


trainsformer解决的是序列到序列的问题,也就是上一章说的输入的向量数量和输出的向量数量不一致的情况。
比如语音识别,机器翻译,以及语音翻译。那为什么不把前面两个加起来而是要再做一个语音翻译呢?因为世界上有很多语言是没有文字的,所以需要一个输入发言输出翻译的模型。
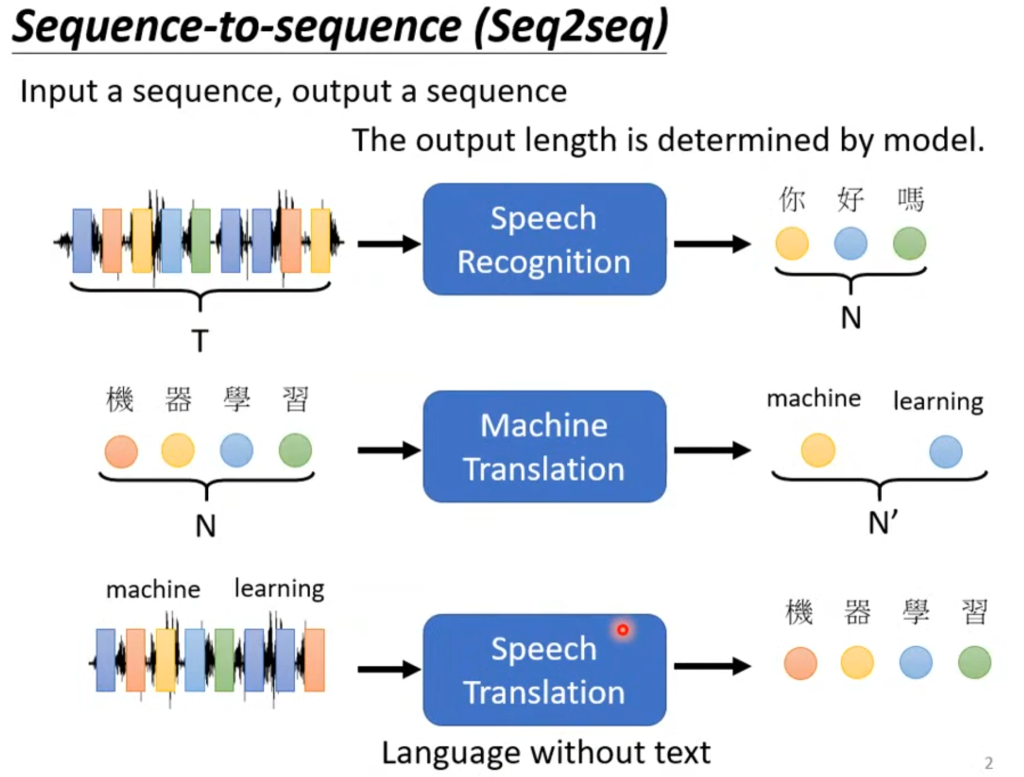
序列到序列还可以应用在聊天机器人上面,只要你收集大量问答资料,然后告诉它输入“Hi”就要输出“Hello”,等等。
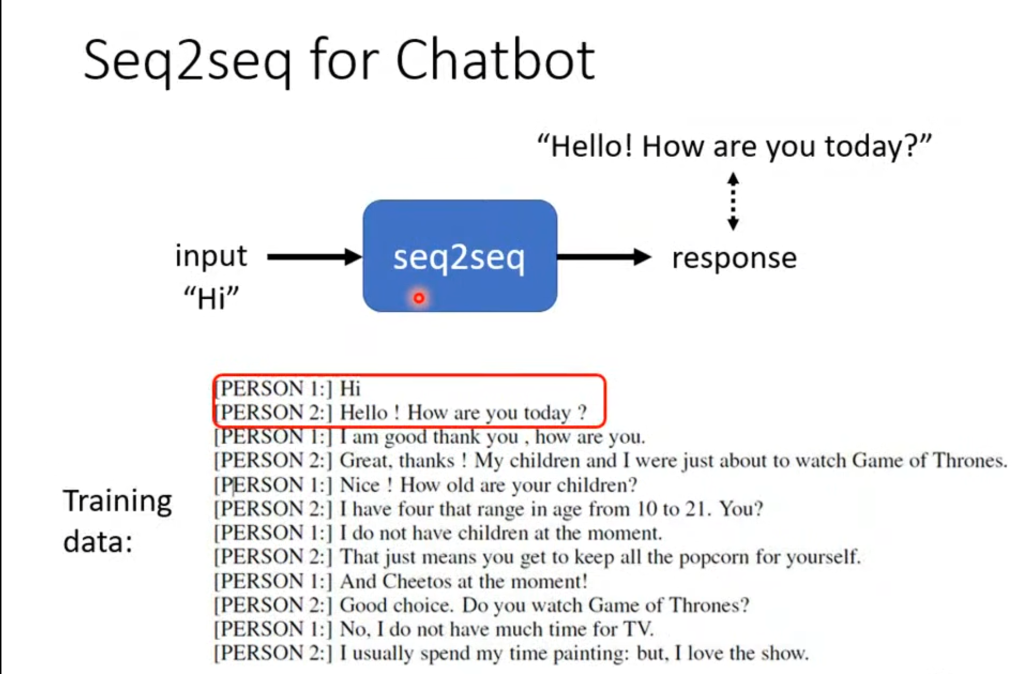
而在自然语言处理领域(NLP),序列到序列的应用就更加广泛。
