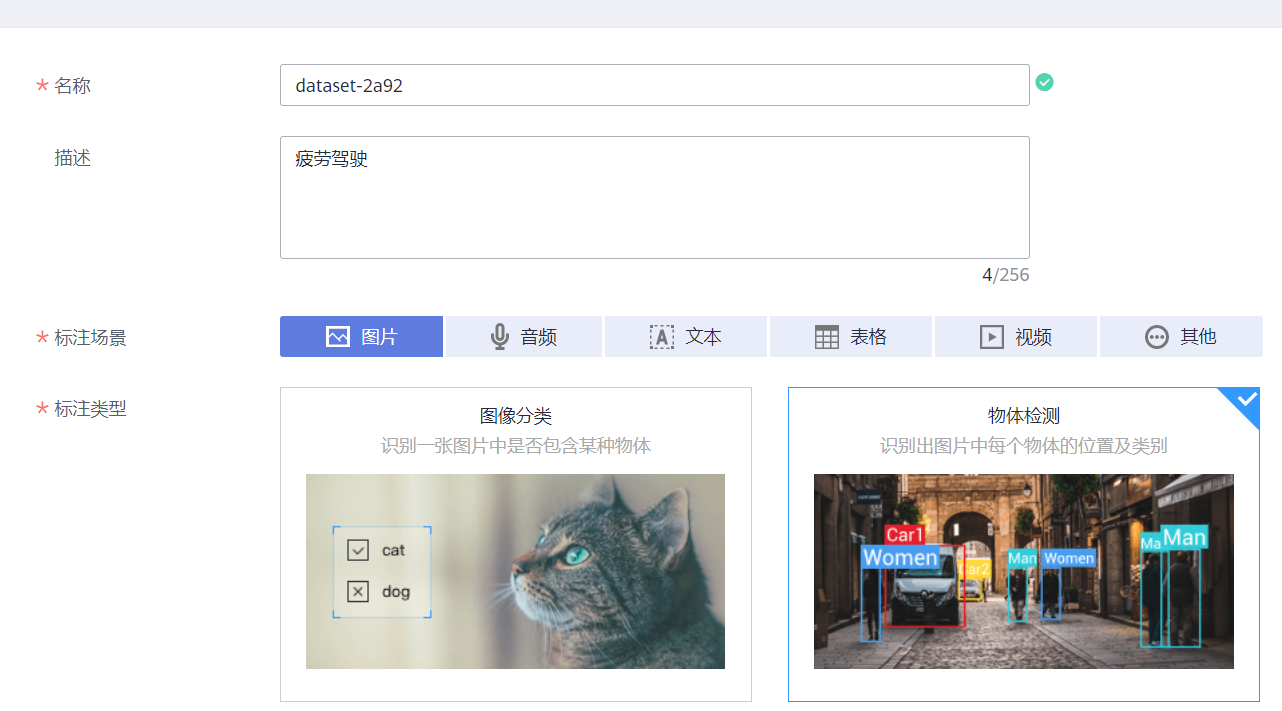
数据输入选择上面导入到obs的那个文件夹,输出选另一个文件夹,然后把比赛要求的五种标签写好。
normal:正常
phone:打电话
look:左顾右盼
open_m:打哈欠
close_e:闭眼
然后开启团队标注,将所有成员都设置为标注员labeler
开始标注,在标注了百分之六十左右的时候可以使用智能标注,然后检查智能标注的结果并改正
将标注完成的文件夹导出至另外一个obs文件夹
将这个文件夹拷贝到modelarts notebook本地,这里也要用到moxing库
因为训练所需为TXT标注格式、标注转换代码如下
'***转换xml标注文件为txt格式,无法直接运行***'
import copy
from lxml.etree import Element, SubElement, tostring, ElementTree
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
classes = ["face", "phone"] # 类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('yolov7/datasets/Fatigue_driving_detection/txt_labels/%s.txt' % (image_id), 'w') # 生成txt格式文件, 保存在yolov7训练所需的数据集路径中
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
print(cls)
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = './label_xml/' # xml_path应该是上述步骤OBS桶文件夹C中的所有文件,记得拷贝过来
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
if img_xml.split('.')[1] == 'xml':
convert_annotation(label_name)划分训练集、验证集、测试集,代码如下
'***转换xml标注文件为txt格式,无法直接运行***'
import moxing as mox
from random import sample
file_list = mox.file.list_directory( xml_path) # xml_path中是上述步骤OBS桶文件夹C中的所有文件,记得拷贝到本地
print(len(file_list))
val_file_list = sample(file_list, 300) # 选择了300张做测试集
line = ''
for i in val_file_list:
if i.endswith('.png') :
line += 'datasets/Fatigue_driving_detection/images/'+i+'\n' # datasets/Fatigue_driving_detection/images/ 是yolov7训练使用的
with open('yolov7/datasets/Fatigue_driving_detection/val.txt', 'w+') as f:
f.writelines(line)
test_file_list = sample(file_list, 300)
line = ''
for i in test_file_list:
if i.endswith('.png'):
line += 'datasets/Fatigue_driving_detection/images/'+i+'\n'
with open('yolov7/datasets/Fatigue_driving_detection/test.txt', 'w+') as f:
f.writelines(line)
line = ''
for i in file_list:
if i not in val_file_list and i not in test_file_list:
if i.endswith('.png') :
line += 'datasets/Fatigue_driving_detection/images/'+i+'\n'
with open('yolov7/datasets/Fatigue_driving_detection/train.txt', 'w+') as f:
f.writelines(line)3、使用yolov7训练目标检测模型
拉取写完的代码
同样用了华为云的moxing库,复制obs桶里的文件到notebook本地,文件夹名为yolov7
import moxing as mox
mox.file.copy_parallel('obs://obs-aigallery-zc/clf/code/yolov7', 'yolov7')
配置环境
"!" 符号在 Jupyter Notebook 或者 Google Colab 中被称为“魔法命令”。这个符号告诉 Notebook 内核,后面的命令应该在系统 shell 中运行,而不是在 Python 中运行。因此,在 Jupyter Notebook 或者 Google Colab 中,如果你想在 shell 中运行 pip 命令,就必须加上 "!" 符号,否则会被解释为 Python 语句,导致报错。
!pip install -r requirements.txtrequirements.txt里的内容如下
