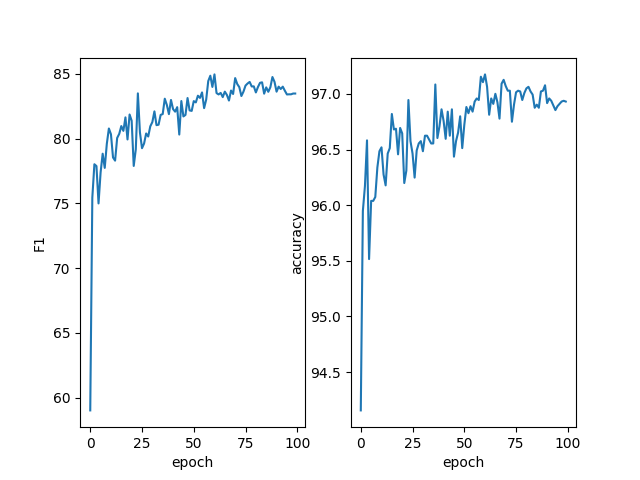
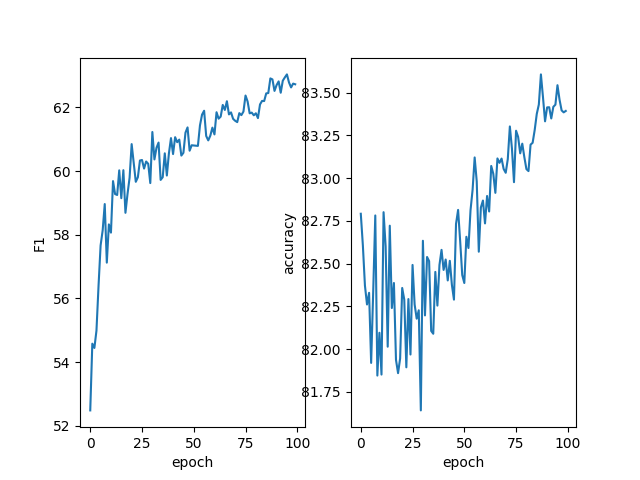
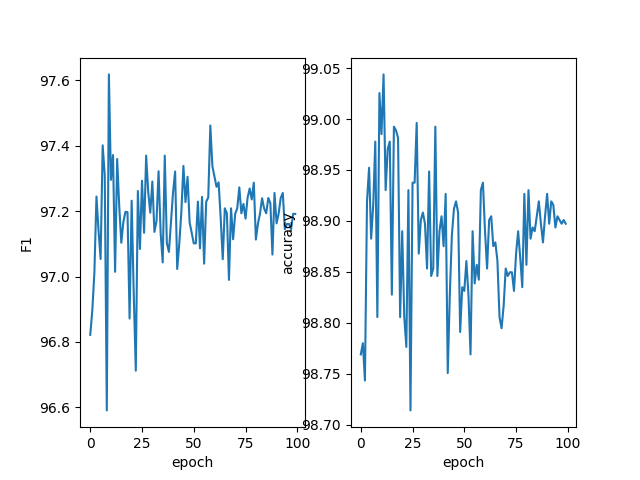
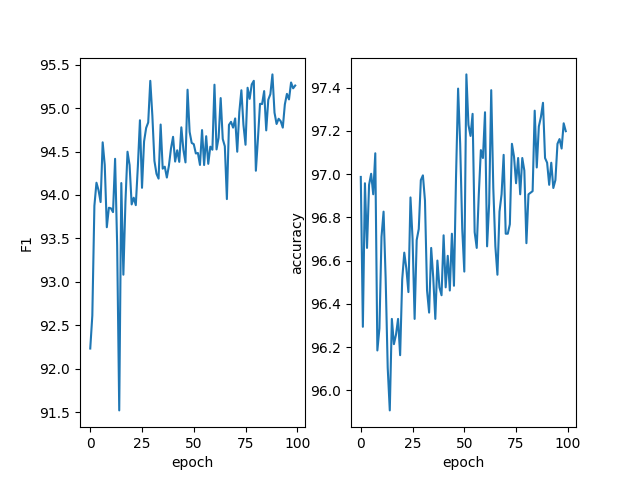
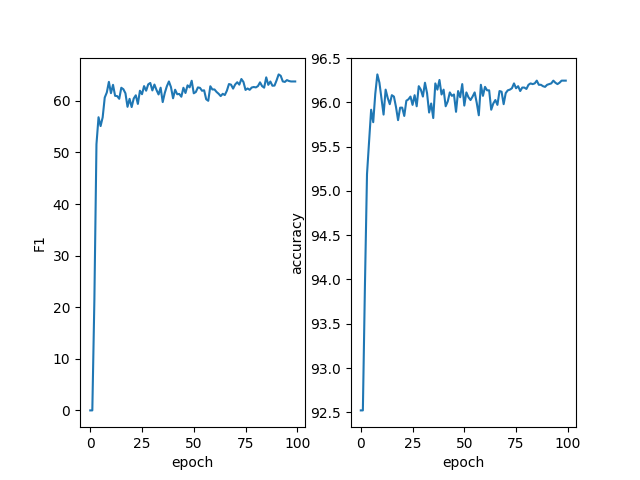
第四次组会报告 发布于 2024-10-08 1123 次阅读 预计阅读时间: 3 分钟 把徐凤娇学姐的其他三个数据集也跑一遍 cck2020数据集(医学数据集) chip数据集(医学数据集) 超声波乳腺癌数据集(自建医学数据集) resume数据集(通用领域数据集) weibo数据集(通用领域数据集) 裴伟学长的代码跑一遍 用的新买的服务器。但跑出了这个东西 然后我想着再跑几天,结果pycharm卡死了 修改徐凤娇学姐的论文&看看现在命名实体识别还有没有研究的必要 首先,李小龙学长在群里也说了现在用大模型解决命名实体识别任务是可行的,但效果可能不如传统的NER模型。国庆期间我也去用GPT3.5试了一个测试集,效果确实是不如学姐的那个模型的。 我感觉也确实如此,因为GPT是生成式大语言模型,他本身是不擅长做序列标注的任务的。然后想到这里我发现,其实学姐这篇论文也用了大模型,BERT就是一个预训练语言模型,学姐用了BERT的变种LEBERT。所以我感觉这个思路并没有过时。最后我也和胡枫学长商量了一下,他现在确实在忙裴伟的那篇论文,徐凤娇学姐的这篇论文还没看。然后我这个星期开始看着改一下那个英文论文,主要是根据审稿意见看着大体上加哪些内容,然后细节方面等胡枫学长一起做。 题外话 这是老服务器 这是新服务器





Comments NOTHING