NLP领域的问题其实都是一个QA的问题,QA的意思是给机器读一段文本,然后问一个问题,要求给出回答。其实很多问题意想不到的都可以用QA问题来解释,比如翻译问题就是给一段文本,然后问这段话的翻译是什么;比如给一段文本,然后问这段话是正面评价还是负面评价。
而seq2seq就可以用来解决QA问题。这相当于一个输入层为文本和问题、输出层为回答的神经网络。
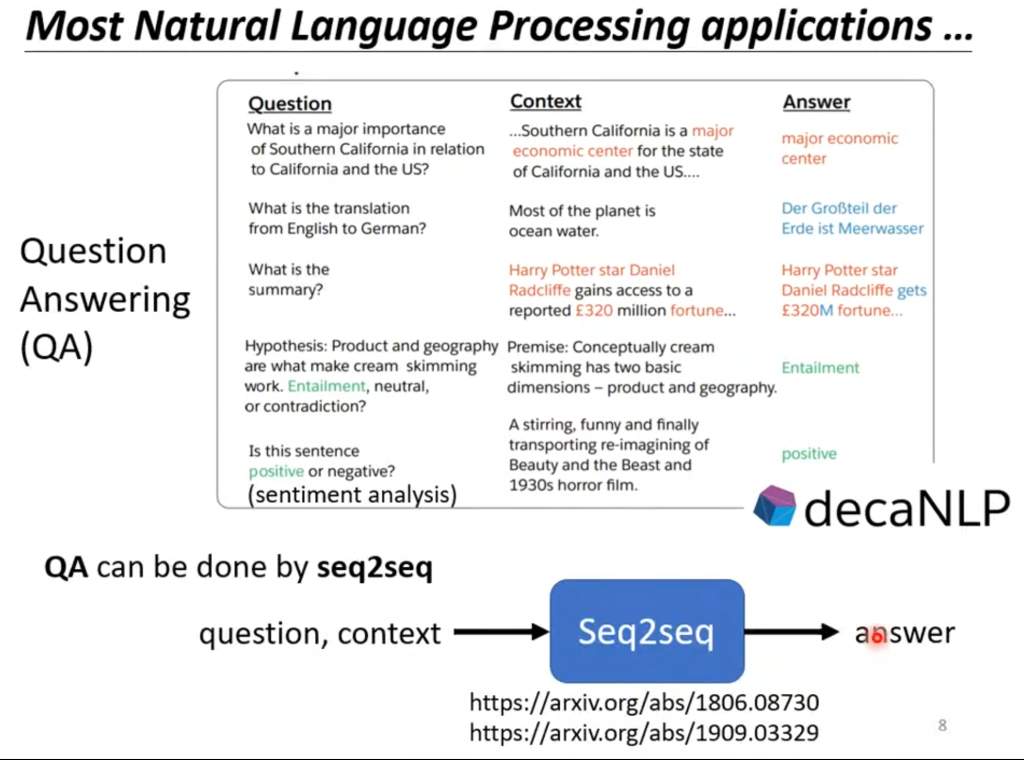
seq2seq可以用来解决很多问题,例如多标签分类问题,他判断一个输入可以属于多个类别。例如图像检测,它判断图像里有几只猫。
seq2seq结构
seq2seq的结构分为encoder和decoder两部分。而一般seq2seq问题就是用transformer解决的。
因此接下来介绍的是transformer的结构。
