


上篇文章提到,扩散模型根据处理文本方式的不同,可以分为三类:离散扩散模型(DDPM,DiffusionBERT),Bit扩散模型(Bit Diffusion),连续扩散模型(Diffusion-LM)。这三类扩散模型后续都有相应的用在image caption上的研究,分别是基于连续扩散模型的DiffusionCap,基于Bit扩散模型的SCD-Net,基于离散扩散模型的DDCap。
DiffusionCap
DiffusionCap是基于连续扩散模型Diffusion-LM提出的一种应用于图生文的模型。它的总体结构如下图所示:
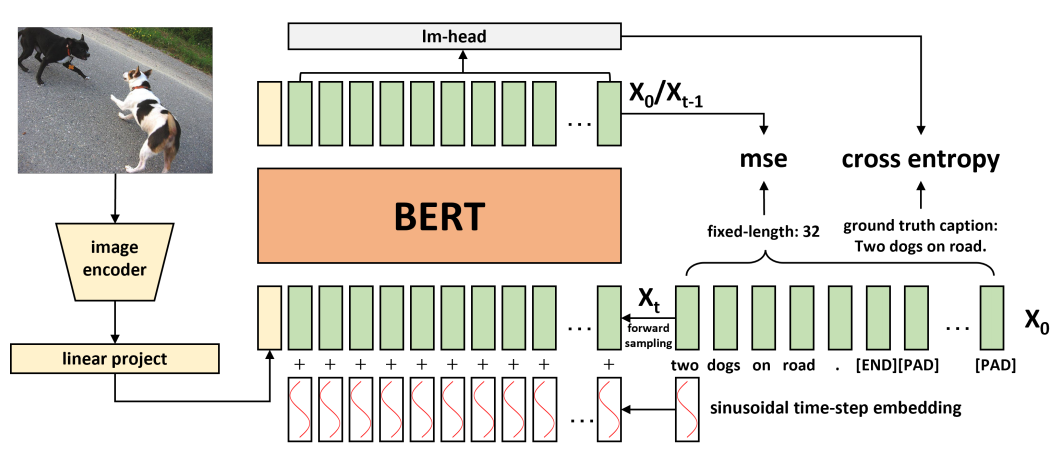
模型结构详解
1. 视觉编码器(Visual Encoder)
- 架构选择:
使用预训练的 CLIP(ViT-B/32) 或 ViT-Base/32 作为视觉编码器,模型参数在训练过程中 保持冻结,不参与反向传播。 - 特征提取:
- 输入图像通过视觉编码器提取全局特征,取
[CLS]位置的输出向量(CLIP为512维,ViT为768维)。 - 通过一个 线性投影层 将视觉特征映射到与文本嵌入相同的维度(例如BERT的隐藏维度,通常为768维)。
- 输入图像通过视觉编码器提取全局特征,取
2. 扩散语言生成组件(Diffusion Language Generator)
- 文本预处理:
- 使用 BPE分词器 对文本进行分词,低频词(出现次数<10)替换为
[UNK]。 - 句子被填充或截断为固定长度(如32 tokens),末尾添加
[END]标记(若未截断)。 - 分词后的token通过 嵌入层 转换为连续向量(维度与视觉特征对齐)。
- 使用 BPE分词器 对文本进行分词,低频词(出现次数<10)替换为
- 扩散过程:
- 前向过程(加噪):对文本嵌入逐步添加高斯噪声,噪声强度由 余弦调度器 控制。
- 反向过程(去噪):
- 输入拼接:扩散后的文本嵌入与投影后的视觉特征 拼接(而非相加),形成联合输入序列。
- 时间步嵌入:扩散时间步 t 通过 正弦位置编码 嵌入为向量,拼接至输入序列头部(或逐元素相加)。
- BERT去噪:拼接后的序列输入至 BERT模型,预测当前步的干净文本嵌入。
- LM头:BERT输出通过线性层(LM头)生成每个token的logits,经softmax得到概率分布。
- 离散化(Rounding):
- 去噪后的连续嵌入通过 KNN搜索 或 最近邻匹配 映射回离散token(避免直接使用argmax以减少
[UNK]生成)。
- 去噪后的连续嵌入通过 KNN搜索 或 最近邻匹配 映射回离散token(避免直接使用argmax以减少
训练过程详解
1. 损失函数

2. 训练策略
- 优化器:
使用 AdamW 优化器,初始学习率 1e−4,线性学习率衰减策略。 - 批次与资源:
- 单卡训练(NVIDIA 3090,24GB显存),COCO数据集批次大小=64,Flickr30k批次大小=32。
- 训练50个epoch,耗时约12小时(COCO)。
- 噪声调度器:
采用 余弦调度器(优于线性和平方根),噪声强度 βt 随扩散步 t 非线性增加。
3. 关键超参数
- 文本序列长度:固定为32 tokens(通过填充或截断)。
