


扩散模型的运作原理
如下图,时间步step是自己定义的,例如这里1000步就是纯白噪声,1步就是清晰的图片,从step1000到1的过程就是去噪,也叫做reverse process(反转处理)。
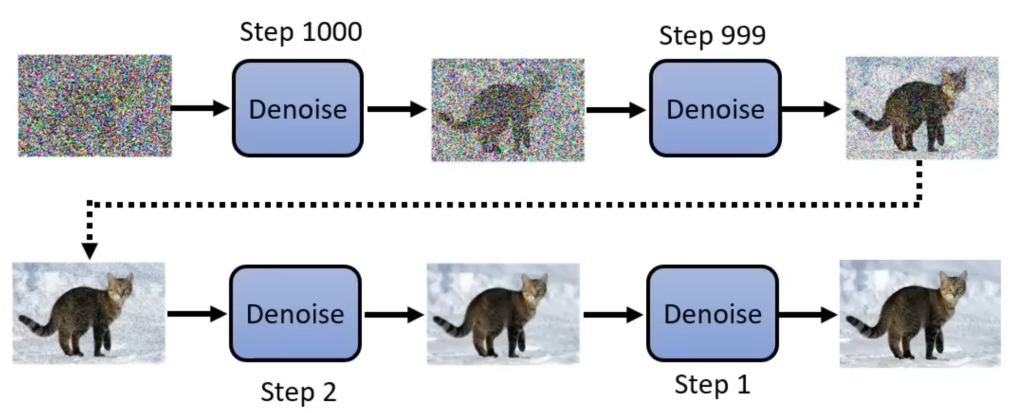
扩散模型的原理正如米开朗基罗说的一句话:“雕像本来就在大理石里面,我只不过把多余的部分去掉了”。
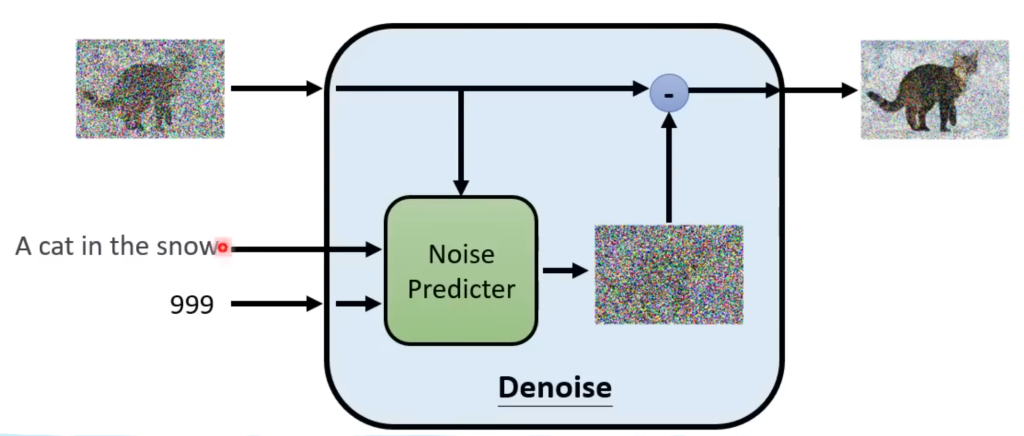
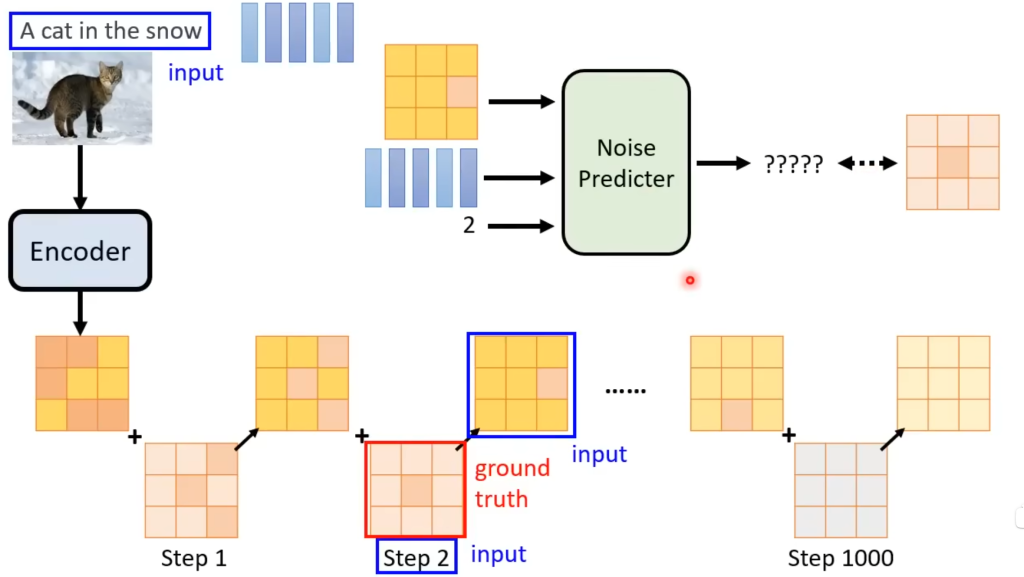
需要注意的是,在上图中每个去噪模型(Denoise)看起来都一样,实际上是不能完全一样的,因为每一步的输入图片都是不同的,比如白噪声和已经比较清晰的图片是不能用同样的方法处理的。因此Denoise的输入除了当前时间步的图片,还要加上当前的时间步(如下图)。你可以理解为输入的时间步越大,当前的图片噪声就越大。Denoise模型就能做出不同的回应。

