


虽然说是代码篇,但也不会全讲,重要的部分会结合原理篇的图再讲一遍,次要部分会稍微注释一下。
vits项目的结构为:
configs
在configs文件夹中存放着多个json文件,用来设置模型整体的一些参数配置,以其中的一个为例
{
"train": {
"log_interval": 200,//每隔多少轮上报一次log
"eval_interval": 1000,//每隔多少轮进行一次测试
"seed": 1234,//随机种子
"epochs": 20000,//训练轮次
"learning_rate": 2e-4,//学习率
"betas": [0.8, 0.99],
"eps": 1e-9,
"batch_size": 64,
"fp16_run": true,
"lr_decay": 0.999875,
"segment_size": 8192,//原理篇中的切片slice中所包含的采样点个数,大概30毫秒
"init_lr_ratio": 1,
"warmup_epochs": 0,
"c_mel": 45,//原理篇中vits损失函数的Lrecon,比重参数是45
"c_kl": 1.0 //同上,原理篇中vits损失函数中的Lkl,因为vits主要是个VAE模型,所以这两个VAE的损失函数比重高一点
},
"data": {
"training_files":"filelists/ljs_audio_text_train_filelist.txt.cleaned",
"validation_files":"filelists/ljs_audio_text_val_filelist.txt.cleaned",
"text_cleaners":["english_cleaners2"],
"max_wav_value": 32768.0,//音频数据最大值,因为是16bit采样
"sampling_rate": 22050,
"filter_length": 1024,
"hop_length": 256,
"win_length": 1024,//以上三个是VAE输入端短时傅里叶变化后的特征参数,每一段长度为1024,段与段间距为256,一共1024段
"n_mel_channels": 80,//梅尔滤波器组数量
"mel_fmin": 0.0,
"mel_fmax": null,
"add_blank": true,//将文本变成符号之后,在每个符号之间加一个空格,符合人说话每个字中间的小停顿
"n_speakers": 0,
"cleaned_text": true
},
"model": {
"inter_channels": 192,
"hidden_channels": 192,
"filter_channels": 768,
"n_heads": 2,
"n_layers": 6,
"kernel_size": 3,
"p_dropout": 0.1,//以上这几个是是text encoder部分的参数
"resblock": "1",
"resblock_kernel_sizes": [3,7,11],
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
"upsample_rates": [8,8,2,2],
"upsample_initial_channel": 512,
"upsample_kernel_sizes": [16,16,4,4],//以上是decoder部分的参数
"n_layers_q": 3,
"use_spectral_norm": false
}
}
文本编码器(text encoder)
VITS的文本编码器(text encoder)负责将输入的文本序列转化为低维的文本特征表示,以供后续的语音合成模块使用。文本编码器采用了Transformer结构,具有多头自注意力机制和前馈神经网络层。
下面是VITS文本编码器的详细介绍:
1. 输入嵌入(Input Embedding):首先,输入的文本序列经过一个嵌入层,将每个单词转换为固定维度的向量表示。这个嵌入层可以是预训练的词向量模型,也可以是随机初始化的词向量。
2. 位置编码(Positional Encoding):为了将序列的位置信息引入模型,位置编码被添加到输入嵌入中。位置编码是一组固定的向量,其中每个向量对应于输入序列中的一个位置。
3. 编码层(Encoder Layer):文本编码器由多个编码层组成,每个编码层都包含了自注意力机制和前馈神经网络层。
