


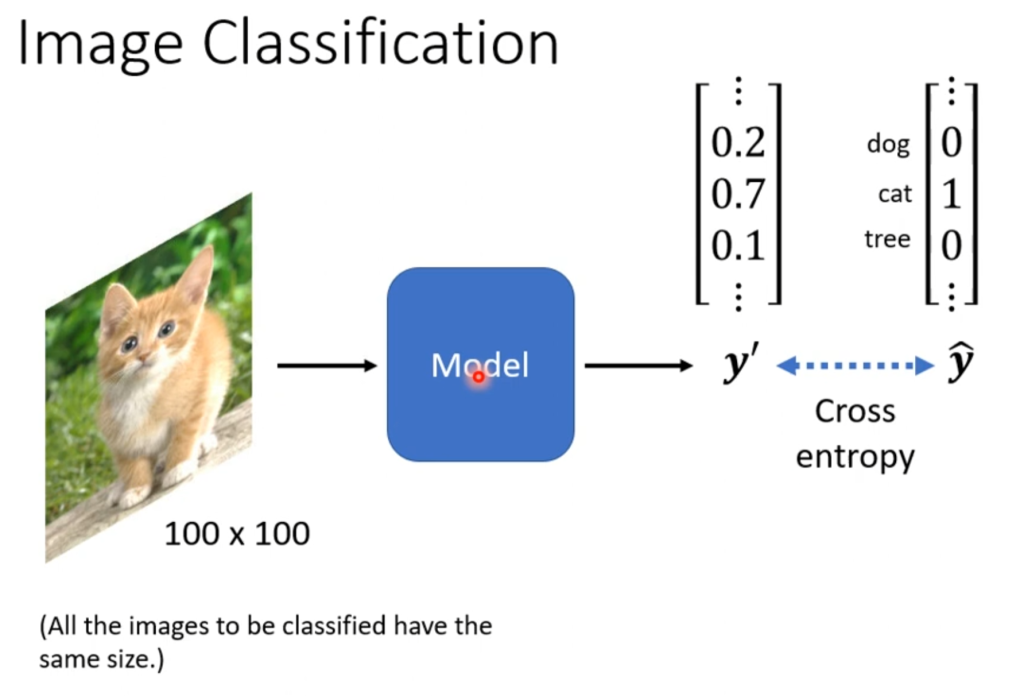
CNN属于分类问题,输出为一个向量,正确输出为一个为1其余全0的向量,训练输出包含小数,代表是这个分类的概率。
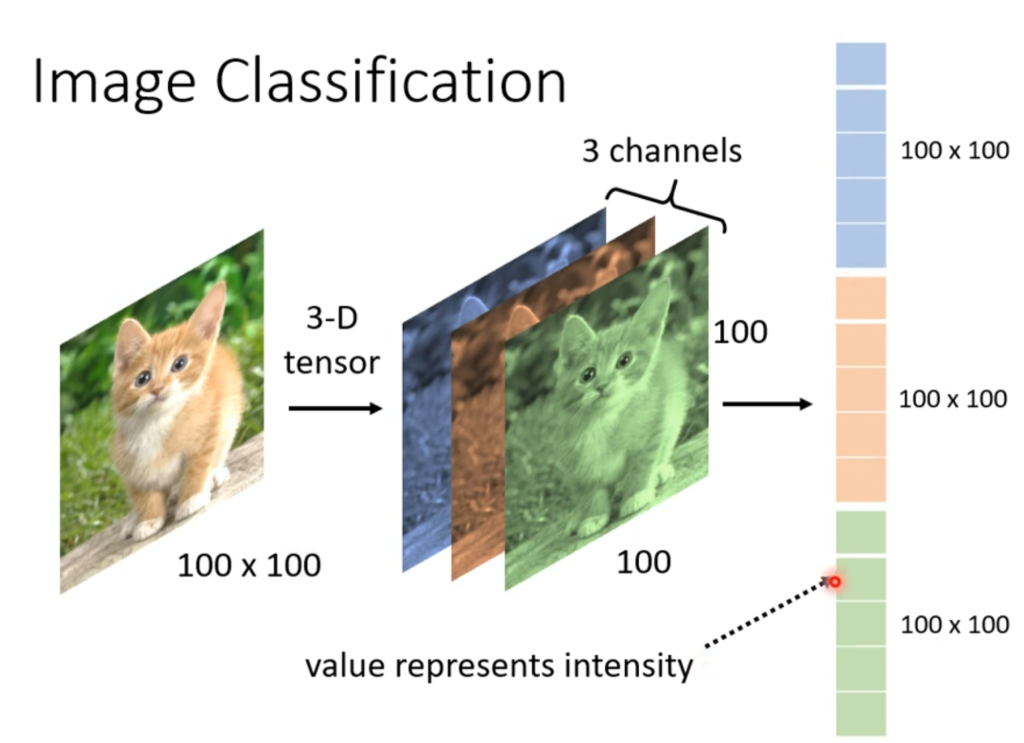
对于计算机来说,图片就是一个三维的矩阵,其中的两维代表长和宽,剩下一维代表颜色,而所有的颜色都由rgb三原色组成,因此,如果一个图片是100x100像素的话,那这张图片在计算机眼里就是100x100x3的矩阵。