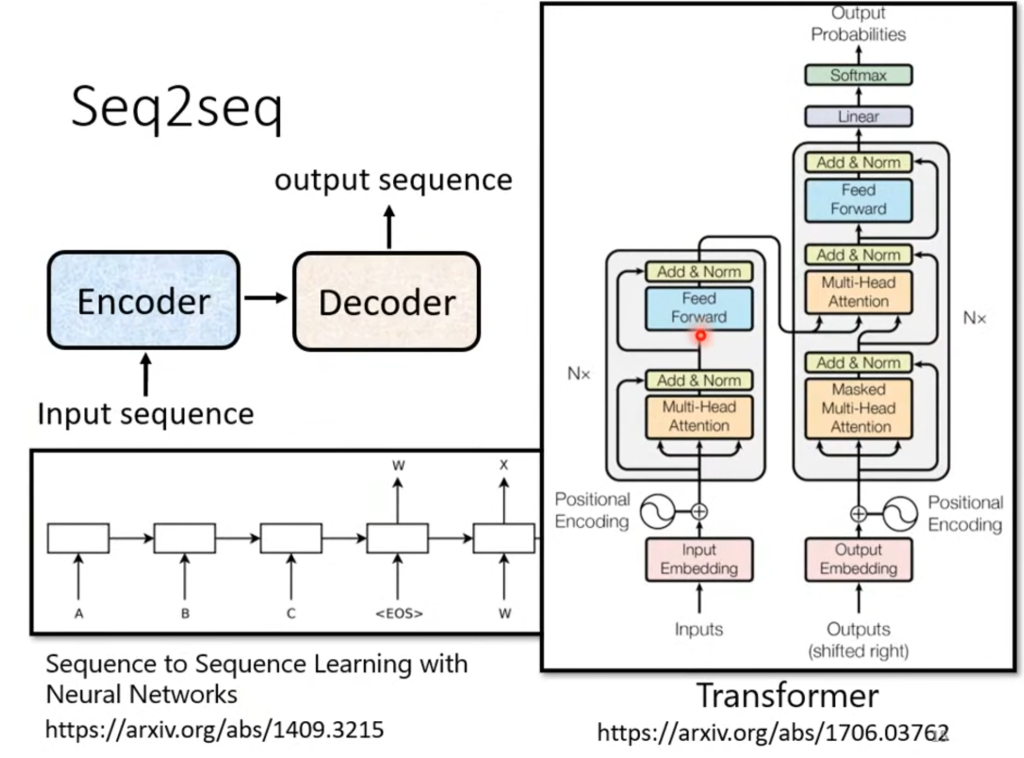
Encoder
Encoder的作用是输入一堆向量,然后输出同样数量的向量,这个功能RNN、CNN、自注意力机制都能做到,Transformer用的是自注意力机制。
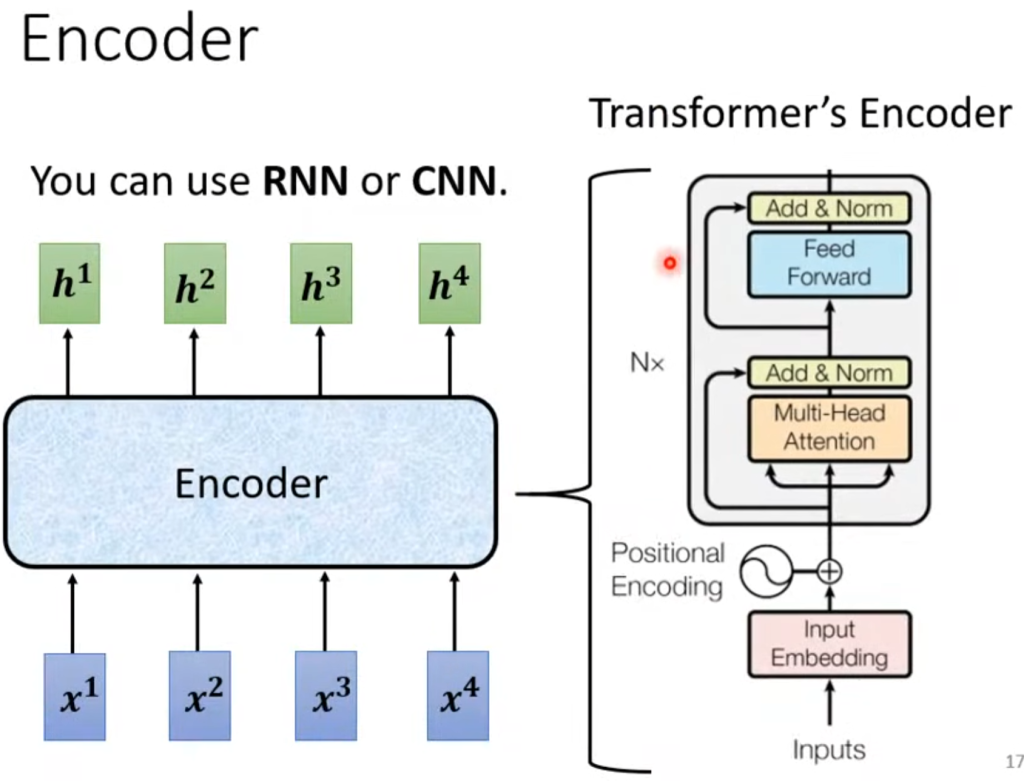
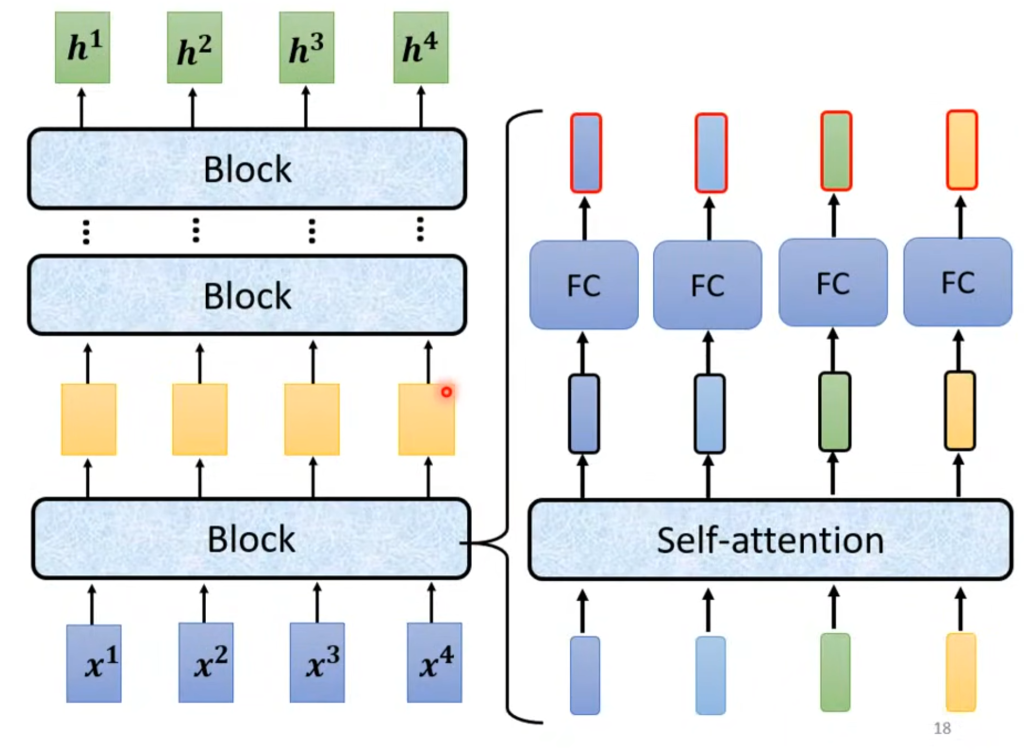
Encoder的内部结构如图所示,里面有非常多层的Block,每一个Block做的事情是经过自注意力层后再经过一个全连接层
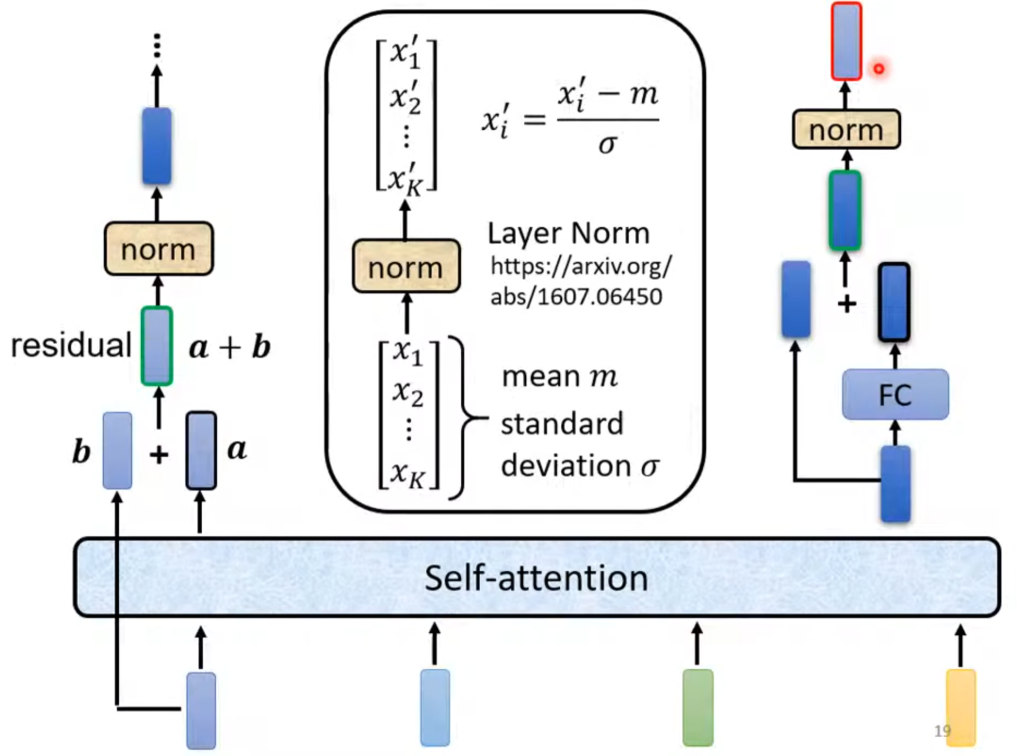