# Usage: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.1
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0,!=1.12.0
torchvision>=0.8.1,!=0.13.0
tqdm>=4.41.0
protobuf<4.21.3
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
onnx>=1.9.0 # ONNX export
onnx-simplifier>=0.3.6 # ONNX simplifier
onnxruntime
# Extras --------------------------------------
ipython # interactive notebook
psutil # system utilization
thop # FLOPs computation
albumentations>=1.0.3
pycocotools>=2.0 # COCO mAP
roboflow
这个txt文件列出了所有需要安装的 Python 库及其版本。这些库包括基本的科学计算库(如 numpy, scipy),深度学习库(如 PyTorch),图像处理库(如 OpenCV),日志记录库(如 Tensorboard)等等。此外,该文件还包括一些额外的库,如系统利用率计算库(如 psutil)和数据增强库(如 albumentations)。
查看数据集
import random
import cv2
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
with open("datasets/Fatigue_driving_detection/train.txt", "r") as f:
img_paths = f.readlines()
img_paths = random.sample(img_paths, 8)
img_lists = []
for img_path in img_paths:
img_path = img_path.strip()
img = cv2.imread(img_path)
h, w, _ = img.shape
tl = round(0.002 * (h + w) / 2) + 1
color = [random.randint(0, 255) for _ in range(3)]
if img_path.endswith('.png'):
with open(img_path.replace("images", "txt_labels").replace(".png", ".txt")) as f:
labels = f.readlines()
if img_path.endswith('.jpeg'):
with open(img_path.replace("images", "txt_labels").replace(".jpeg", ".txt")) as f:
labels = f.readlines()
for label in labels:
l, x, y, wc, hc = [float(x) for x in label.strip().split()]
cv2.rectangle(img, (int((x - wc / 2) * w), int((y - hc / 2) * h)), (int((x + wc / 2) * w), int((y + hc / 2) * h)),
color, thickness=tl, lineType=cv2.LINE_AA)
img_lists.append(cv2.resize(img, (1280, 720)))
image = np.concatenate([np.concatenate(img_lists[:4], axis=1), np.concatenate(img_lists[4:], axis=1)], axis=0)
plt.rcParams["figure.figsize"] = (20, 10)
plt.imshow(image[:,:,::-1])
plt.show()这段代码用于读取给定路径下的图像及其对应标注,并随机选择其中 8 张图像进行可视化。具体来说,
- 打开指定路径下的一个名为 train.txt 的文本文件,读取其中的所有行并保存到名为 img_paths 的列表中。
- 从 img_paths 中随机选择 8 个元素,并将它们保存到名为 img_lists 的列表中。
- 对于每个被选择的图像,打开其对应的矩形框标注文件(就是images/txt_labels里的文件,里面的0表示脸,1表示电话,四个坐标表示矩形框四个角的坐标),并在图像上画出相应的矩形框。
- 将处理后的图像 resize 到 (1280, 720),保存到 img_lists 中。
- 最后,将 img_lists 中的 8 张图像按照 2×4 的布局方式拼接起来,使用 matplotlib 的 imshow 函数显示出来。
最终的效果是展示了 8 张随机选取的图像及其对应的矩形框。

在训练过程中使用的数据增强策略可以在使用的训练配置文件中设置,我们使用的是yolov7/data/hyp.scratch.tiny.yaml:内容如下
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.05 # image mixup (probability)