其中矩阵的每一个值都代表一个原色的颜色强度。
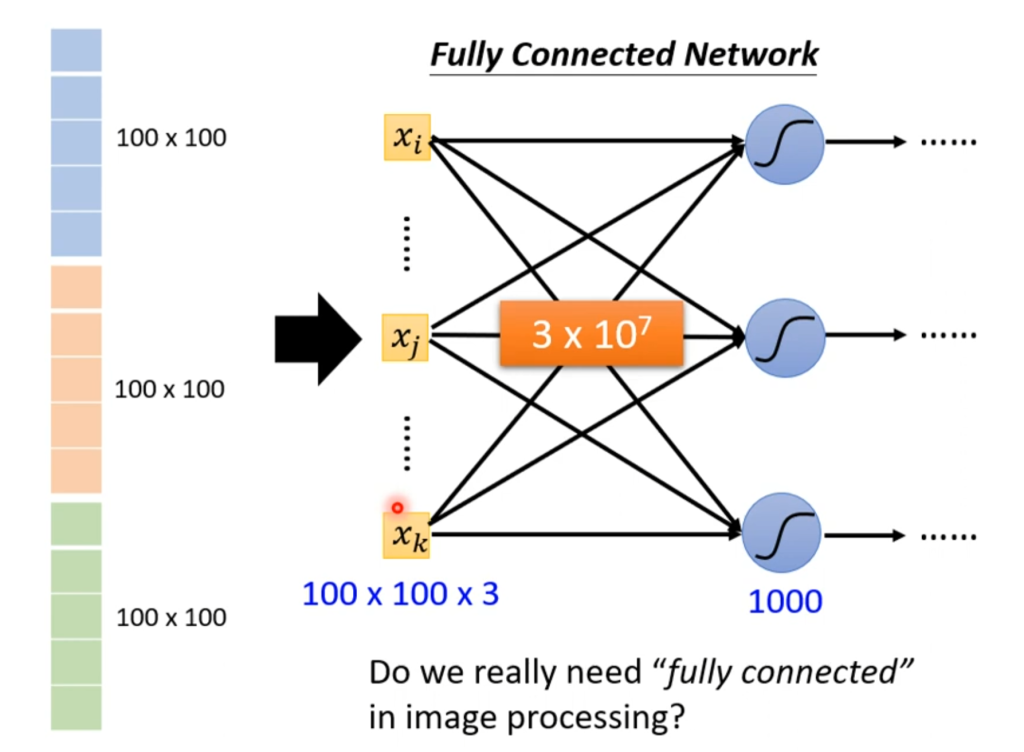
我们将这个三维矩阵作为输入,假设有一千个神经元,那就有3×10的七次方个w,随着参数的增加,模型的弹性也会增加,但过拟合的风险也会增加。
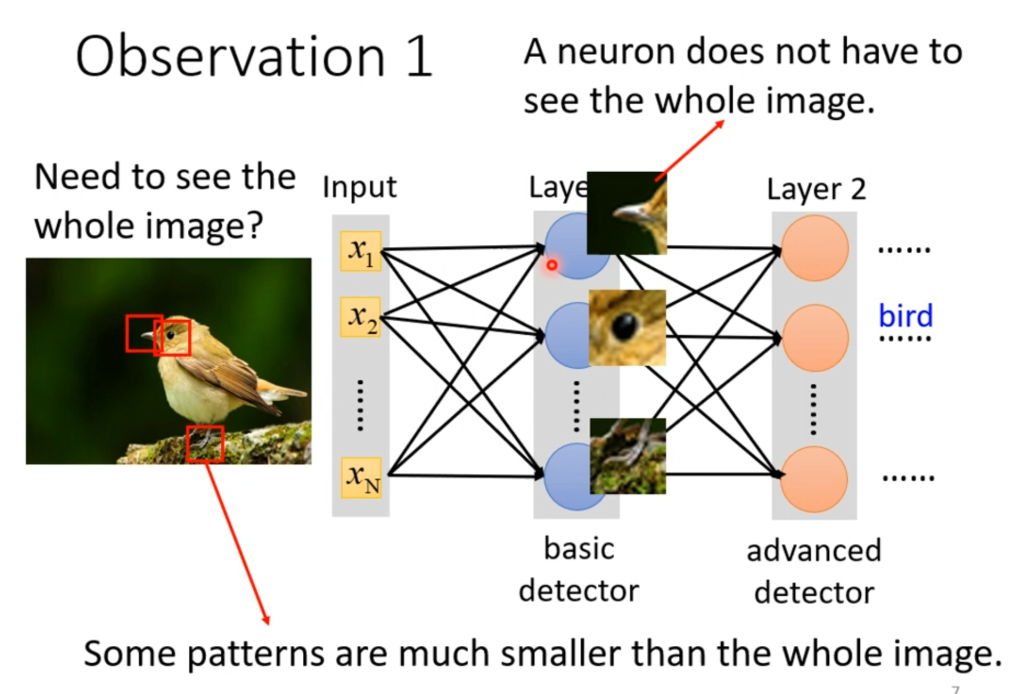
事实上,我们并不需要全连接。在图片识别中,并不需要将整幅图像全部看完,例如只需要看到鸟嘴,眼睛,爪子,就可以判断这是一只鸟,图片其他的部分不需要看。