- 扩散步数 T:通常设置为1000步(推理时可通过加速算法减少至50-100步)。
- 嵌入维度:COCO为256维,Flickr30k为128维。
生成(Decoder)过程示例
- 初始噪声:从高斯分布采样初始噪声 xT∼N(0,I)。
- 迭代去噪:
- 对每个扩散步 t=T→1,将当前噪声 xt 与视觉特征拼接,输入BERT预测 xt−1。
- 离散化:
- 最终 x0 通过KNN映射为token序列,生成完整描述。
补充说明(这一节是讲我自己不清楚的部分,后面复习的时候不用看)
1. LM头(Language Model Head)的作用与过程
在DiffCap中,LM头是一个关键的组件,负责将BERT输出的连续表示转换为具体的词汇概率分布。以下是详细步骤:
步骤说明
-
BERT输出:
经过扩散去噪后,BERT模型输出的每个token位置对应一个 连续向量(例如768维)。 -
线性层(LM头):
这些连续向量通过一个 线性变换层(即全连接层)映射到 词汇表大小维度(如COCO数据集的8016个token)。-
例如,若词汇表大小为8016,线性层将768维向量转换为8016维的logits(每个维度对应一个token的未归一化分数)。
-
-
Softmax归一化:
Logits经过Softmax函数转换为 概率分布,表示每个token在当前位置出现的可能性。-
例如,Softmax后,第5000个维度可能对应概率0.8,表示该位置生成第5000个token的概率较高。
-
直观理解
-
类比MLM任务:
类似于BERT的掩码语言模型(MLM)任务,LM头的作用是预测被遮蔽的token。在DiffCap中,LM头预测的是去噪后的token分布。 -
与自回归模型区别:
自回归模型(如GPT)逐token生成,而DiffCap的LM头在扩散过程中并行预测所有token的概率分布,从而实现非自回归生成。
2. KNN搜索/最近邻匹配:避免[UNK]的生成策略
问题背景
-
低频词与[UNK]:
在分词阶段,低频词(如出现次数<10)会被替换为[UNK]token。若直接对LM头的概率分布使用 argmax,模型可能倾向于高频词或[UNK],导致生成结果中出现大量[UNK]。
解决方案:KNN/最近邻匹配
-
连续嵌入空间:
-
去噪后的每个token对应一个 连续嵌入向量(如256维)。
-
所有已知token的嵌入向量在训练时已被学习并存储在嵌入层中。
-
-
最近邻搜索:
-
对每个去噪后的嵌入向量,计算它与 嵌入层中所有token嵌入的余弦相似度(或欧氏距离)。
-
选择 最接近的Top-K个token(如K=5),再从这K个候选中选择概率最高的token。
-
-
避免[UNK]的机制:
-
在搜索时,可以 排除嵌入层中的[UNK] token,强制模型选择有效词汇。
-
例如,即使
[UNK]的嵌入距离最近,也会跳过它,选择次优的有效token。
-
具体示例
假设去噪后的嵌入向量为 e,嵌入层包含以下token嵌入:
-
猫: e1,狗: e2,房屋: e3,[UNK]: e4。
计算 �e 与每个嵌入的相似度:
-
sim(e,e1)=0.9,
-
sim(e,e2)=0.8,
-
sim(e,e3)=0.6,
-
sim(e,e4)=0.95.