copy_paste: 0.0 # image copy paste (probability)
paste_in: 0.05 # image copy paste (probability), use 0 for faster training
loss_ota: 1 # use ComputeLossOTA, use 0 for faster training这是一个 YOLOv5 的训练配置文件(.yaml 文件),该文件中包含了一些模型训练相关的参数设置。下面对其中的各个参数进行简要介绍:
- lr0: 初始学习率,即模型开始训练时的学习率大小,对于 SGD 优化器来说通常取 1E-2,而对于 Adam 优化器来说通常取 1E-3。
- lrf: OneCycleLR 学习率调度器中的最终学习率,通常取值为 lr0 * lrf。
- momentum: 随机梯度下降(SGD)优化器的动量系数,或者 Adam 优化器的 beta1 系数。
- weight_decay: 优化器中的权重衰减系数,用于防止过拟合。
- warmup_epochs: 模型训练中的预热阶段(warm-up stage)的训练轮数,预热阶段通常会使用较小的学习率和较低的动量系数来加快模型的收敛速度。
- warmup_momentum: 预热阶段的初始动量系数。
- warmup_bias_lr: 预热阶段的初始偏置项(bias)学习率。
- box、cls 和 obj:YOLOv5 检测网络中三个损失函数的权重系数,分别是边界框损失、类别损失和目标检测损失。
- cls_pw 和 obj_pw:类别损失和目标检测损失中的二分类交叉熵损失函数中正样本的权重系数。
- iou_t 和 anchor_t:目标检测时使用的 IoU 阈值和 anchor boxes 的阈值(即与 anchor boxes IoU 值大于该阈值的目标被认为是该 anchor box 所对应的目标)。
- fl_gamma:Focal Loss 中的 gamma 系数,用于调整难易样本的权重比例。
- hsv_h、hsv_s 和 hsv_v:HSV 颜色空间中图像色调、饱和度和明度的增强程度。
- degrees、translate、scale、shear 和 perspective:图像旋转、平移、缩放、错切和透视变换的程度。
- flipud 和 fliplr:上下和左右翻转的概率。
- mosaic:图像马赛克化的概率,马赛克化可以增加数据的多样性和模型的鲁棒性。
- mixup:图像混合的概率,混合可以增加数据的多样性和模型的泛化能力。
- copy_paste 和 paste_in:图像复制黏贴的概率和黏贴位置的大小,用于生成新的训练样本。
- loss_ota:使用 ComputeLossOTA 来计算损失函数,这可以增加模型的准确度,但需要更长的训练时间。
查看数据增强后的数据:
import yaml
import argparse
import torch
from utils.datasets import create_dataloader
from utils.general import colorstr
from utils.plots import plot_images
%matplotlib inline
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default="data/coco.yaml", help='*.data path')
parser.add_argument('--hyp', type=str, default="data/hyp.scratch.tiny.yaml")
parser.add_argument('--batch-size', type=int, default=16, help='size of each image batch')
parser.add_argument('--gs', type=int, default=32)
parser.add_argument('--img-size', type=int, default=320, help='inference size (pixels)')
parser.add_argument('--task', default='train', help='train, val, test, speed or study')
parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
opt = parser.parse_args(args=['--task', 'train'])
print(opt)
with open(opt.data) as f:
data = yaml.load(f, Loader=yaml.SafeLoader)
with open(opt.hyp) as f:
hyp = yaml.load(f, Loader=yaml.SafeLoader)
dataloader = create_dataloader(data[opt.task], opt.img_size, opt.batch_size, opt.gs, opt, hyp=hyp, augment=True, pad=0.5, rect=True, prefix=colorstr(f'{opt.task}: '))[0]
for img, targets, paths, shapes in dataloader:
nb, _, height, width = img.shape
targets[:, 2:] *= torch.Tensor([width, height, width, height])