具体到三维矩阵中,就是一个神经元只需要看它对应的接受域(receptive field),然后把这个部分区域输入到神经元中
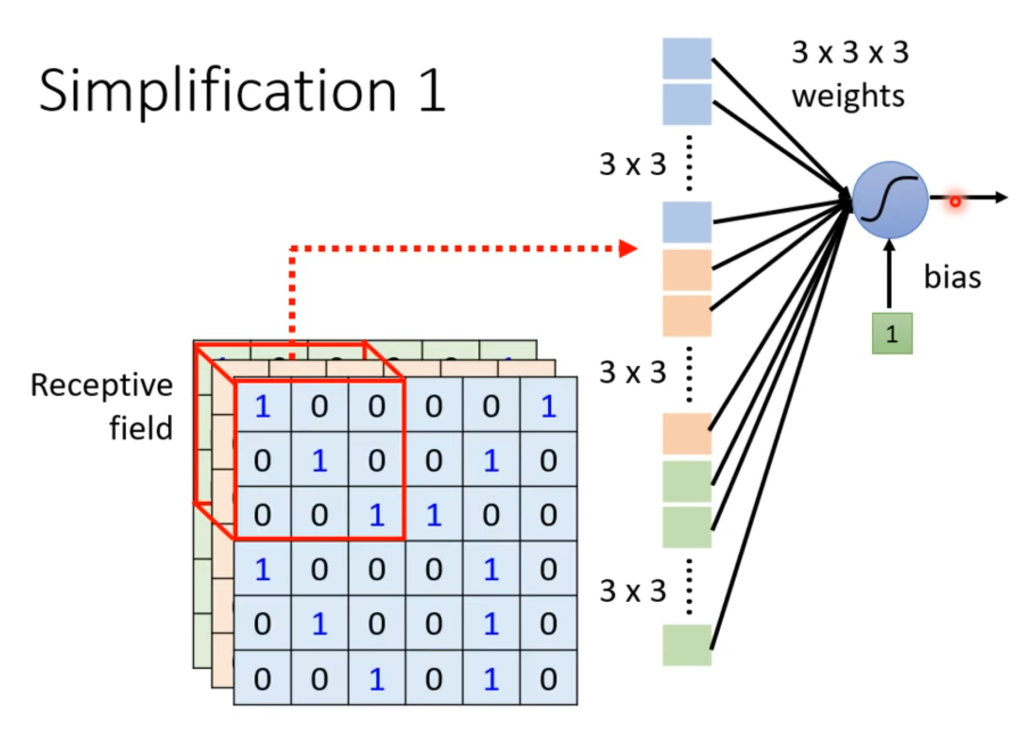
这个接受域长什么样由自己决定,它可以在角落,可以有大有小,可以与其他接受域有重叠部分,也可以完全重叠,都是根据实际情况来的,例如判断是否为鸟,那角落的部分参考价值可能不是很大。