若直接选最相似,结果为 [UNK]。
但通过 排除[UNK],实际选择 猫(次优但有效)。
DDCap
DDCap是基于离散扩散模型D3PM模型提出的一种图生文模型。其总体结构如下:
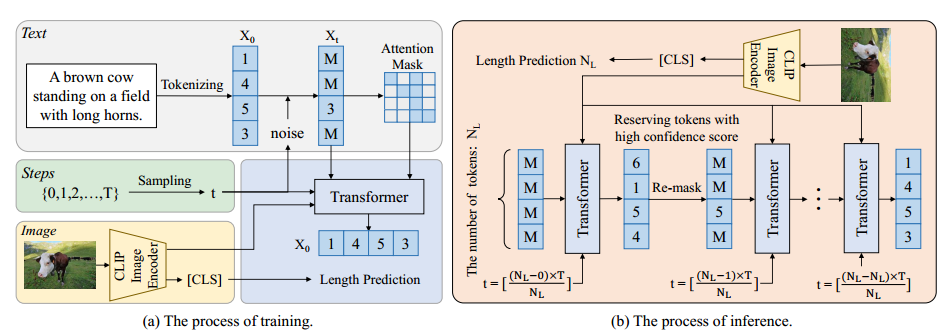
图像编码器、文本预处理、扩散过程与文本生成详解
1. 图像编码器(Image Encoder)
模块功能:提取图像语义特征,作为生成文本的条件输入。
- 架构:采用 CLIP-ViT-B/16 模型,基于 Vision Transformer(ViT)。
- 图像分块:输入图像(224x224)被分割为 16x16 的块(共 14x14=196 块)。
- 线性投影:每个图像块通过线性层映射为 768 维向量。
- 位置编码:为每个块添加可学习的位置嵌入,保留空间信息。
- Transformer 层:12 层 Transformer,每层含 12 个注意力头,输出全局 [CLS] 标记的嵌入作为图像特征。
- 输出:图像特征为 768 维向量,用于后续文本生成的跨模态注意力。
2. 文本预处理(Text Preprocessing)
模块功能:将原始文本转换为模型可处理的离散标记序列,并添加噪声。
- 分词:使用 GPT-2 的 BPE 分词器(词汇表大小 50,257),将文本转换为标记 ID 序列。
- 填充与截断:序列填充至 最大长度 20,短文本补 [PAD],长文本截断。
- 噪声添加(前向扩散):
- 初始状态:真实文本标记 x0。
- 噪声策略:
- 每个标记以概率γt 替换为 [MASK],以 βt=1−αt−γt 替换为随机标记,保留概率 αt。
- 噪声调度:线性增加 γt,扩散步数 T=20。
- 最终状态:经过 T 步后,所有标记变为 [MASK]。
3. 前向扩散过程(Forward Diffusion Process)
模块功能:通过马尔可夫链逐步添加噪声,模拟文本退化过程。

- 时间步嵌入:
- 扩散步数 t 通过正弦-余弦位置编码映射为向量
- 嵌入向量用于 自适应层归一化(AdaLN),调整 Transformer 层的归一化参数。
4. 反向去噪过程(Reverse Denoising Process)
模块功能:通过训练好的 Transformer 解码器,从含噪声文本逐步恢复原始文本。
实现细节:
- 输入:
- 含噪声文本 xt(初始为全 [MASK])。
- 图像特征 y(来自 CLIP-ViT)。
- 时间步嵌入 t。
- Transformer 解码器:
- 结构:12 层 Transformer,每层包含:
- 自注意力:文本标记间的双向注意力。
- 跨模态注意力:文本标记与图像特征的交叉注意力(Query 来自文本,Key/Value 来自图像)。
- AdaLN:根据时间步嵌入调整层归一化的参数。
- 输出:预测原始文本 x0 的概率分布(每个位置的词汇表 logits)。
- 结构:12 层 Transformer,每层包含:
- 去噪步骤:
- 从t=T 到t=1,逐步生成xt−1:
- 预测 x0=argmax(pθ(x0∣xt,y))。
- 根据 x^0 和噪声调度表,采样生成xt−1。
- 最佳优先推理:每步固定置信度最高的前 Kt 个标记(如Kt=⌊NL⋅(T−t+1)/T⌋)。
- 从t=T 到t=1,逐步生成xt−1:
5. 从预测的 x0 到文本的转换
模块功能:将模型输出的概率分布解码为最终文本。
实现细节:
- 标记解码:
- 对每个位置的 logits 取 argmax,选择概率最高的标记 ID。
- 若预测到 [EOS] 标记,提前终止生成。
- 后处理:
- 去除重复:检测连续重复标记并删除(如 "a a dog" → "a dog")。
- 长度调整:根据预测的长度 NL 截断或填充生成序列。
- 文本生成示例:
- 输入图像特征 → 模型生成标记序列 [“a”, “dog”, “running”, “in”, “park”]。
- 转换为自然语言:“A dog running in a park.”