更具体的说,在经过了自注意力层后输出会和原输入进行一次相加(这有个专业术语叫残余residual,应用非常广泛),然后再进行一次标准化,(原式-平均值)/标准差,标准化后的结果才是FC的输入端,而经过FC后又会进行一次residual和标准化,最后得到的才是一个Block的输出结果。
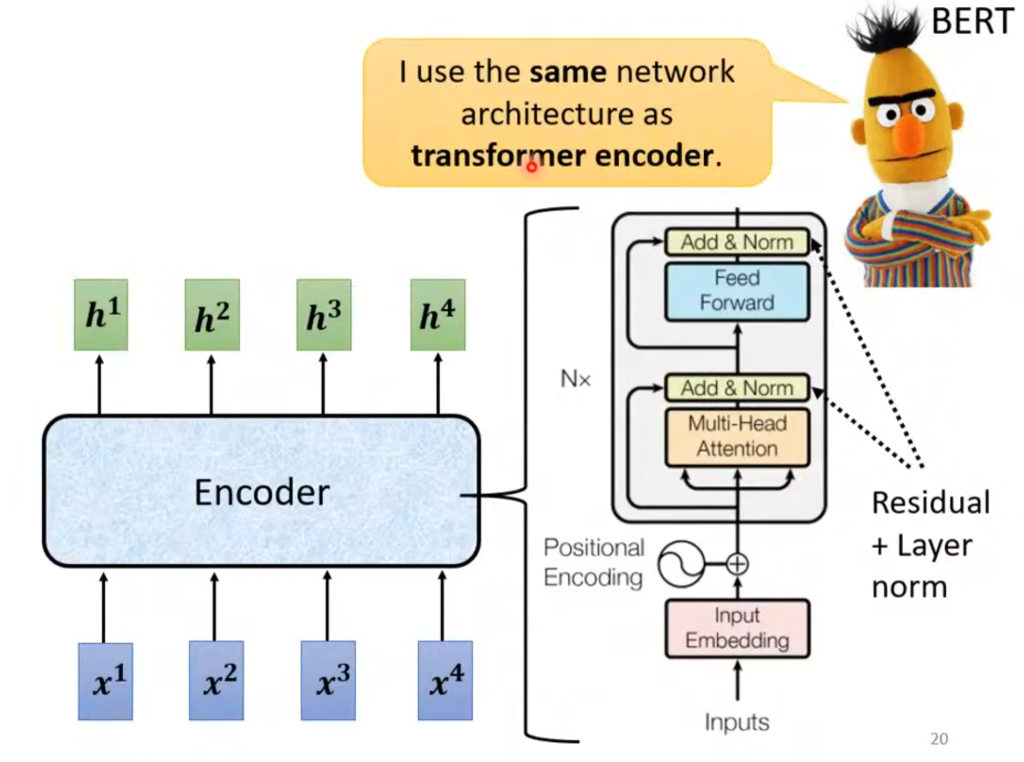
现在我们回到最开始的图,在输入之后先经过位置编码(Positional encoding)。
为什么要用位置编码呢?因为接下来是自注意力机制,优点是可以考虑整体,缺点是各个输入之间没有顺序,但文本输入是有顺序的,所以必须要用位置编码来确定位置信息。
接着就是上一张图讲到的残余+标准化,然后经过一个FC再进行残余+标准化。
Decoder
