


自监督模型和之前模型的不同之处在于,之前的模型在输入的时候是有标签的,比如文章正负面评价的例子,在输入文章的时候还要告诉模型对应的句子是正面还是负面的。自监督模型则是将输入拆为两部分,一部分作为输入,一部分作为标签以此来和输出对比。
需要注意的是自监督模型属于无监督模型的一种,并不是和无监督学习画等号。
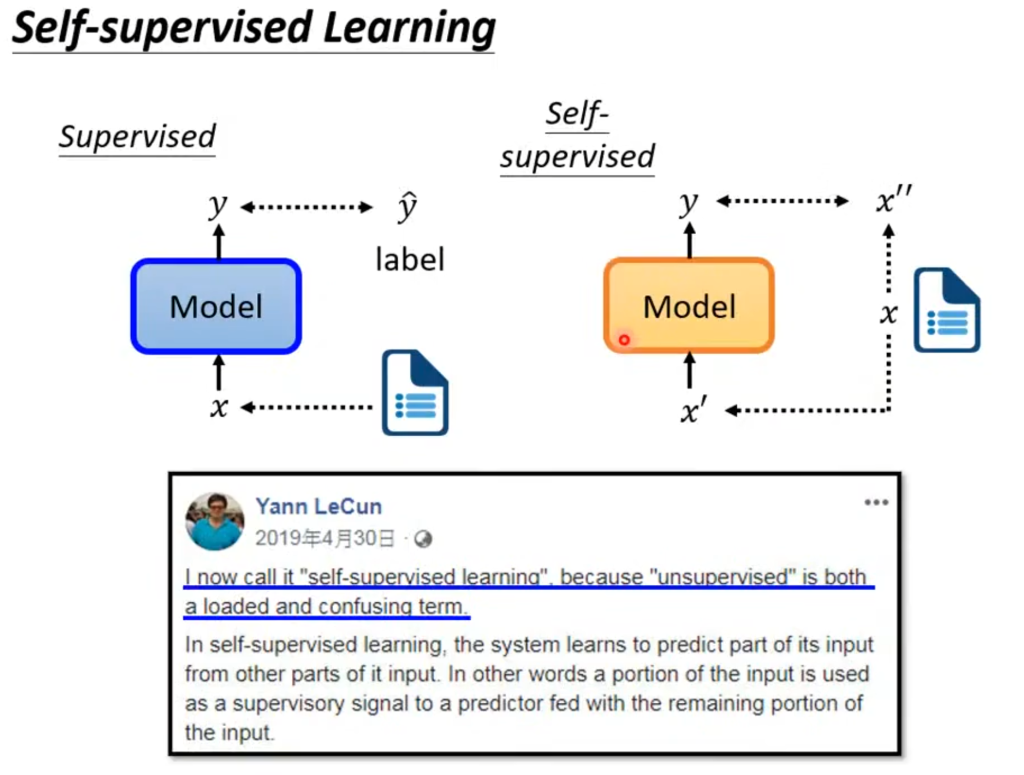
举个例子吧,例如输入台湾大学,经过BERT(结构和Transformer 的Encoder一样),输出同样数量的输出层。它会先随机盖住(masked)一个字(token),盖住的方法可以是用特殊字符替代,也可以是用一个随机的字替代。然后被盖住输出对应的输出经过乘一个矩阵(Linear)再softmax得到一排概率分布,表示被遮住的字是某字的概率。
那要怎么自学习呢?我们是知道被盖住的字是“湾”,但机器不知道,机器会挑出最有可能的字,然后和正确的“湾”做差距,以此判断学习效果。
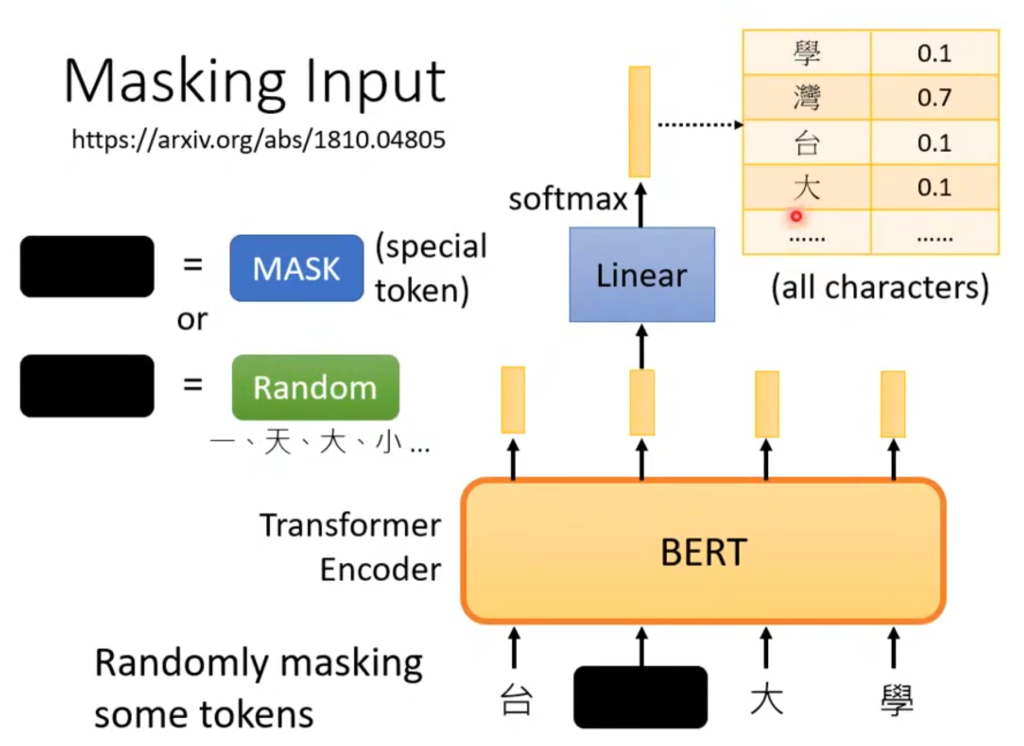