6. 关键模块总结
| 模块 | 功能 | 技术细节 |
|---|---|---|
| 图像编码器 | 提取图像语义特征 | CLIP-ViT-B/16,16x16 分块,12 层 Transformer,输出 768 维 [CLS] 嵌入。 |
| 文本预处理 | 文本分词与噪声添加 | GPT-2 BPE 分词,最大长度 20,线性噪声调度(T=20)。 |
| 前向扩散 | 模拟文本退化过程 | 马尔可夫链转移概率(保留、[MASK]、随机替换),时间步正弦嵌入。 |
| 反向去噪网络 | 逐步恢复原始文本 | 12 层 Transformer,跨模态注意力,AdaLN,直接预测 x0。 |
| 文本解码 | 将概率分布转换为文本 | Argmax 选择标记,处理重复与长度,生成最终描述。 |
7. 创新点与优势
- 跨模态融合:通过交叉注意力实现图像与文本的高效交互。
- 动态长度控制:分离长度预测与生成,适应变长文本。
- 噪声鲁棒性:集中注意力掩码(CAM)屏蔽无效 [MASK],提升生成质量。
- 双向生成能力:扩散模型支持全局上下文推理,优于自回归模型的单向生成。
该设计在 COCO 数据集上实现了与主流自回归模型竞争的 CIDEr 分数(125.1),并在描述填充任务中展现了显著优势(CIDEr 230.3)。
SCD-Net
SCD-Net是基于Bit Diffusion模型提出的一种图生文模型,其总体结构如下:
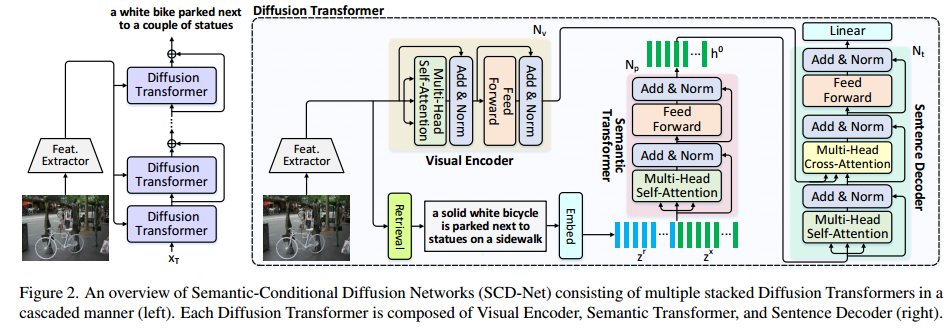
图像编码器(Visual Encoder)
1. 输入与特征提取
-
输入:原始图像通过预训练的Faster R-CNN模型(基于ImageNet和Visual Genome预训练)提取图像区域特征。
-
区域检测:Faster R-CNN检测图像中的显著区域(如对象、场景元素),每个区域输出一个2048维的特征向量。
-
降维:通过全连接层(FC)将2048维特征压缩为512维,减少计算复杂度。
2. Transformer编码器
-
结构:包含3层Transformer编码块,每层包含:
-
多头自注意力(Multi-Head Self-Attention):建模区域间的关系。
-
前馈网络(FFN):两层全连接,中间通过激活函数(如GELU)连接。

-
文本预处理(Text Preprocessing)
1. 词汇映射
-
词汇表:COCO数据集的训练句子经过过滤(词频≥4),得到10,199个唯一词。
-
二进制编码:每个词映射为14位二进制码,计算方式为:
n=⌈log2W⌉=⌈log210,199⌉=14
-
示例:若词ID为123,则转换为14位二进制字符串(如
00000001111011)。
-
2. 句子表示
-
输入句子:每个句子转换为 Ns×14 的二进制矩阵(Ns为句子长度)。
-
填充与截断:统一句子长度为固定值(如20词),超出部分截断,不足部分填充零。
前向扩散过程(Forward Diffusion Process)
1. 噪声调度
-
时间步:总时间步 T=50,均匀划分为离散步 t∈{1,2,...,T}。
-
噪声强度:通过单调递增函数 γ(t′)(t′=t/T)控制噪声比例
2. 噪声添加
-
公式:在时间步 t,带噪数据 xt 计算为:

-
解释:逐步增加高斯噪声 ϵ∼N(0,I),噪声占比随 tt 增大而升高。
-
3. 目标
-
训练信号:模型需从 xtxt 预测原始数据 x0x0,损失函数为均方误差(LbitLbit)。
反向去噪过程(Reverse Denoising Process)
1. 扩散Transformer(Diffusion Transformer)
-
输入:
-
带噪数据 xt(维度:Ns×14)。
-
视觉特征 V~(维度:K×512,K为区域数)。
-
语义条件 sr(检索句子的二进制编码,维度:Nr×14)。
-
-
关键模块:
-
语义Transformer:
-
将 xt 与前一时刻预测 x0 拼接,通过全连接层映射。
-
与检索的语义句子 sr 拼接,输入3层Transformer块,增强语义条件。
-
-