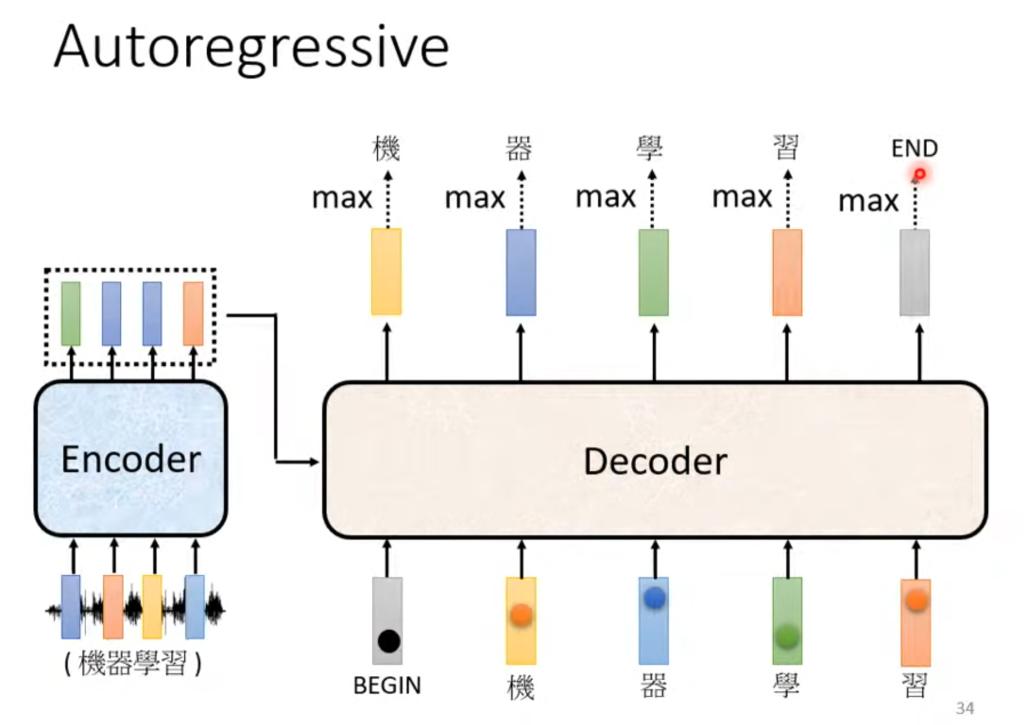
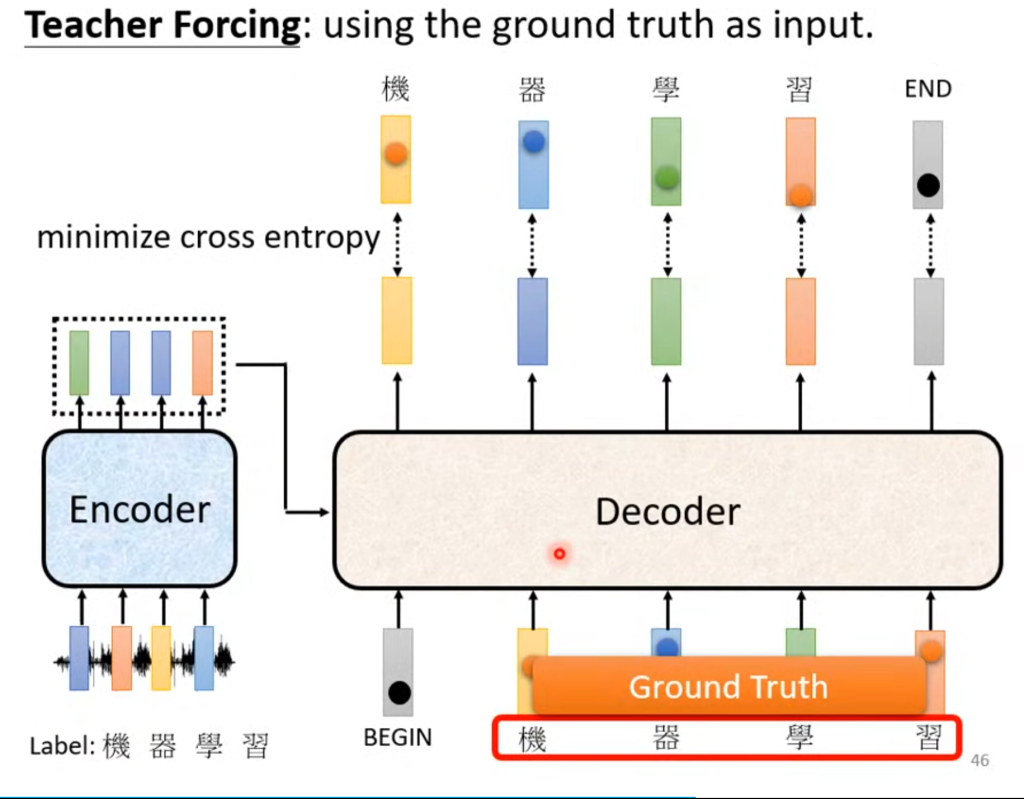
经过Encoder的结果传入Decoder,拿语音识别举例,它的输出是一个包含所有汉字的向量,每个数代表输出这个汉字的概率。
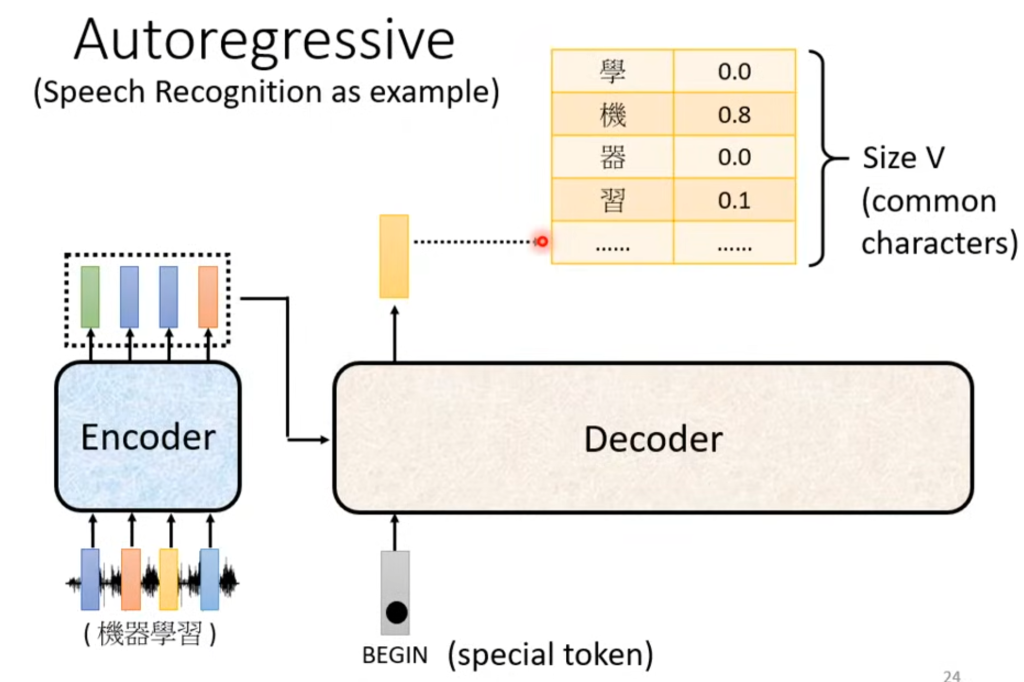
在第一个输出后,将该输出作为下一个输入,以此类推。
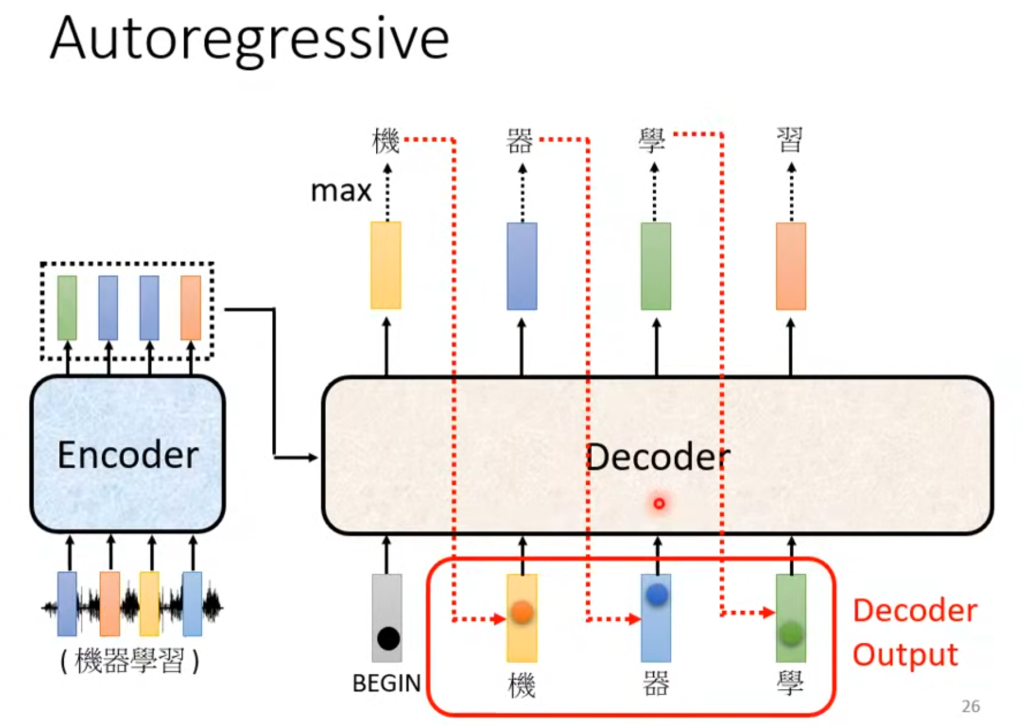
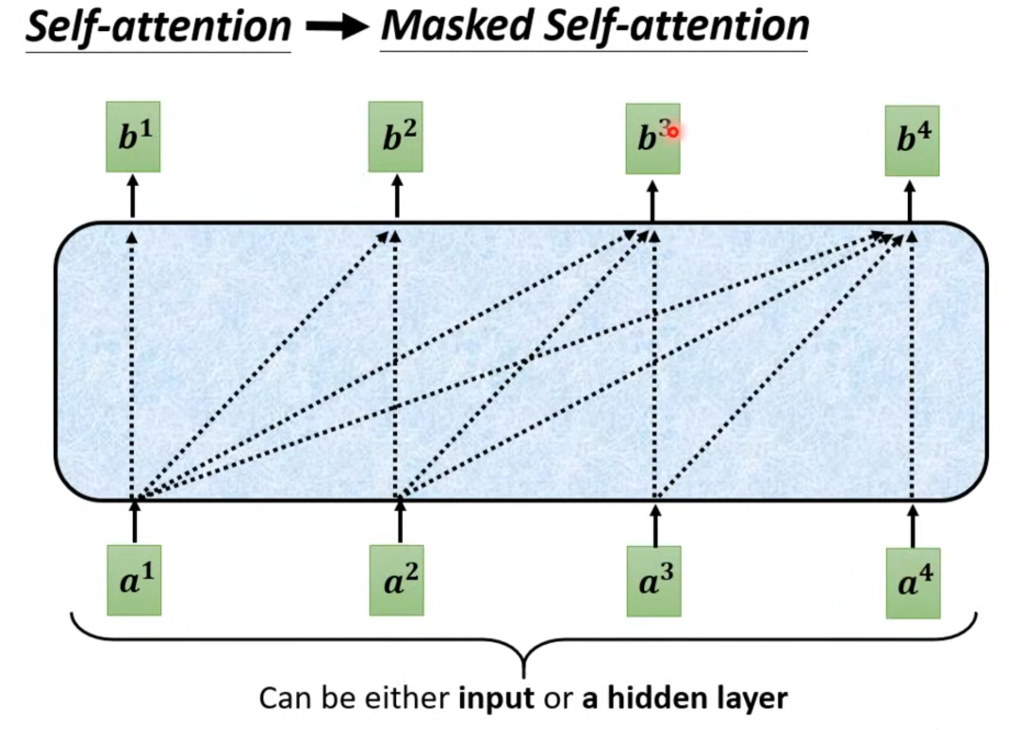
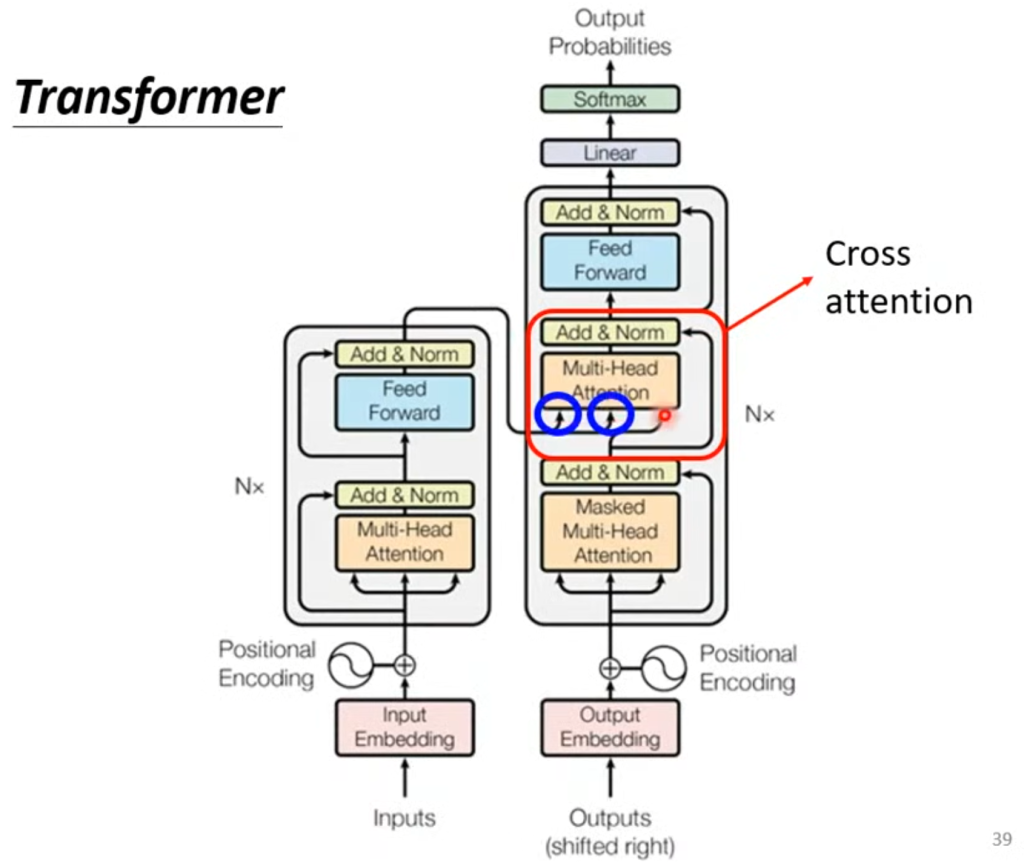