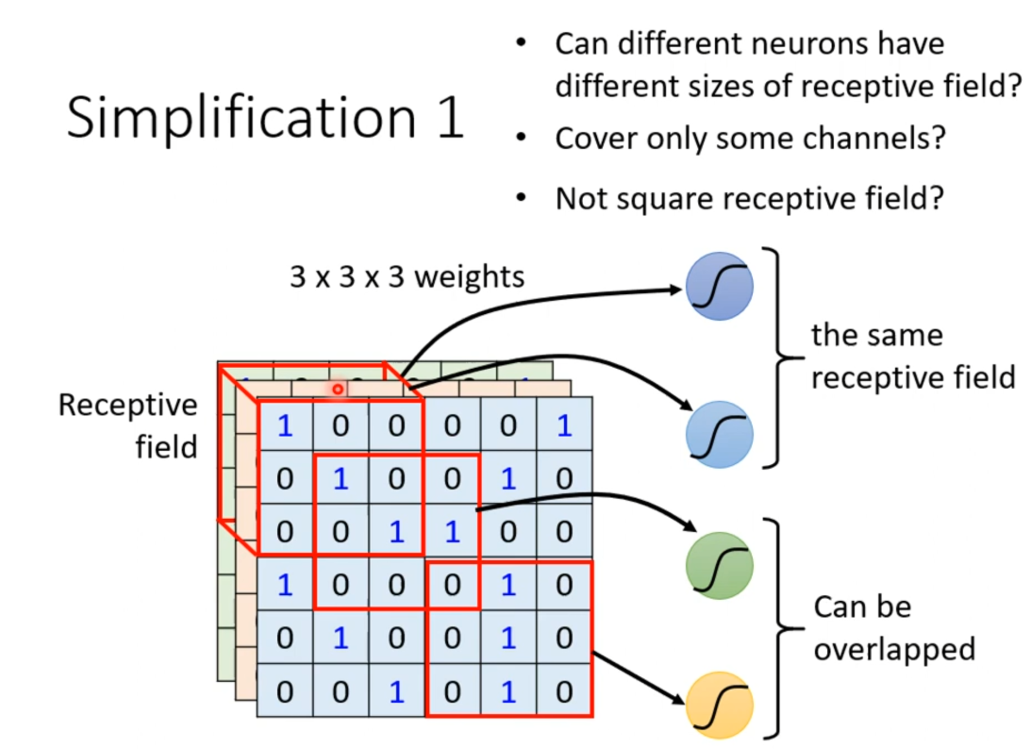
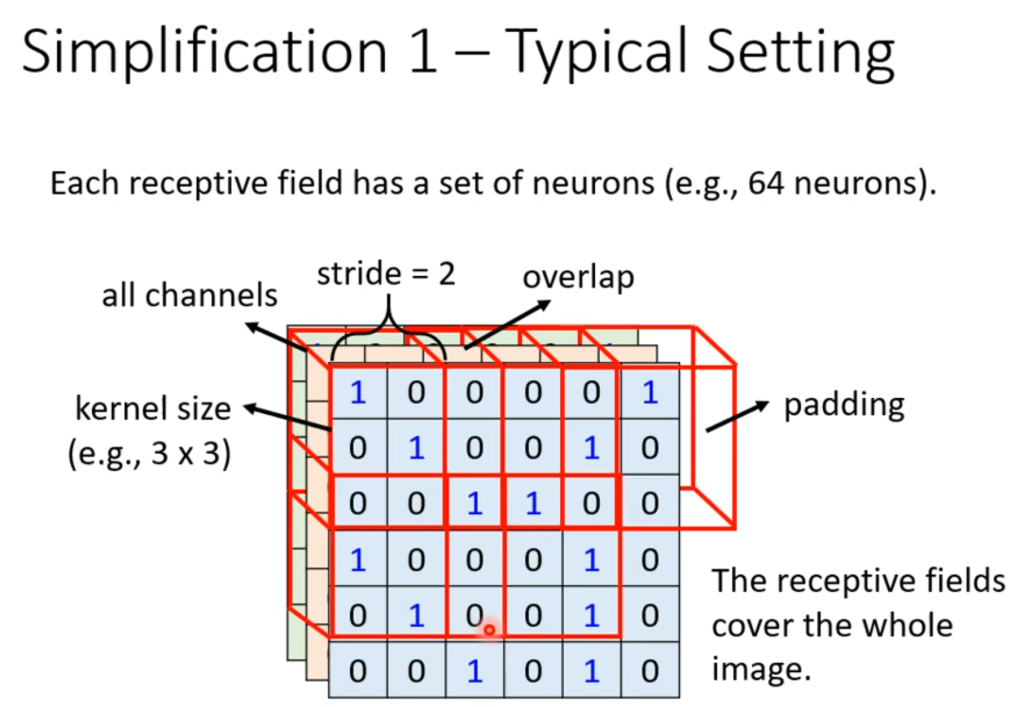
一个比较经典的接受域划法是从左上角开始划一个3×3的接受域(颜色维度全部划入),然后以stride为单位向右、向下移动,stride的取值原则是希望能和移动前的接受域有重叠的部分(因为可能一个特征正好被划分开了),当移动后越界了,可以采用padding(补值),补值可以全部填0,也可以全部填平均值。并且,每一个接受域都有很多神经元一起看着,图中就是64个神经元看着同一个接受域。