句子解码器:
-
双向自注意力(无掩码),支持并行生成。
-
输出每个位置的词概率分布 pi∈RW。
-
-
2. 反向步骤计算

3. 级联优化
-
级联结构:堆叠2个扩散Transformer,前一级输出 x0i−1 作为后一级的条件输入。
-
信息融合:在后级扩散Transformer中,将 x0i−1 与当前隐状态拼接(式11),增强语义连续性。
从预测的 x0x0 转换回文本
1. 二进制位量化
-
概率映射:解码器输出每个词的概率分布 pi,通过加权平均计算二进制位
-
Bc 是词汇表中第 c 个词的14位二进制码。
-
2. 词解码
-
二进制转词ID:将14位二进制码四舍五入为整数,再映射到词汇表中的词。
-
示例:若二进制码为
00000001111011,则对应词ID 123。
3. 后处理
-
去填充:移除填充的零,保留有效词。
-
重复词抑制:通过引导训练策略(GSCST)减少重复词生成
三个模型的对比
1. 图像编码器
-
DDCap:使用预训练的 CLIP ViT-B/16 模型提取图像特征,通过交叉注意力与文本交互。
-
DiffCap:采用 CLIP ViT-B/32 或预训练的 ViT 模型,将图像全局特征投影到BERT的隐藏维度。
-
SCD-Net:基于 Faster R-CNN 提取图像区域特征,并通过多层 Transformer编码器 增强上下文表示。
2. 文本预处理
-
DDCap:使用 BPE分词器(GPT-2风格),将文本转换为离散token,最大长度固定为20。
-
DiffCap:使用 BPE分词器,低频词替换为[UNK],并将每个词映射为二进制位(如14位),支持连续扩散。
-
SCD-Net:将每个词转换为 14位二进制,通过固定长度序列(截断或填充)适应扩散过程。
3. 前向扩散
-
DDCap:离散扩散,逐步将文本token替换为[MASK],噪声强度由时间步控制,最终全为[MASK]。
-
DiffCap:连续扩散,向二进制位添加高斯噪声,噪声强度按线性或余弦调度(如 ��βt 参数控制)。
-
SCD-Net:连续扩散,将文本二进制位逐步添加高斯噪声,噪声强度由时间步 �(�′)γ(t′) 函数控制。
4. 反向去噪
-
DDCap:基于 Transformer网络,结合图像特征和预测的文本长度,通过“最佳优先推理”固定高置信度token。
-
DiffCap:使用 BERT模型 作为解码器,融合图像特征和噪声文本嵌入,通过自注意力和交叉注意力去噪。
-
SCD-Net:采用 级联Diffusion Transformer,结合语义条件(检索到的相关句子)逐步去噪,并通过自关键序列训练优化生成质量。
5. 从x0到文本转换
-
DDCap:直接取概率最高的token,结合预测的文本长度截断生成结果。
-
DiffCap:通过KNN或softmax将去噪后的连续嵌入映射到词表,选择概率最高的词。
-
SCD-Net:对每个词的二进制位进行加权平均,转换为具体词,并通过量化操作恢复离散文本。
对比表格
| 模块 | DDCap | DiffCap | SCD-Net |
|---|---|---|---|
| 图像编码器 | CLIP ViT-B/16 | CLIP ViT-B/32 或 ViT | Faster R-CNN + Transformer编码器 |
| 文本预处理 | BPE分词,离散token | BPE分词,然后嵌入连续向量空间 | 词→14位二进制 |
| 前向扩散 | 离散替换为[MASK] | 连续高斯噪声(线性/余弦调度) | 连续高斯噪声(函数控制) |
| 反向去噪 | Transformer + 图像特征 + 长度预测 | BERT + 图像特征 + 自注意力 | 级联Diffusion Transformer + 语义条件 + 自关键训练 |
| x0到文本转换 | 取概率最高token | KNN/softmax解码 | 二进制加权平均 + 量化 |
| 关键技术 | 长度预测、集中注意力掩码、最佳优先推理 | 图像条件融合、时间步正弦嵌入 | 语义条件、级联结构、自关键序列训练 |
Comments NOTHING