Denoise的内部构造
Denoise在内部会根据输入的图片和时间步预测出该图片的噪声(分布),然后拿输入的图片减去这个噪声,就得到了输出。
那为什么要预测噪声而不是直接输出带噪声的目标图片呢。因为预测噪声和预测带有小猫的噪声图片难度是不一样的。
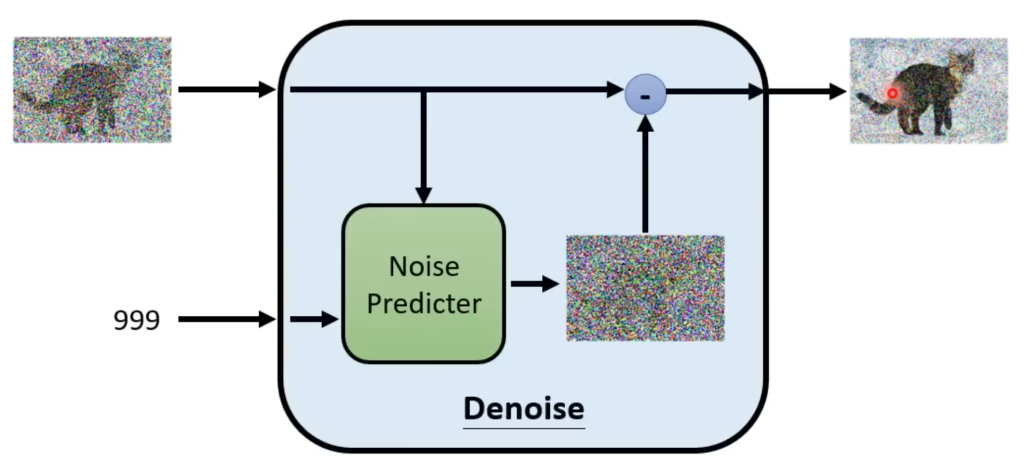
那么,这个噪声分布怎么得到呢?我们知道,想要预测出噪声,就要知道ground truth(即人工测量的真实值,类似nlp里的标签),而这个ground truth其实人为创造的。
具体的训练过程是:在数据集中拿出图片,然后加上随机sample的一组噪声,得到step2的图片;然后再随机sample一组噪声加上去,得到step3......以此类推,最后完全看不出原来图片,这个加噪声的过程称为Forward Process(前向处理)或者diffusion process(扩散)。如下图
