


我们文章所属的任务层级图为:
Text Generation Task(文本生成任务)
↓
Image Captionin(图片描述)
↓
Medical Imaging Report Generation(医学影像报告生成)
image caption的传统结构
第三章的模型属于传统的image caption任务的结构,绝大多数模型的结构都为:
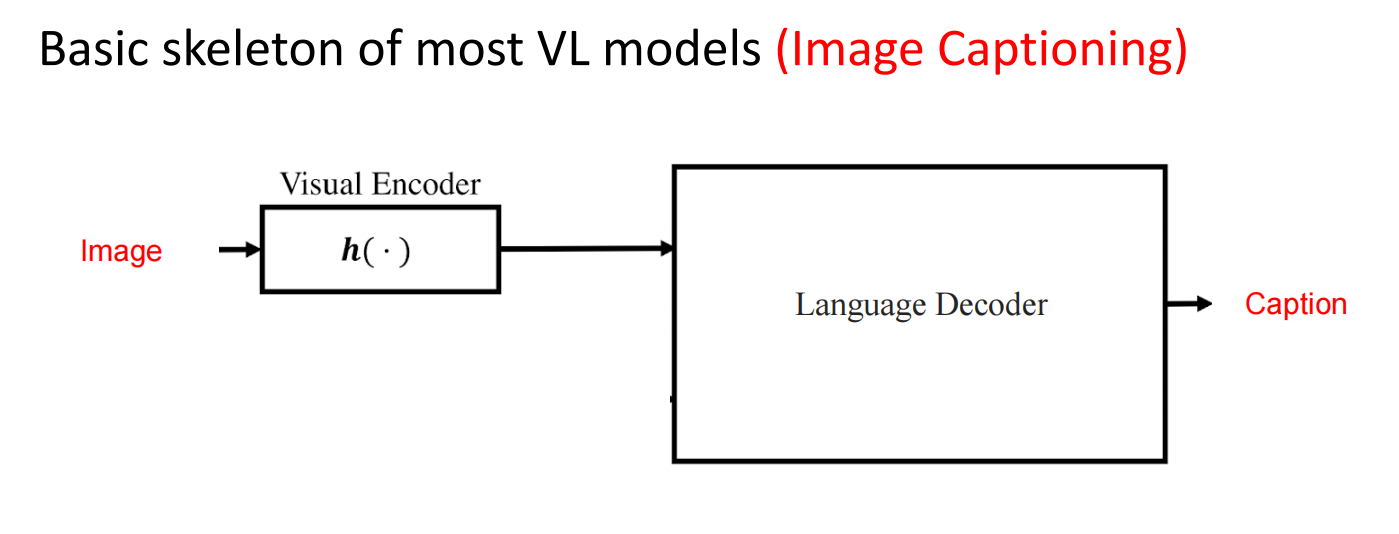
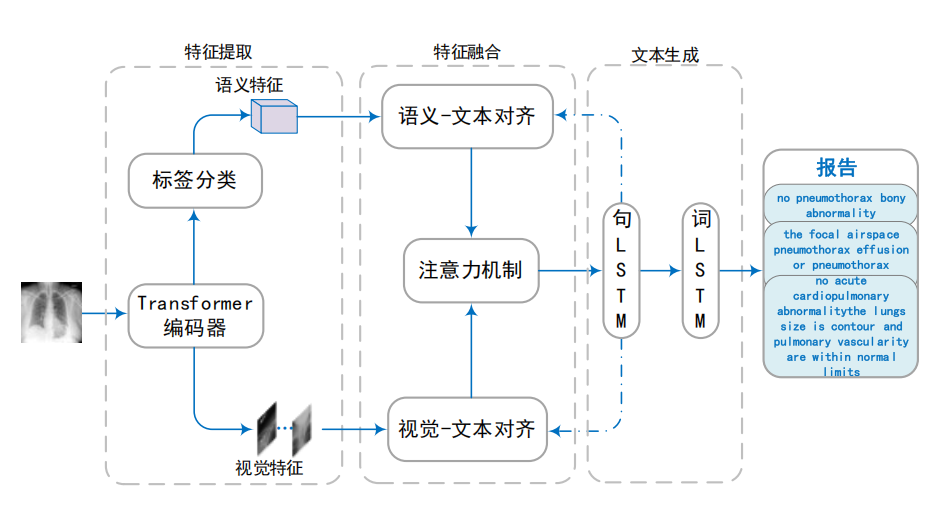
我们文章第三章的模型结构:
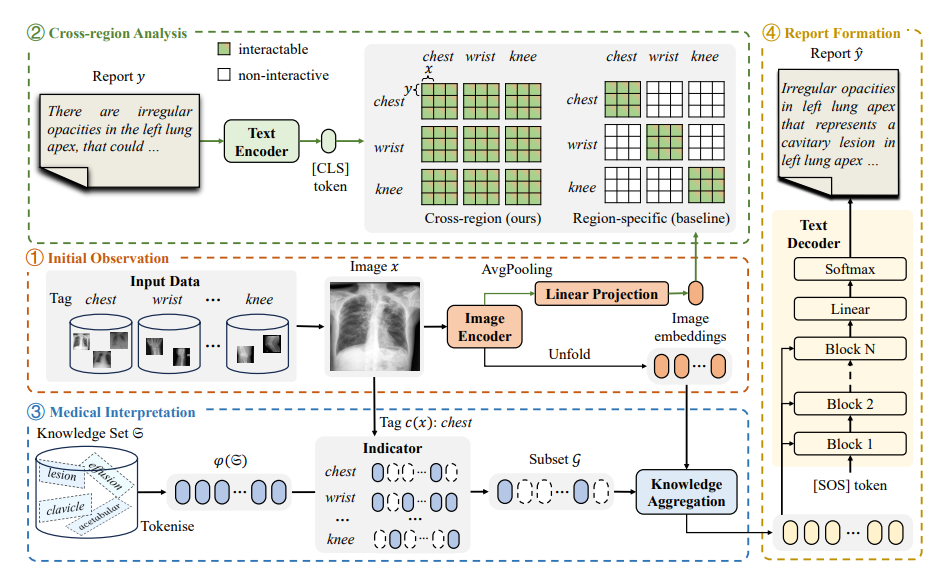
其他人的模型结构:
扩散模型在文本生成上的应用
目前NLP社区Transformer已经成为主流范式了,但是Transformer作为自回归范式的模型,也有它自身的问题。
一方面,自回归范式容易导致错误累计,即在预测结果过程中如果发生了错误,自回归的范式就会导致”预测错"的token进一步影响后续token的生成,进而影响整个结果;另一方面,Transformer在计算消耗一般比非自回归模型要更大,这一点在图像生成领域其实也类似。