第二个问题是:也许都是检测鸟嘴,第一张图片可能在左上角,第二张图片可能在中间,虽然按照上面划分接受域的方法总会检测到,但没有必要。
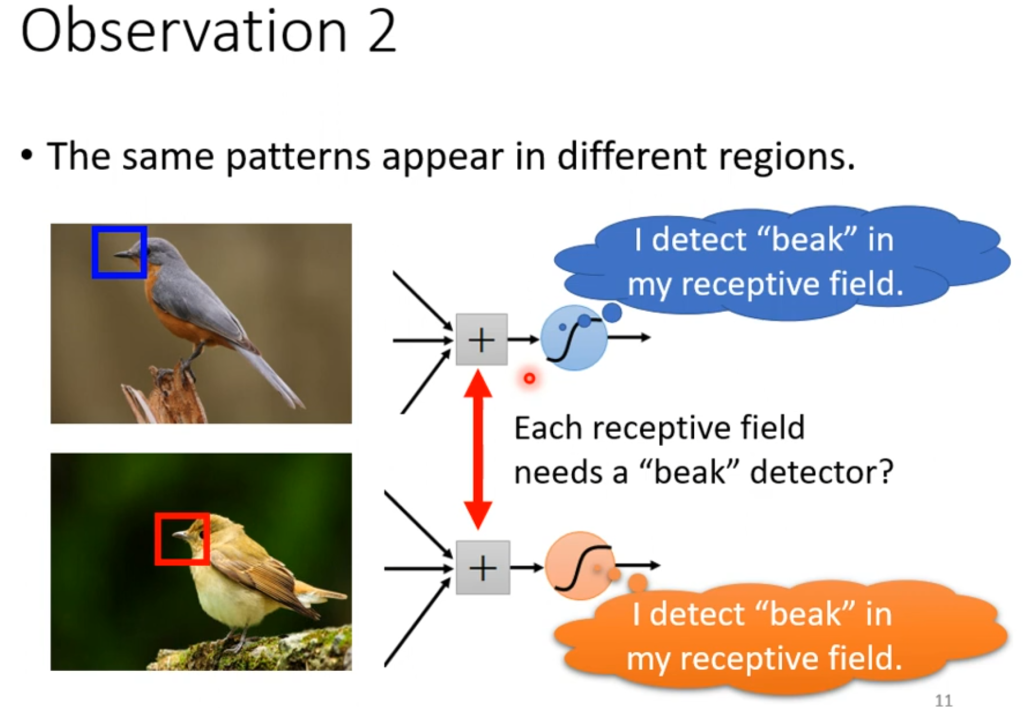
解决方法就是“共享参数”,即让两个不同的接受域采用一样的参数(w,b)
ps:这里有一个误解,就是共享参数后两块接受域的输出不会一样吗?答案是不会的,因为接受域不同所以输入也是不同的。