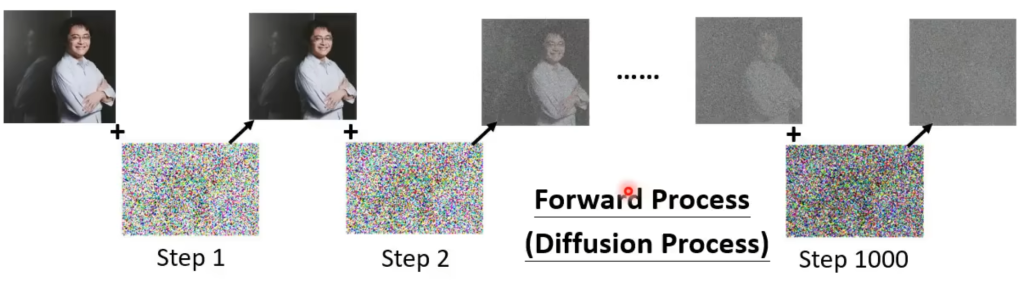
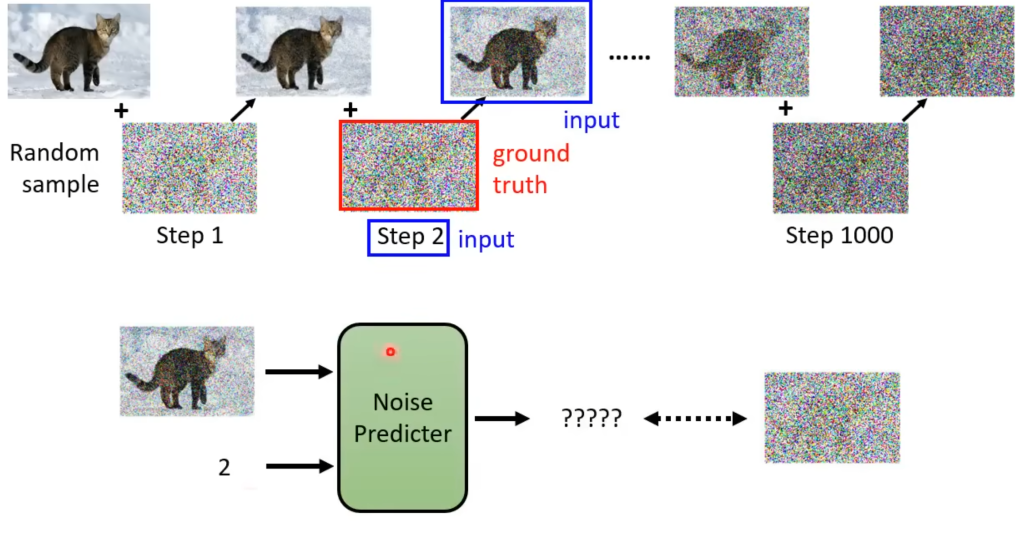
在加好噪声之后,你就得到了noise predict的训练资料了。
例如,对于step2,加了噪声后的图片和step2就是训练网络的输入(蓝色部分),人工在这一步加的噪声就是训练网络需要生成的内容,即ground truth(红色部分)。
对于带文字的模型,比如文生图模型,那么训练的数据就是成对的文字-图片,并且在训练noise predict的时候也要额外增加“文字”这个输入源。如下图
所以在接受了巨量“文字-图片”的训练过程后,你就会发现一开始用的米开朗基罗那个比喻太恰当了,因为一张纯白噪音图片里面可以包含任何内容,只要正确的一步步去噪就可以了。
stable diffusion
这节讲的是推理过程,即如何从文字→图像。
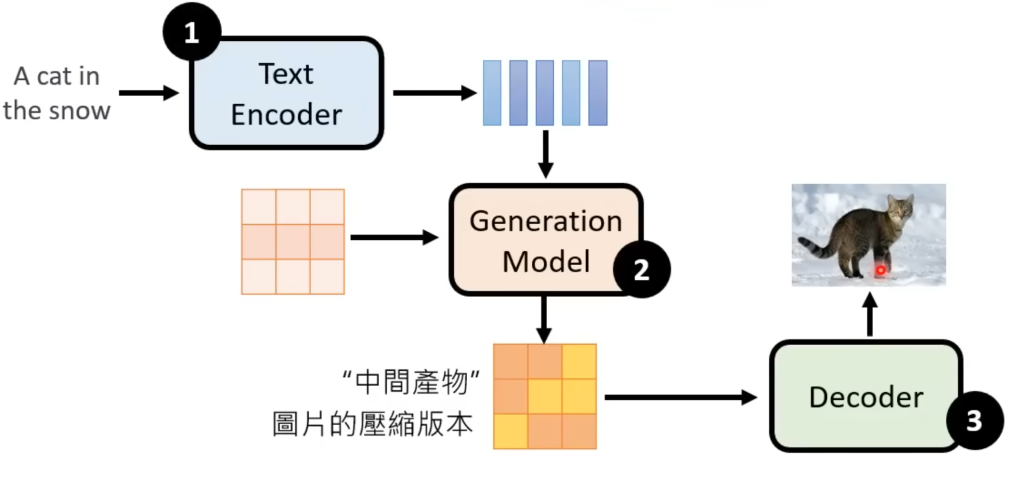