自然的想法就是拿非自回归的diffusion models来做text generation,然而要注意的是,标准的diffusion models范式——DDPM是为图像生成提出的。而自然语言通常以离散的形式存在,因此不能直接将diffusion models用于text generation,在data modeling上还需要额外的设计,这也是现有工作的创新点之一。
扩散模型在文本生成的发展历程:
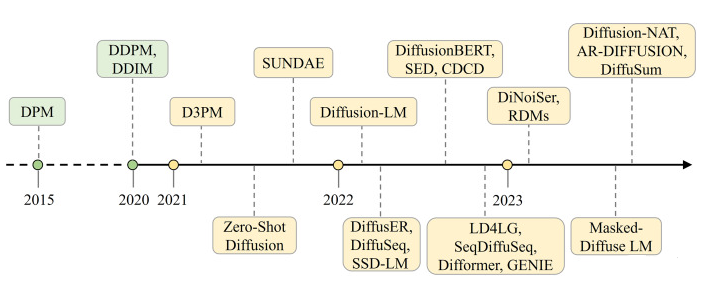
总结表:
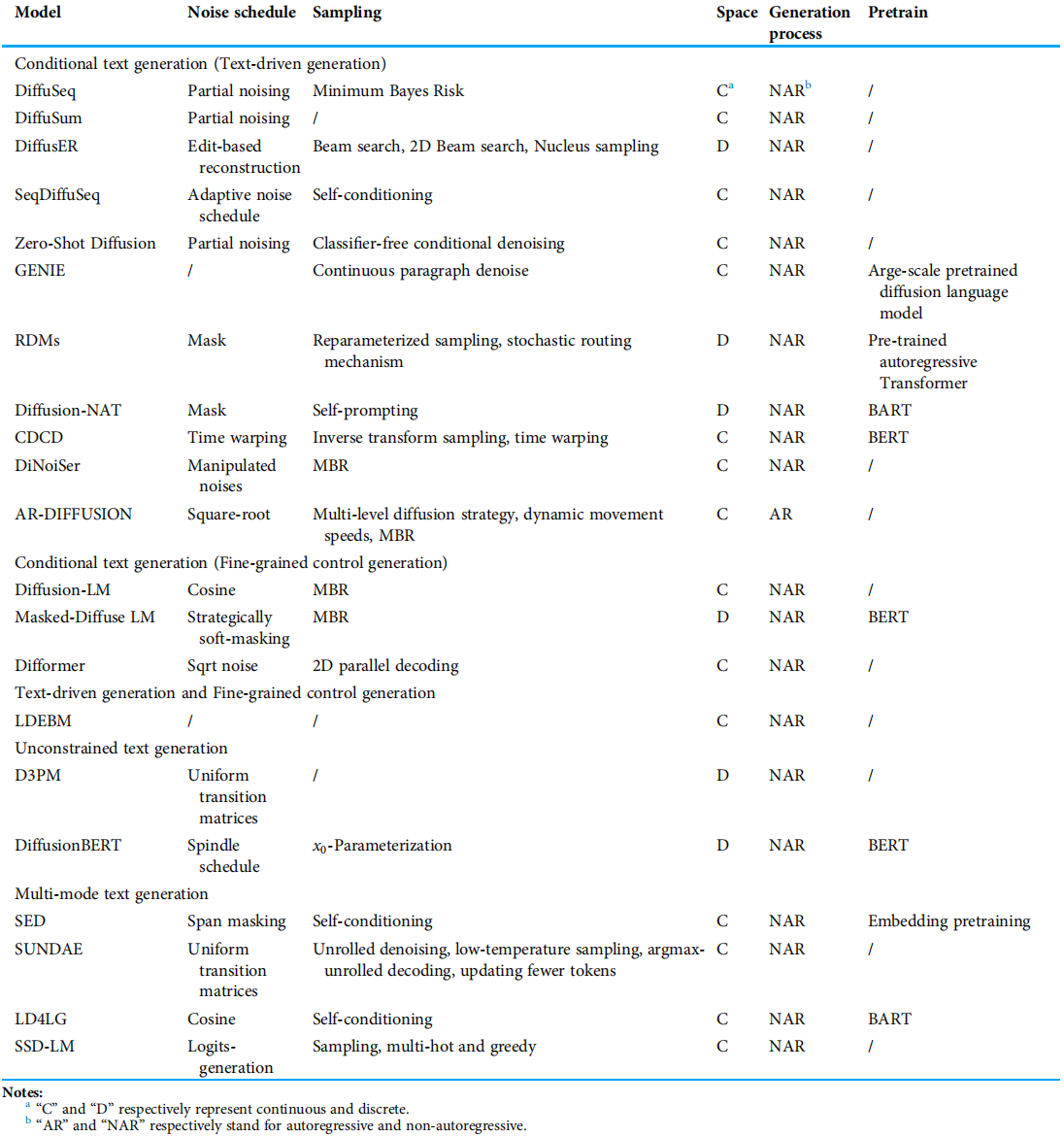
挑重点的几个分个类
按照扩散模型输入是否离散,可以分为离散扩散模型和连续扩散模型
离散扩散模型
代表作:D3PM,DiffusionBERT
这一类模型不再采用高斯噪声对数据分布进行降质处理,而是使用掩膜的方式进行,例如[mask] token作为“噪声”,在sampling的过程中是随机将[mask]预测成对应结果来完成生成过程,其形式与DDPM类型的传统diffusion models已经有较大差别。
D3PM核心思想
通过引入结构化转移矩阵优化扩散过程,解决了传统扩散模型在离散空间中的局限性。
转移矩阵设计:
- 吸收状态(Absorbing):每个token以概率βt被替换为[MASK],最终收敛为全掩码序列。
示例:文本生成中,高信息量词汇(如实体)优先被掩码,反向生成时逐步恢复。 - 离散高斯(Gaussian):模拟连续空间的高斯扩散,转移概率与token的序数相似性相关,适用于图像像素值。