– 自注意力机制(Self-Attention):自注意力机制允许模型在编码过程中关注输入序列中的不同位置,并学习它们之间的关系。它通过计算每个位置与其他位置的注意力权重来实现。这样,模型可以在编码过程中根据上下文信息动态地调整每个位置的表示。
– 前馈神经网络层(Feed-Forward Network):前馈神经网络层是编码层的另一个重要组成部分,它通过两个线性变换和一个非线性激活函数来对自注意力机制的输出进行进一步的处理和组合。这个前馈神经网络层可以增强模型的非线性建模能力。
4. 编码器输出:经过多个编码层的处理,文本编码器的最终输出是一个低维的文本特征表示,它捕捉了输入文本序列的语义和上下文信息。这个文本特征表示将被用作语音合成模块的输入,以生成相应的语音。
通过文本编码器,VITS可以将输入的文本序列转化为高质量、低维的文本特征表示,为语音合成过程提供了有价值的信息。这样的设计使得VITS能够实现端到端的语音合成,并在合成质量和表达能力方面取得了显著的提升。
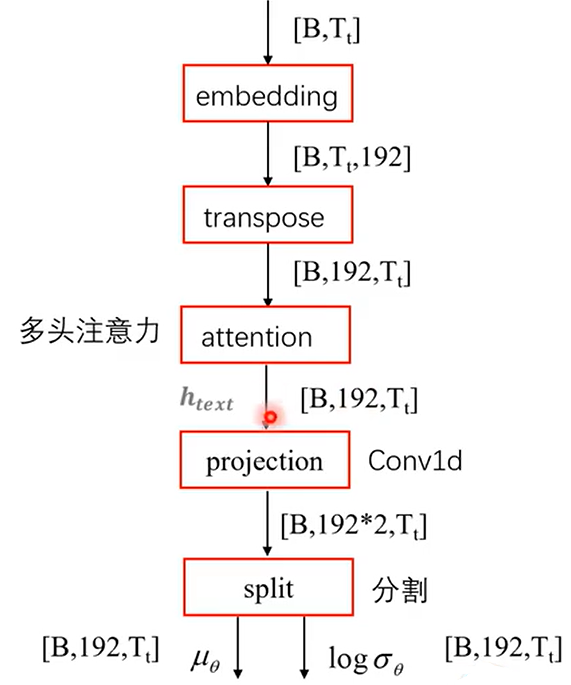
用图表示就是这样,其代码在model.py的137行到176行,注释如下
class TextEncoder(nn.Module):
def __init__(self,
n_vocab,
out_channels,
hidden_channels,
filter_channels,
n_heads,
n_layers,
kernel_size,
p_dropout):
super().__init__()
self.n_vocab = n_vocab
self.out_channels = out_channels
self.hidden_channels = hidden_channels
self.filter_channels = filter_channels
self.n_heads = n_heads
self.n_layers = n_layers
self.kernel_size = kernel_size
self.p_dropout = p_dropout
# 文本嵌入层
self.emb = nn.Embedding(n_vocab, hidden_channels)
nn.init.normal_(self.emb.weight, 0.0, hidden_channels**-0.5)
# 编码器层
self.encoder = attentions.Encoder(
hidden_channels,
filter_channels,
n_heads,
n_layers,
kernel_size,
p_dropout)
# 投影层,将编码器输出转换为指定维度的特征表示
self.proj= nn.Conv1d(hidden_channels, out_channels * 2, 1)
def forward(self, x, x_lengths):
# 文本嵌入
x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h]
x = torch.transpose(x, 1, -1) # [b, h, t]
# 创建掩码,用于屏蔽填充位置的信息
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
# 编码器层的前向传播
x = self.encoder(x * x_mask, x_mask)
# 投影层,将编码器输出转换为特征表示
stats = self.proj(x) * x_mask
# 将特征表示分为两部分,用于生成均值和标准差
m, logs = torch.split(stats, self.out_channels, dim=1)
return x, m, logs, x_mask
1. `__init__`函数:初始化文本编码器的参数,并构造相关的层和模块。其中:
– `n_vocab`:词汇表大小,表示可表示的单词数量。
– `out_channels`:输出特征的通道数。
– `hidden_channels`:隐藏层的通道数。
– `filter_channels`:滤波器层的通道数。
– `n_heads`:自注意力机制的头数。
– `n_layers`:编码器层数。
– `kernel_size`:卷积层的核大小。
– `p_dropout`:dropout的概率。
2. `forward`函数:定义了文本编码器的前向传播过程。其中:
– `x`:输入的文本序列,shape为`[batch_size, seq_len]`。