result = plot_images(img, targets)
break
plt.rcParams["figure.figsize"] = (20, 10)
plt.imshow(result)
plt.show()
训练模型
check anchor
yolov7是anchor base的方法,utils/autoanchor中提供了计算anchor的函数:
查看模型配置文件
配置文件是cfg/lite/yolov7-tiny.yaml,内容如下
nc: 2 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [ 18,17, 20,25, 27,59] # P3/8
- [ 51,42, 45,88, 118,73] # P4/16
- [ 86,181, 133,259, 206,173] # P5/32
backbone:
# [from, number, module, args]
[ [ -1, 1, CBH, [ 32, 3, 2 ] ], # 0-P2/4
[ -1, 1, LC_Block, [ 64, 2, 3, False ] ], # 1-P3/8
[ -1, 1, LC_Block, [ 64, 1, 3, False ] ], # 2-P4/16
[ -1, 1, LC_Block, [ 128, 2, 3, False ] ], # 3
[ -1, 1, LC_Block, [ 128, 1, 3, False ] ], # 4-P5/32
[ -1, 1, LC_Block, [ 128, 1, 3, False ] ], # 5
[ -1, 1, LC_Block, [ 128, 1, 3, False ] ], # 6
[ -1, 1, LC_Block, [ 256, 2, 3, False ] ], # 7-P5/32
[ -1, 1, LC_Block, [ 256, 1, 5, False ] ],
[ -1, 1, LC_Block, [ 256, 1, 5, False ] ],
[ -1, 1, LC_Block, [ 256, 1, 5, False ] ], # 10-P5/32
[ -1, 1, LC_Block, [ 256, 1, 5, False ] ],
[ -1, 1, LC_Block, [ 256, 1, 5, False ] ], # 12-P5/32
[ -1, 1, LC_Block, [ 512, 2, 5, True ] ],
[ -1, 1, LC_Block, [ 512, 1, 5, True ] ], # 14-P5/32
[ -1, 1, LC_Block, [ 512, 1, 5, True ] ], # 15
[ -1, 1, LC_Block, [ 512, 1, 5, True ] ], # 16
[ -1, 1, Dense, [ 512, 1, 0.2 ] ],
]
head:
[ [-1, 1, Conv, [256, 1, 1]], # 18
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 12 ], 1, Concat, [ 1 ] ], # cat backbone P4
[-1, 1, C3, [256, False]], # 21
[-1, 1, Conv, [128, 1, 1]], # 22
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ],
[ [ -1, 6 ], 1, Concat, [ 1 ] ], # cat backbone P3
[-1, 1, C3, [128, False]], # 25 (P3/8-small)
[ -1, 1, LC_Block, [ 128, 2, 5, True ] ], # 26
[ [ -1, 22 ], 1, Concat, [ 1 ] ], # cat head P4
[-1, 1, C3, [256, False]], # 28 (P4/16-medium)
[ -1, 1, LC_Block, [ 256, 2, 5, True ] ], # 29
[ [ -1, 18 ], 1, Concat, [ 1 ] ], # cat head P5
[-1, 1, C3, [512, False]], # 31 (P5/32-large)
[ [ 25, 28, 31 ], 1, IDetect, [ nc, anchors ] ], # Detect(P3, P4, P5)
]
这段代码是模型结构的配置文件,采用了 yaml 格式。该文件描述了目标检测模型的具体结构,包括输入图像的尺寸、锚点坐标、网络骨干模块(backbone)、检测头模块(head)等内容。
具体来说,该文件包含以下部分:
- number of classes(类别数目):这里设定为 2。
- depth_multiple(深度倍数):用于控制模型的深度,默认为 1.0。
- width_multiple(宽度倍数):用于控制模型的通道数,默认为 1.0。
- 锚点(anchors):用于确定目标检测中的 Anchor Boxes 的坐标和尺寸。这里共定义了三个 anchor,分别对应输入图像经过不同程度下采样后的特征层。
- 网络骨干模块(backbone):指包括多个卷积层、残差块、轻量化块等的网络前向传播过程。这里采用了 YOLOv5 中提出的 LC_Block(Lightweight Convolution Block)作为基本单元,并依次在不同的特征层上进行卷积和下采样操作。