- 嵌入相似性(Embedding-NN):基于词嵌入的相似性,优先替换语义相近的token(如元音→元音)。
DiffusionBERT的改进:
- Spindle Noise Schedule(纺锤形噪声调度): 根据每个令牌的信息量(如熵)动态调整噪声添加策略。高信息量词汇(如实体名词)在扩散早期被掩码,低信息量词汇(如功能词)在后期掩码,使生成过程更符合“易到难”的语言特性。
- Time-Agnostic Decoding(时间无关解码): 不显式输入时间步信息,而是通过输入序列中掩码的数量隐式推断时间步。实验表明,这种方式优于显式时间步嵌入。
- 将BERT作为反向扩散过程的初始化,加速去噪。利用预训练的BERT预测被掩码的原始令牌,逐步去噪生成文本。

Bit扩散模型
代表作Bit Diffusion
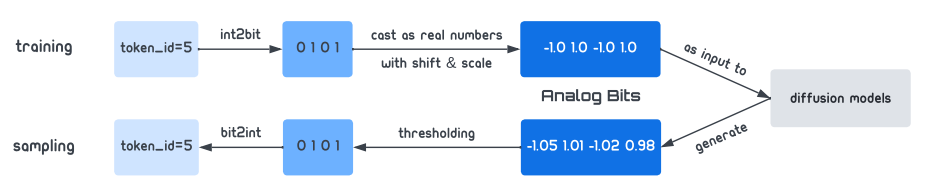
从代码的角度来看,文本的每个token在词表中都对应了一个index,而这个index就是我们期望预测的结果,是十进制离散的。Bit Diffusion做的事情是进一步将十进制的index,变为二进制的序列来表示。
举个例子,给定一个文本序列长度为 L ,Bit Diffusion做的事就是用d 维度的二进制序列(比方说index是10, d=8 ,那么二进制就是00001010),这样一来我们就能拿到一个 L×d 的矩阵,加上batch和channel维度的话,就是一个 B×C×L×d 的张量。