– `x_lengths`:输入文本序列的实际长度,shape为`[batch_size]`。
在前向传播过程中,具体的操作包括:
– 文本嵌入层:将输入的文本序列进行嵌入操作,将每个单词转换为固定维度的向量表示。
– 文本序列维度转置:将嵌入后的文本序列的维度进行转置,以适应编码器的输入要求。
– 创建掩码:通过填充的位置信息,创建一个掩码矩阵,用于屏蔽填充位置的信息。
– 编码器层:对嵌入后的文本序列进行编码操作,使用自注意力机制和前馈神经网络层。
– 投影层:将编码器的输出转换为指定维度的特征表示。
– 特征表示分割:将特征表示分为两部分,用于生成均值和标准差。
最终,函数返回编码器的输出结果,包括编码器的输出、均值、标准差和掩码矩阵。
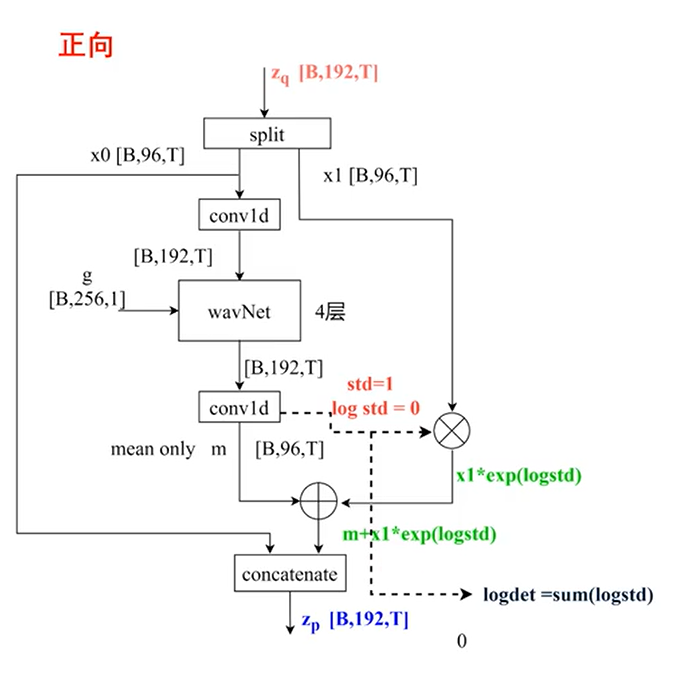
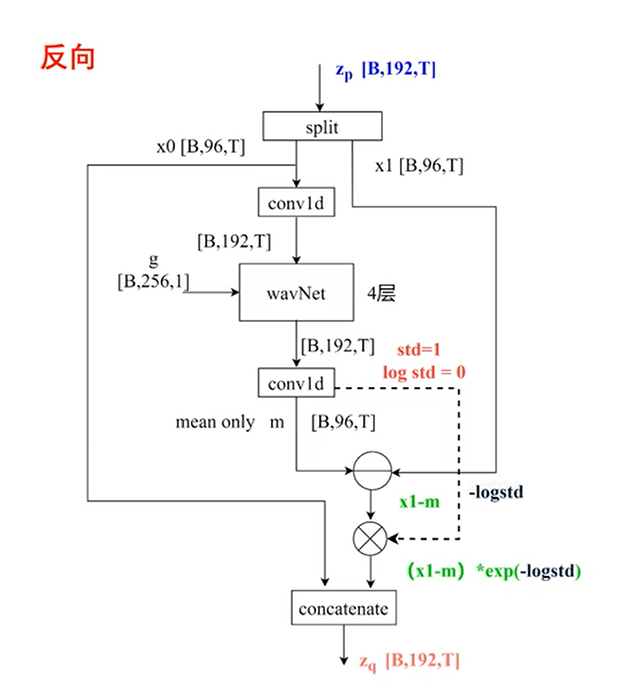
flow
class ResidualCouplingBlock(nn.Module):
def __init__(self, channels, hidden_channels, kernel_size, dilation_rate, n_layers, n_flows=4, gin_channels=0):
super().__init__()
self.channels = channels # 输入特征的通道数
self.hidden_channels = hidden_channels # 隐藏层的通道数
self.kernel_size = kernel_size # 卷积核大小
self.dilation_rate = dilation_rate # 膨胀率
self.n_layers = n_layers # 残差层数
self.n_flows = n_flows # Flow层数
self.gin_channels = gin_channels # 全局特征的通道数
self.flows = nn.ModuleList()
for i in range(n_flows):
self.flows.append(modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels, mean_only=True))
self.flows.append(modules.Flip())
在`__init__`函数中,初始化了ResidualCouplingBlock类的各个属性。其中,channels表示输入特征的通道数,hidden_channels表示隐藏层的通道数,kernel_size表示卷积核大小,dilation_rate表示膨胀率,n_layers表示残差层数,n_flows表示Flow层数,gin_channels表示全局特征的通道数。
接下来,通过nn.ModuleList()创建了一个空的ModuleList对象self.flows,用于存储Flow层的组件。然后,使用for循环,依次创建n_flows个ResidualCouplingLayer和Flip层的实例,并将它们添加到self.flows中。
def forward(self, x, x_mask, g=None, reverse=False):
if not reverse:
for flow in self.flows:
x, _ = flow(x, x_mask, g=g, reverse=reverse)
else:
for flow in reversed(self.flows):
x = flow(x, x_mask, g=g, reverse=reverse)
return x
在forward函数中,实现了ResidualCouplingBlock类的前向传播逻辑。当reverse为False时,按顺序遍历self.flows中的每个flow,并调用其forward方法,将输入x、x_mask和全局特征g传递给flow,并将返回的结果更新为新的x。在这个过程中,_变量用于存储一些中间结果,但在这段代码中没有被使用到。
当reverse为True时,以相反的顺序遍历self.flows中的每个flow,并依次调用其forward方法,同样将输入x、x_mask和全局特征g传递给flow,并将返回的结果更新为新的x。
最后,返回最终的x作为输出。
这段代码实现了Flow模块中的一个Residual Coupling Block,通过多个Residual Coupling Layer和Flip层的组合,实现了文本到声学特征的映射。
图示如下
Comments NOTHING