Decoder的结构遮住中间这部分其实和Encode差不多,在多头注意力这层改成了masked self-attention,意思是算输出的时候只考虑左边不考虑右边。
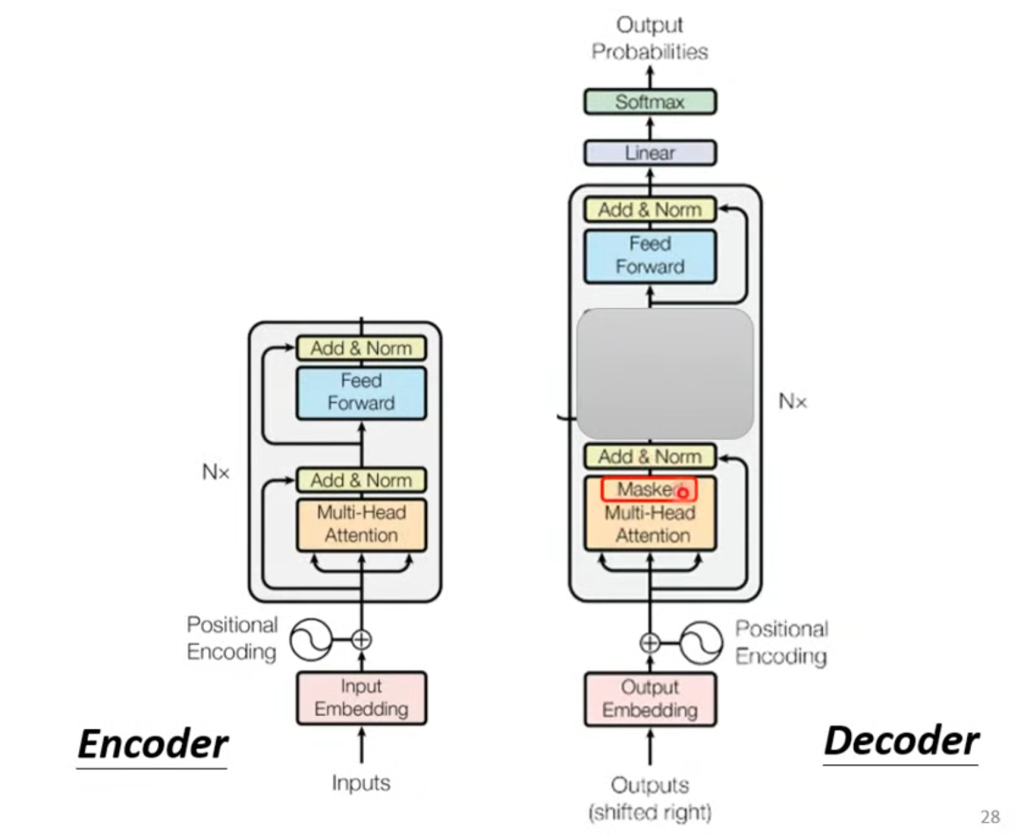
具体训练情况如图,也就是把“全连接”砍成只连接左边的输入了。
当然还有个问题,那就是输出的个数是由机器自己决定的,所以需要一个终止符号,这个终止符号和汉字在一起,当需要终止的时候,输出终止符的概率最大。
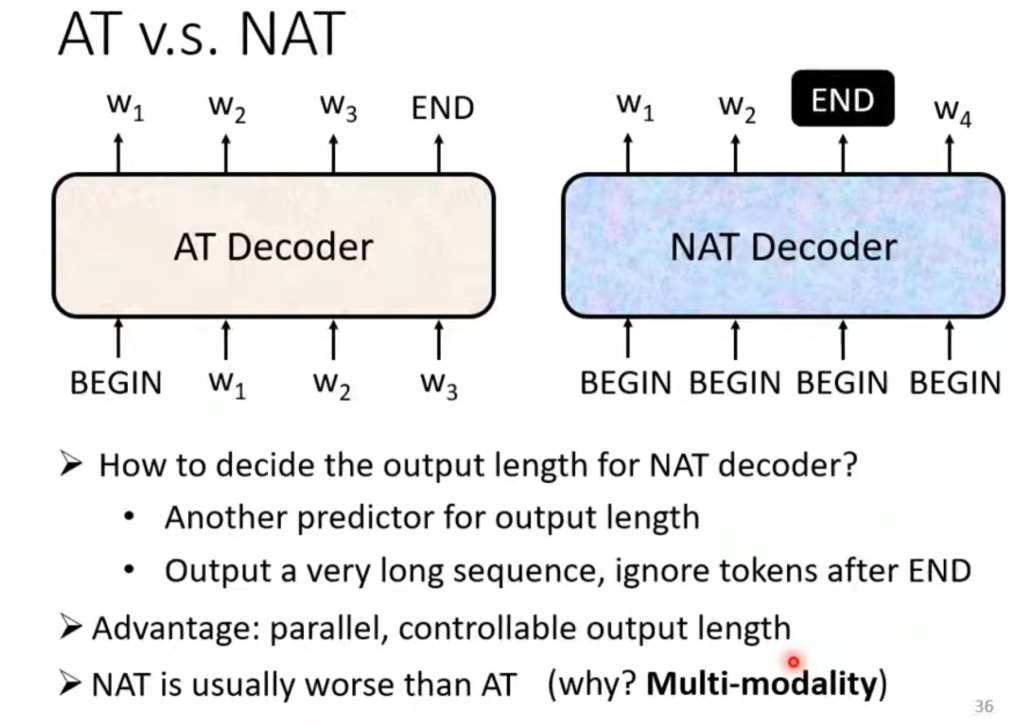
而Decoder又分为自回归(AT)和非自回归(NAT)两种。
AT在输入BEGIN后会将输出作为下一次的输入继续执行;NAT会一次输入一堆BEGIN,然后同时输出。