这就是图像B×C×H×W的表示形式,自然也就能够直接将diffusion models用于文本生成了。
Embedding-Based Models(我的理解就是连续扩散模型)
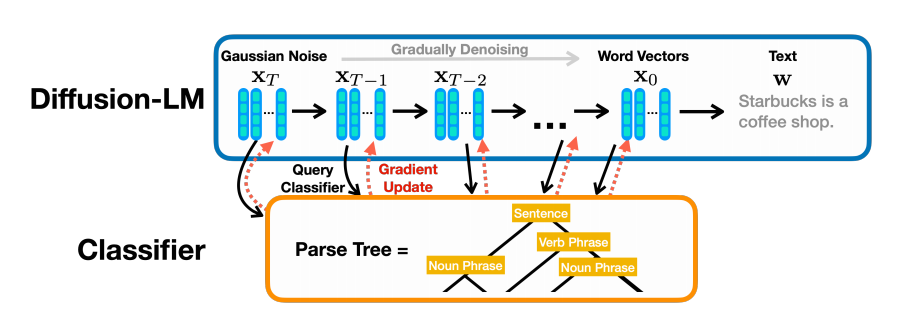
代表作:Diffusion-LM
Embedding-Based Models的做法就比较直接了,具体就是用一个随机初始化的embedding layer将离散的文本变为特征向量的形式,随后在diffusion models更新的过程中优化embedding layer。
同理,给定长度为 L,embedding layer的特征维度为 d ,这样的做法也能够将离散文本转换成为 B×C×L×d 的形式。
后续DiffusionSeq将Diffusion-LM模型应用到了seq2seq任务中,做法是在扩散过程中遮住回答文本y,而不遮住问题文本x。
问题
就源代码来看,第四章用到的基准模型应该是Diffusion-LM。因为用到了将离散的文本映射到连续的向量中(EMB),并且用预测x0代替预测噪声也是这篇文章提出的。
原文给出的解释是Diffusion-LM模型加入了嵌入(EMB)操作,自然也要有舍入(Rounding)操作,而直接预测x0可以减少连续的向量rounding回离散的文本这一过程的误差。
Comments NOTHING