- 检测头模块(head):指用于将特征层转换成目标框的分类结果和坐标信息的网络结构。这里采用了不同大小的卷积核对特征图进行处理,再将结果与对应的特征层融合,得到最终的检测结果。
总之,该文件是目标检测模型的关键配置文件,决定了模型在具体任务中的表现和性能。通过调整其中的参数和结构,可以有效地提高模型的精度、召回率和泛化性能。
然后我们可以构建模型,查看模型flops与params参数:
from models.yolo import Model
import thop
model = Model("cfg/lite/yolov7-tiny.yaml", ch=3, nc=2, anchors=hyp.get('anchors'))
inputs = torch.randn(1, 3, 288, 352)
flops, params = thop.profile(model, inputs=(inputs,))
print('flops:', flops / 900000000 * 2)
print('params:', params)
结果是
flops: 2.3034040888888887
params: 4381535.0
微调模型
提供的预训练模型已经基于数据训练过248轮,我们在预训练模型上训练5个轮:
!python train.py --model_name yolov7-tiny --batch-size 32 --epochs 5 --name c-320 --multi-scale --sync-bn --device 0这段代码运行了 train.py 脚本,并传递参数,用于训练目标检测模型。
参数:
- model_name:指定目标检测模型的名称,这里为 yolov7-tiny。
- batch-size:指定每次训练时的批量大小,这里为 32。
- epochs:指定训练轮数,这里为 5。
- name:指定训练任务的名称,这里为 c-320。
- multi-scale:启用多尺度训练模式。
- sync-bn:启用多卡同步 BatchNorm。
- device:指定在哪个设备(GPU)上进行训练,这里为第 0 个 GPU。
在训练过程中,训练数据会被输入到模型中进行前向传播和反向传播,通过优化损失函数不断调整模型参数。训练结束后,可以通过保存的权重文件加载训练好的模型进行测试或预测。通过修改不同的参数可以实现不同的训练策略和效果。
查看结果
训练结束,可以看到outputs文件夹下保存了训练结果,加载best.pt查看推理结果:
!python detect.py --weights outputs/c-32029/weights/best.pt --source images --img-size 640 --device 0 --name c-32029 --no-trace结果为
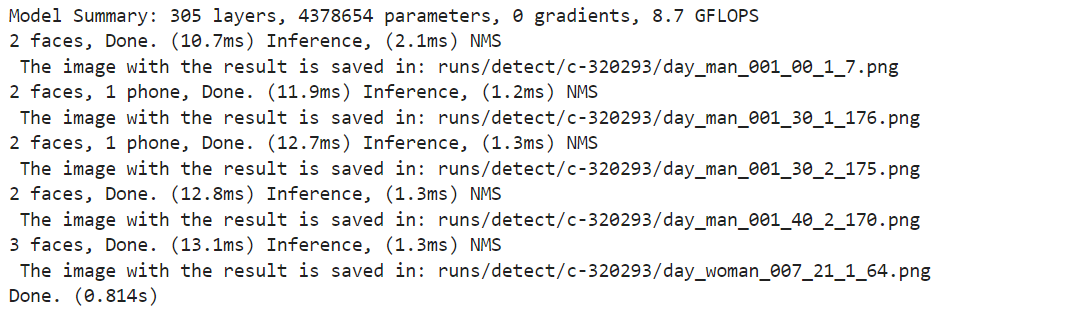
可以看到结果保存在runs/detect/c-320293,查看
import cv2
from matplotlib import pyplot as plt
%matplotlib inline
img = cv2.imread("runs/detect/c-320293/day_man_001_30_1_176.png")
plt.imshow(img[:,:,::-1])
plt.show()
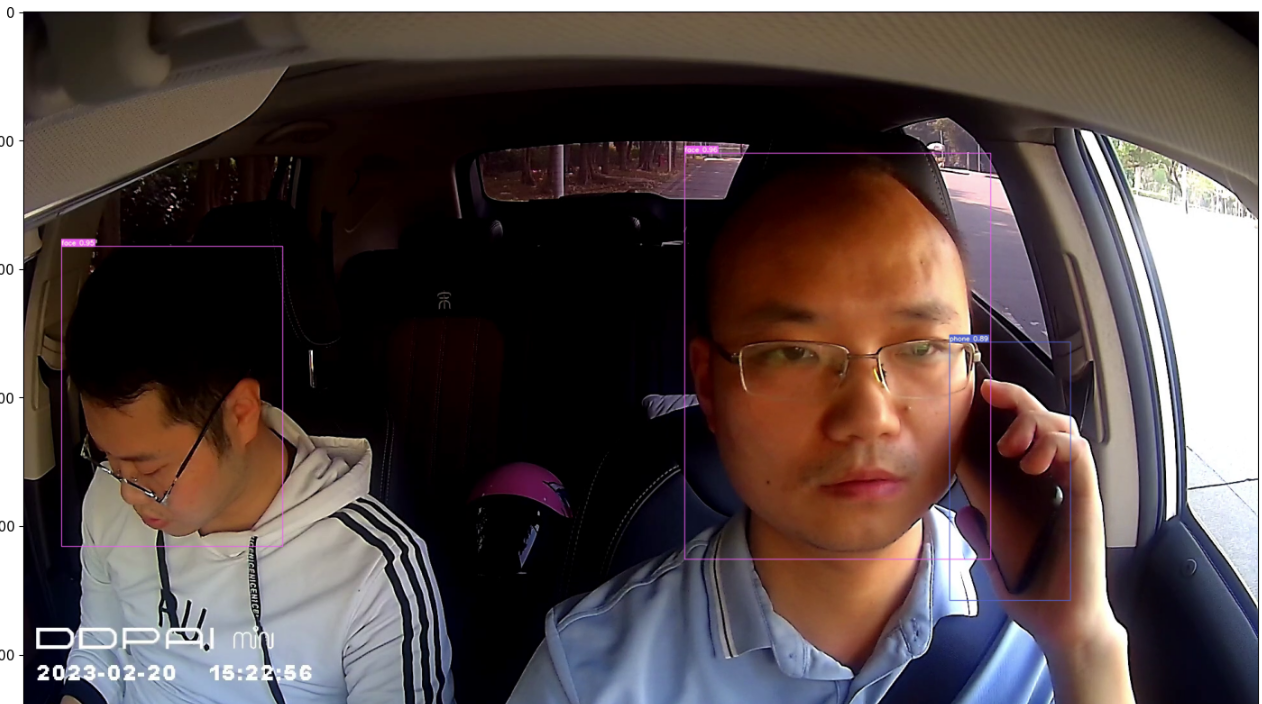
4、结合视频实现疲劳/分神驾驶检测
第三步得到的是尽量精确的识别出标签的模型包(.pt文件),这一步要结合模型包检测疲劳驾驶
如果第3步训练得到了更好的目标检测模型,将best.pt拷贝替换即可
拷贝提供的baseline 模型包到本地
import moxing as mox
mox.file.copy_parallel('obs://obs-aigallery-zc/clf/model/video_classification','video_classification')推理代码
# 推理代码 展示
from PIL import Image
import copy
import sys
import traceback
import os
import numpy as np
import time
import cv2
from input_reader import InputReader
from tracker import Tracker
from EAR import eye_aspect_ratio
from MAR import mouth_aspect_ratio
from models.experimental import attempt_load
from utils1.general import check_img_size
from tempfile import NamedTemporaryFile
from utils1.torch_utils import TracedModel
from detect import detect
from model_service.pytorch_model_service import PTServingBaseService
class fatigue_driving_detection(PTServingBaseService):
def __init__(self, model_name, model_path):