大致的过程如下图,输入的文字经过文字编码得到一系列向量,然后和一个噪声(图中粉红部分)一起输入进生成模型(generation model,这里用扩散模型),输出一个带有“文字信息”的压缩的噪声图片,这是一个中间产物,这个图片可以能看懂也可以看不懂。最后将这个中间产物丢进解码器输出最终的图像。
不止是stable diffusion,目前几乎所有的文生图模型都是这个套路(三个部分),其中图中用数字标出的这三个模型是三个独立的模型,需要单独训练的。
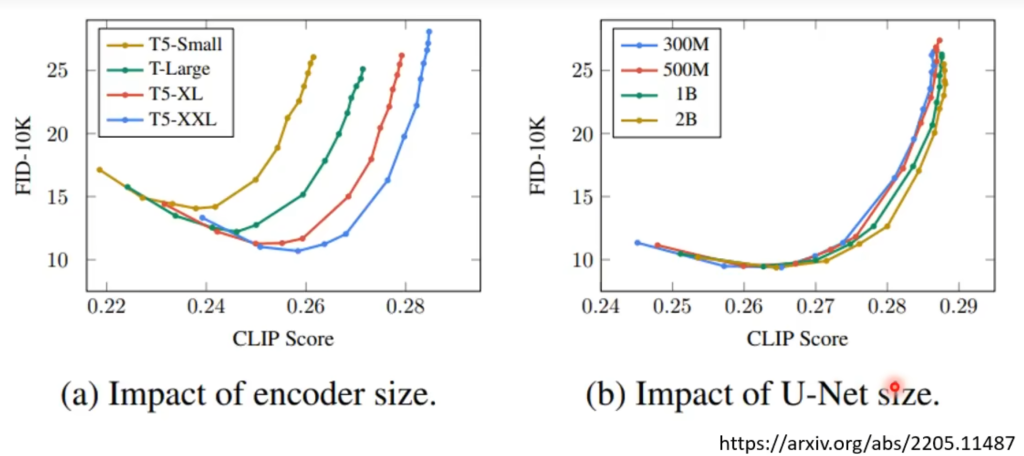
从下面这个图可以看出,text Encoder的大小对结果有着很大的影响。可以理解为encoder的size越大,模型就越可能输出自然的语言,对训练中没见过的文字-图片信息也能很好的应对。现在这个text encoder部分用GPT模型比较多,也有用BERT的。