但是上面讲到过,我们并不清楚输出的个数具体是多少,因此有两种方法:一种是Encoder的输入由多少个就给多少个BEGIN,另一种是限定输出的长度,例如判断输出的文本绝对不超过30个字,那就输入三十个BEGIN,然后END在哪里END后面的就都不要了。
NAT的优点有很多,因为它是平行输出,所以速度会快很多;还可以限制输出的长度。但目前NAT的效果普遍不如AT。
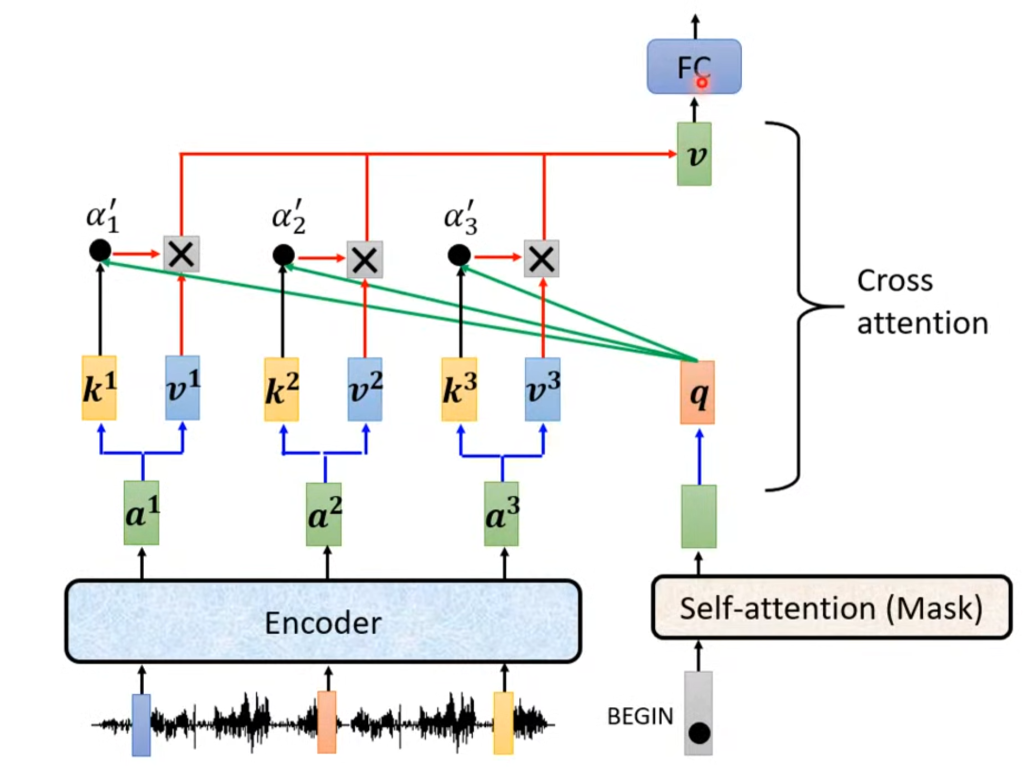
接下来我们讲之前被遮住的那一部分,叫做Cross attention这部分用来接受Encoder的输出,也就是将Encoder和Decoder连接起来的部分。从图中可以看出,该部分的输入有两部分来自Encoder,
Encoder的输出分别×矩阵Wk、Wv得到k1.k2.k3和v1.v2.v3,这些k再和q相乘得到相关度。在Decoder这边经过masked self-attention的结果×矩阵Wq得到q,最后相关度和这些v相乘相加得到最终的v。因此,来自Encoder的两个输入是k和v,来自Decoder的一个输入是q。
总体来看Decoder的输入和输出就可以发现,其实正确答案已经在Decoder的输入层了。这其实涉及到一个问题,后面再说。
在很多情况下,我们可能需要机器具有“复制能力(Copy Mechanism)”,例如在对话机器人的应用中,机器并不知道库洛洛是什么意思,他需要的是把库洛洛从输入层复制过来,换句话讲库洛洛并不是机器自己产生的。
包括摘要生成也是,很多摘要里的东西都是从文章中直接复制的。

Comments NOTHING