# these three parameters are no need to modify
self.model_name = model_name
self.model_path = model_path
self.capture = 'test.mp4'
self.width = 1920
self.height = 1080
self.fps = 30
self.first = True
self.standard_pose = [180, 40, 80]
self.look_around_frame = 0
self.eyes_closed_frame = 0
self.mouth_open_frame = 0
self.use_phone_frame = 0
# lStart, lEnd) = (42, 48)
self.lStart = 42
self.lEnd = 48
# (rStart, rEnd) = (36, 42)
self.rStart = 36
self.rEnd = 42
# (mStart, mEnd) = (49, 66)
self.mStart = 49
self.mEnd = 66
self.EYE_AR_THRESH = 0.2
self.MOUTH_AR_THRESH = 0.6
self.frame_3s = self.fps * 3
self.face_detect = 0
self.weights = "best.pt"
self.imgsz = 640
self.device = 'cpu' # 大赛后台使用CPU判分
model = attempt_load(model_path, map_location=self.device)
self.stride = int(model.stride.max())
self.imgsz = check_img_size(self.imgsz, s=self.stride)
self.model = TracedModel(model, self.device, self.imgsz)
self.need_reinit = 0
self.failures = 0
self.tracker = Tracker(self.width, self.height, threshold=None, max_threads=4, max_faces=4,
discard_after=10, scan_every=3, silent=True, model_type=3,
model_dir=None, no_gaze=False, detection_threshold=0.6,
use_retinaface=0, max_feature_updates=900,
static_model=True, try_hard=False)
# self.temp = NamedTemporaryFile(delete=False) # 用来存储视频的临时文件
def _preprocess(self, data):
# preprocessed_data = {}
for k, v in data.items():
for file_name, file_content in v.items():
try:
try:
with open(self.capture, 'wb') as f:
file_content_bytes = file_content.read()
f.write(file_content_bytes)
except Exception:
return {"message": "There was an error loading the file"}
# self.capture = self.temp.name # Pass temp.name to VideoCapture()
except Exception:
return {"message": "There was an error processing the file"}
return 'ok'
def _inference(self, data):
"""
model inference function
Here are a inference example of resnet, if you use another model, please modify this function
"""
print(data)
result = {"result": {"category": 0, "duration": 6000}}
self.input_reader = InputReader(self.capture, 0, self.width, self.height, self.fps)
source_name = self.input_reader.name
now = time.time()
while self.input_reader.is_open():
if not self.input_reader.is_open() or self.need_reinit == 1:
self.input_reader = InputReader(self.capture, 0, self.width, self.height, self.fps, use_dshowcapture=False, dcap=None)
if self.input_reader.name != source_name:
print(f"Failed to reinitialize camera and got {self.input_reader.name} instead of {source_name}.")