再看右边这个图,表明U-Net(即扩散模型中noise predict的大小)的size对模型的结果反而没什么影响。
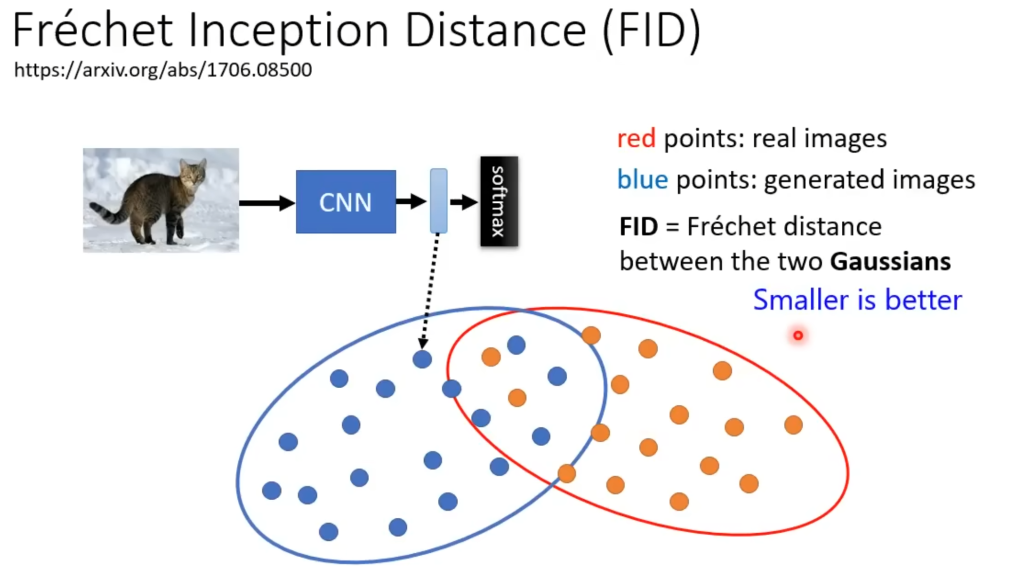
FID
FID,是生成的图片的一个评价指标。它用另一个CNN网络来评估,将原图和生成的图像都放进该CNN模型,得到一系列分类,然后评估两者的距离,通常会在很多张图片上进行评估,例如FID-10k就是在10000张图后再进行距离计算。
CLIP
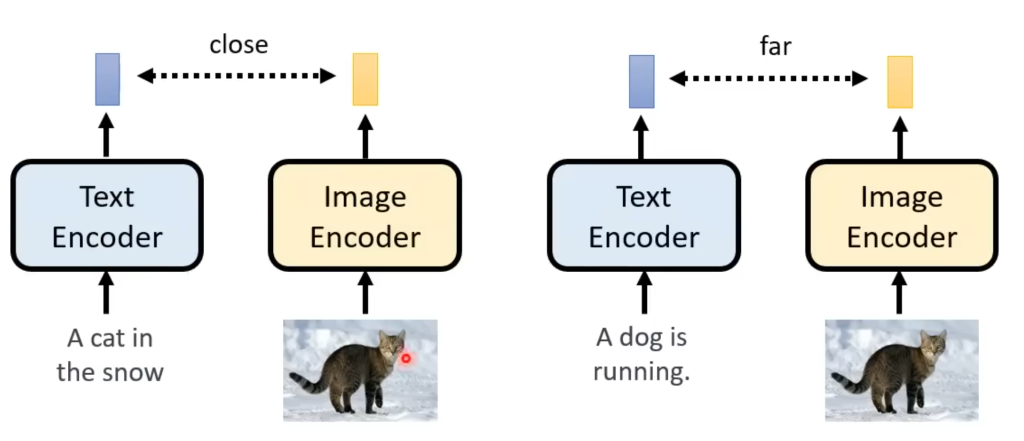
即contrastive language-image pre-training的缩写,也是评价生成图片的指标之一。他将数据集中成对的“文字-图片”分别做encoder,如果描述正确,那么encoder后的向量距离就会非常近,以此来判断生成的图片是否符合输入的文字要求。
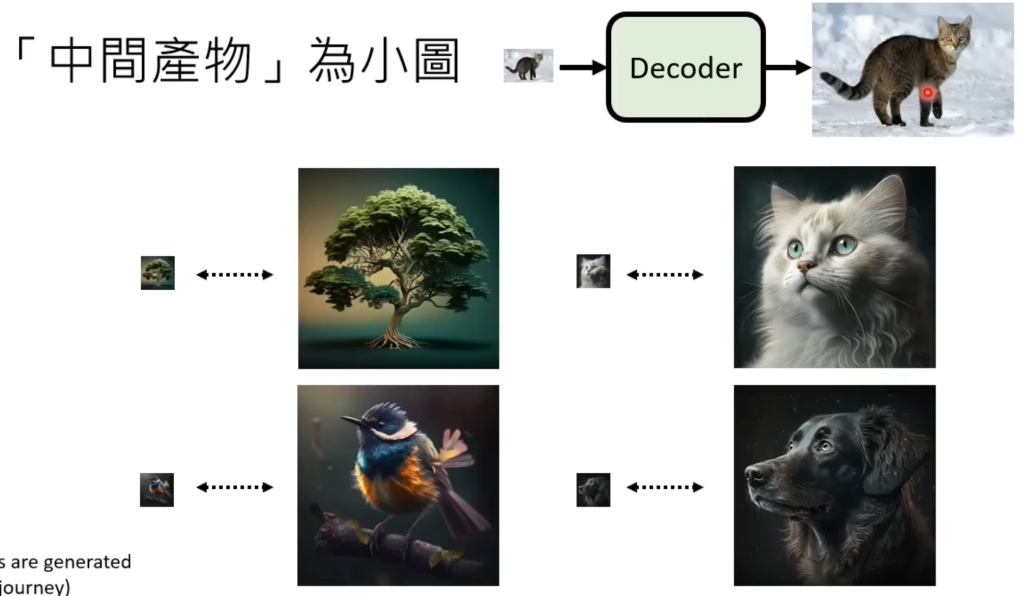