除了遮住一个字之外呢,还会判断某句是否是接下来的一个句子。机器会在测试的两个句子前加上CLS和SEP的符号,然后将CLS对应的输出做一个二元分类问题,如果接下来的两个句子是紧接着的,就输出yes。
但这个训练的效果目前看来并不能学到什么东西,但它的一个改版,也就是判断把两个句子位置颠倒,让机器判断哪个是正确顺序的一个训练(叫SOP)在ALBERT模型里有很大作用。
既然判断句子连接没学到什么东西,那BERT真正学到的就是“填空”,那如果我的要求不是填空岂不是没用了?
但实际上,只要会“填空”,BERT就可以分化来解决很多不同的任务,这个分化称为微调(Fine-tune),而微调之前训练BERT的过程就叫做预训练(Pre-train)
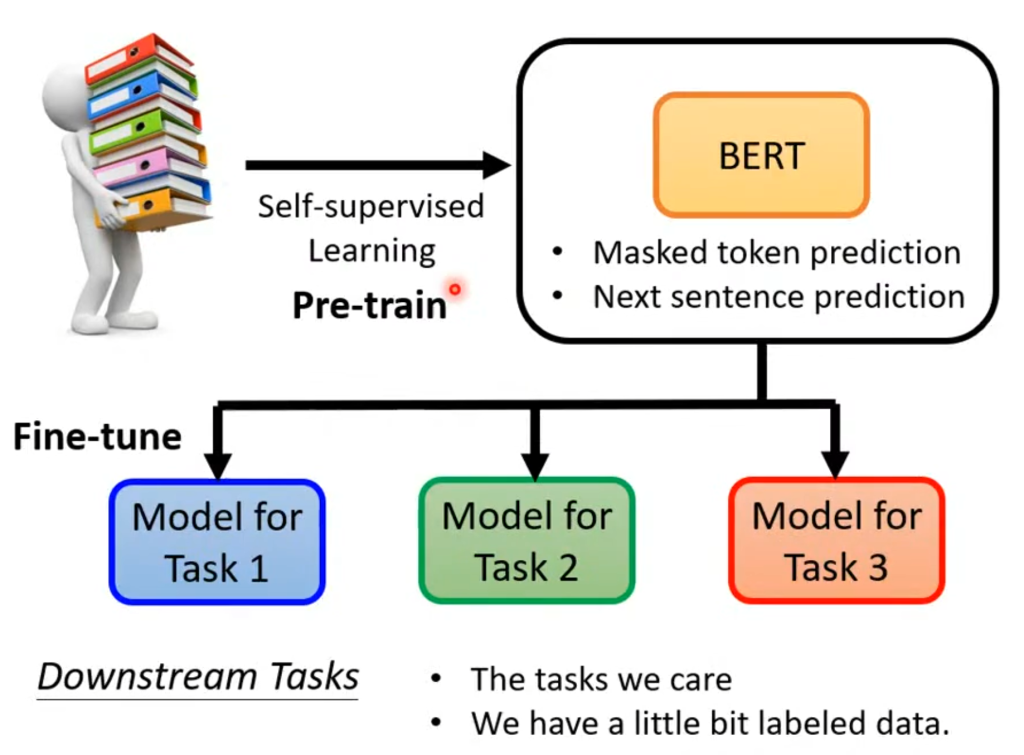
在实际测试中,有预训练的模型和所有参数初始都是随机的模型相比,不仅Loss下降的快,最终的Loss也会更小。
并且BERT在训练填空能力的时候用的是无监督学习,在微调任务时可能会有到有监督学习,因此整体算是半监督模型
Comments NOTHING