# sys.exit(1)
self.need_reinit = 2
time.sleep(0.02)
continue
if not self.input_reader.is_ready():
time.sleep(0.02)
continue
ret, frame = self.input_reader.read()
self.need_reinit = 0
try:
if frame is not None:
# 剪裁主驾驶位
frame = frame[:, 600:1920, :]
# 检测驾驶员是否接打电话 以及低头的人脸
bbox = detect(self.model, frame, self.stride, self.imgsz)
# print(results)
for box in bbox:
if box[0] == 0:
self.face_detect = 1
if box[0] == 1:
self.use_phone_frame += 1
# 检测驾驶员是否张嘴、闭眼、转头
faces = self.tracker.predict(frame)
if len(faces) > 0:
face_num = 0
max_x = 0
for face_num_index, f in enumerate(faces):
if max_x <= f.bbox[3]:
face_num = face_num_index
max_x = f.bbox[3]
f = faces[face_num]
f = copy.copy(f)
# 检测是否转头
if np.abs(self.standard_pose[0] - f.euler[0]) >= 45 or np.abs(self.standard_pose[1] - f.euler[1]) >= 45 or \
np.abs(self.standard_pose[2] - f.euler[2]) >= 45:
self.look_around_frame += 1
else:
self.look_around_frame = 0
# 检测是否闭眼
leftEye = f.lms[self.lStart:self.lEnd]
rightEye = f.lms[self.rStart:self.rEnd]
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
# average the eye aspect ratio together for both eyes
ear = (leftEAR + rightEAR) / 2.0
if ear < self.EYE_AR_THRESH:
self.eyes_closed_frame += 1
else:
self.eyes_closed_frame = 0
# print(ear, eyes_closed_frame)
# 检测是否张嘴
mar = mouth_aspect_ratio(f.lms)
if mar > self.MOUTH_AR_THRESH:
self.mouth_open_frame += 1
else:
if self.face_detect:
self.look_around_frame += 1
self.face_detect = 0
# print(self.look_around_frame)
if self.use_phone_frame >= self.frame_3s:
result['result']['category'] = 3
break
elif self.look_around_frame >= self.frame_3s:
result['result']['category'] = 4
break
elif self.mouth_open_frame >= self.frame_3s:
result['result']['category'] = 2
break
elif self.eyes_closed_frame >= self.frame_3s:
result['result']['category'] = 1
break
else:
result['result']['category'] = 0
self.failures = 0