Decoder部分
generation model这块模型的训练是必须要用到配对的“文字-图片”数据集的,但Decoder部分只需要图片数据就可以了。
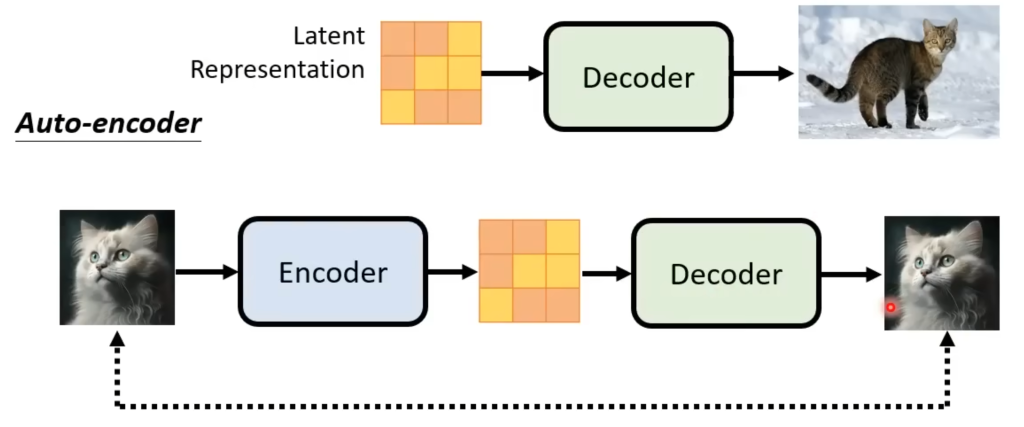
如果“中间产物”是低像素小图的话,只需要把图片缩小,就有Decoder的训练数据了。如果“中间产物”是潜空间表示(latent representation),那需要将图片用encoder转换成潜空间,然后用Decoder还原,还原的图片和原图越近越好,最后把训练好的Decoder拿出来用。
generation model部分
这一块的训练方法第一节的时候就讲过了,不过有一点不同,我们需要将图片先用encoder转为潜空间,然后用这个潜空间来加噪声。加完噪声之后训练也是一样,输入时间步,该步的加了噪声的潜空间图片,和经过encoder的文字向量,希望输出的是该步的噪声。
Comments NOTHING