else:
break
except Exception as e:
if e.__class__ == KeyboardInterrupt:
print("Quitting")
break
traceback.print_exc()
self.failures += 1
if self.failures > 30: # 失败超过30次就默认返回
break
del frame
final_time = time.time()
duration = int(np.round((final_time - now) * 1000))
result['result']['duration'] = duration
return result
def _postprocess(self, data):
# os.remove(self.temp.name)
return data这段代码实现的是一个疲劳驾驶检测模型的推理服务,主要用于输入视频流并进行处理,输出疲劳驾驶行为的分类结果和处理时间。
该服务使用了 OpenCV 库和 PyTorch 库,并调用了 detect.py 和 tracker.py 两个文件中的函数进行目标检测和人脸跟踪。在推理过程中,该服务首先从视频流中读取数据帧,然后剪裁出驾驶员的区域,并对该区域进行目标检测和人脸跟踪,以检测驾驶员的疲劳驾驶行为。具体来说,该服务会检测驾驶员是否接打电话、低头、闭眼、张嘴、转头等行为,并根据检测结果将其归为不同的分类。分类结果通过字典形式返回给用户,并包括分类(0或1)和处理时间。最后返回处理后的结果。
然后将模型导入到modelarts中,这里使用了ModelArts的SDK,也可以在AI应用那里手动导入
from modelarts.session import Session
from modelarts.model import Model
from modelarts.config.model_config import TransformerConfig,Params
!pip install json5
import json5
import re
import traceback
import random
try:
session = Session()
config_path = 'video_classification/model/config.json'
if mox.file.exists(config_path): # 判断一下是否存在配置文件,如果没有则不能导入模型
model_location = 'video_classification/model'
model_name = "video_classification"
load_dict = json5.loads(mox.file.read(config_path))
model_type = load_dict['model_type']
re_name = '_'+str(random.randint(0,1000))
model_name += re_name
print("正在导入模型,模型名称:", model_name)
model_instance = Model(
session,
model_name=model_name, # 模型名称
model_version="1.0.0", # 模型版本
source_location_type='LOCAL_SOURCE',
source_location=model_location, # 模型文件路径
model_type=model_type, # 模型类型
)
print("所有模型导入完成")
except Exception as e:
print("发生了一些问题,请看下面的报错信息:")
traceback.print_exc()
print("模型导入失败")导入完成后,modelarts的AI应用里会出现导入后的AI应用
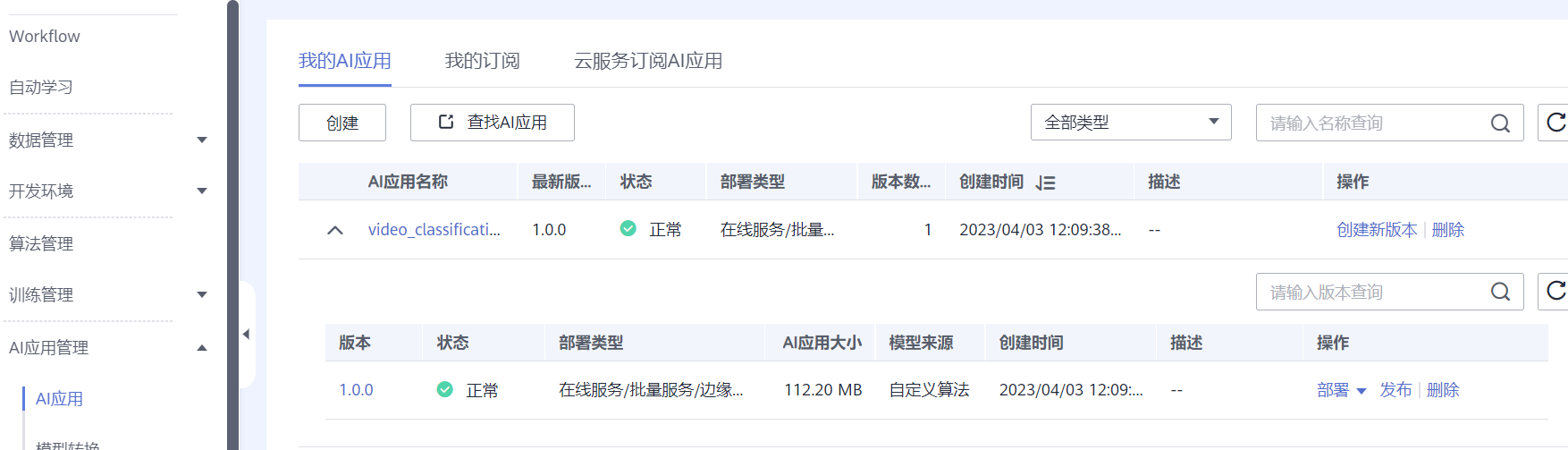
提交模型
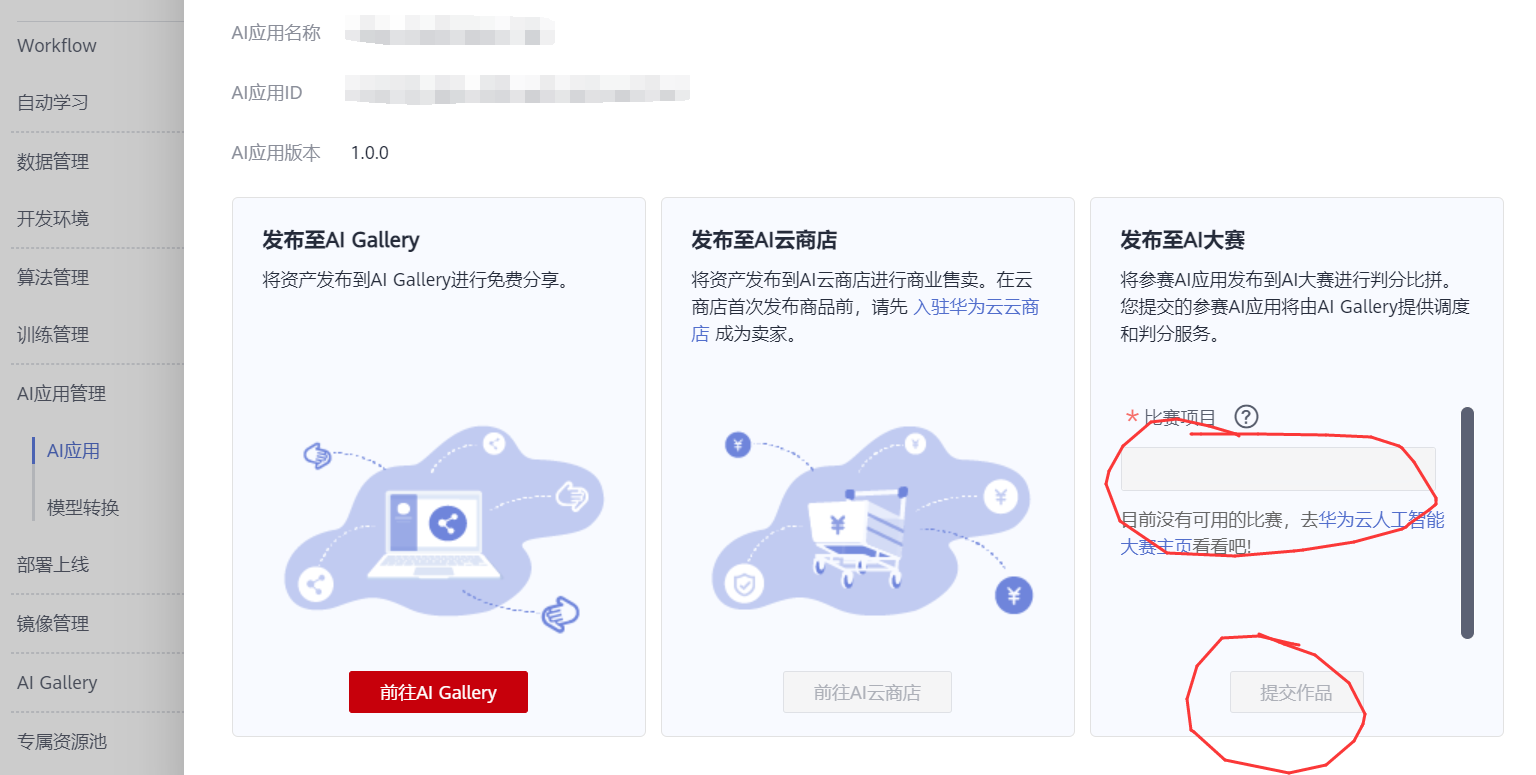
如果你现在想测试一下模型包是否正确,可以在线部署,然后上传一段视频检测,检测完后我们点击发布,提交模型至大赛

Comments NOTHING