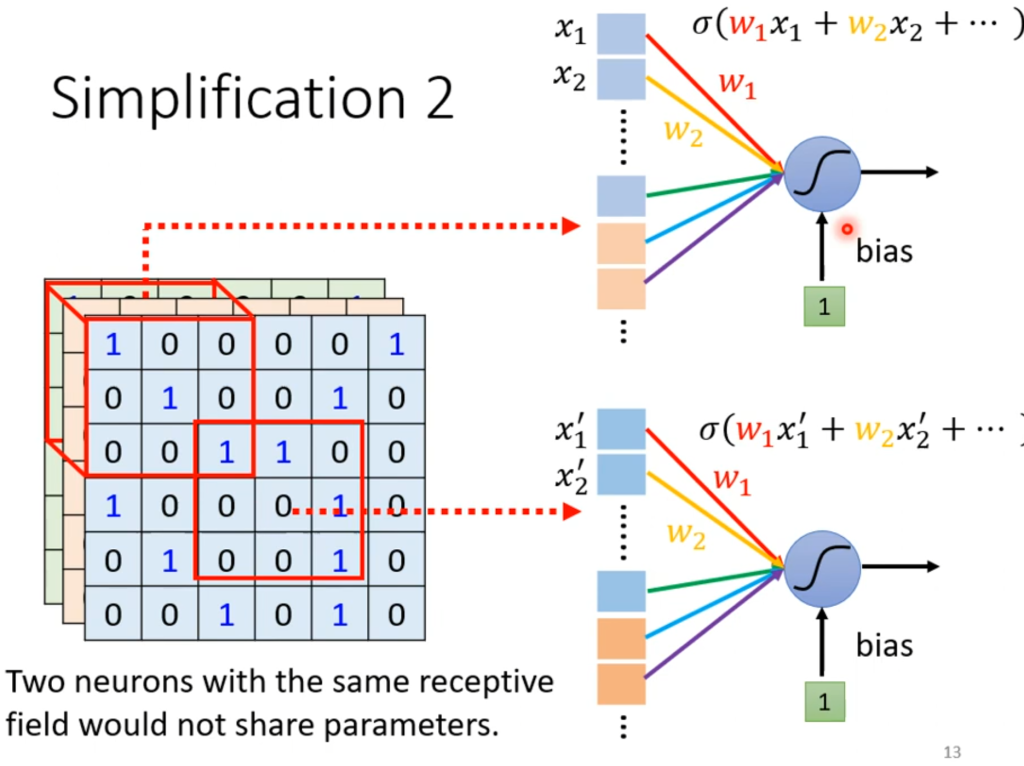
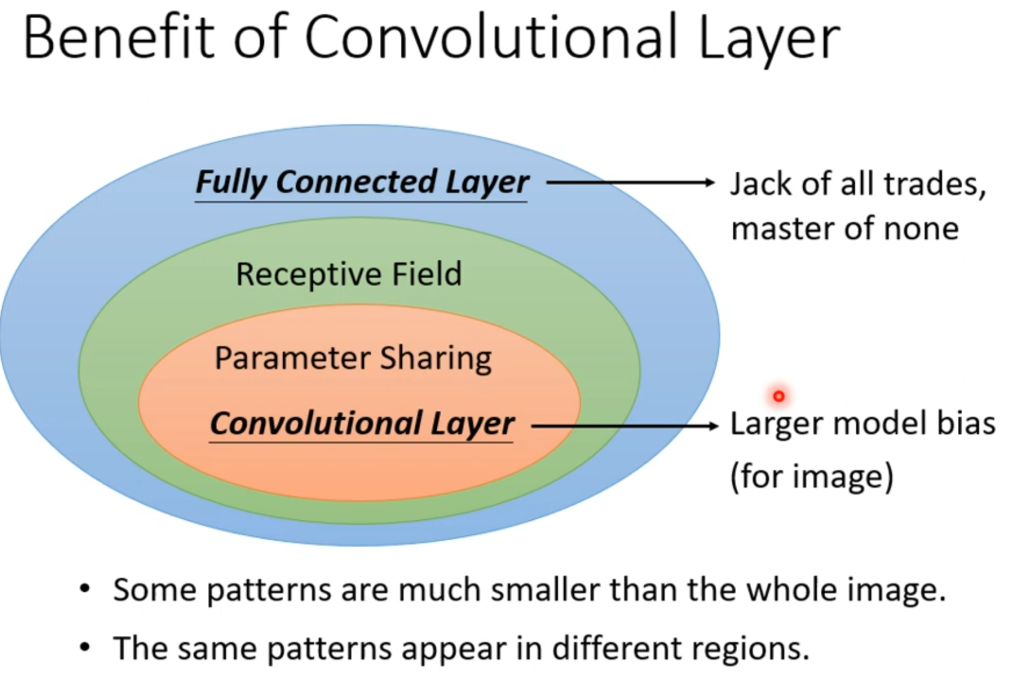
总结一下,普通的神经网络采用的全连接神经元,模型更有弹性,模型的bias也小。经过接受域和共享参数的称为卷积层(convolutional layer),使用了卷积层的神经网络就称为CNN。
CNN的模型误差是大的,但这并不是一件坏事,它可以防止过拟合。可以说是专门为影视图像作为输入的问题所提出的模型。
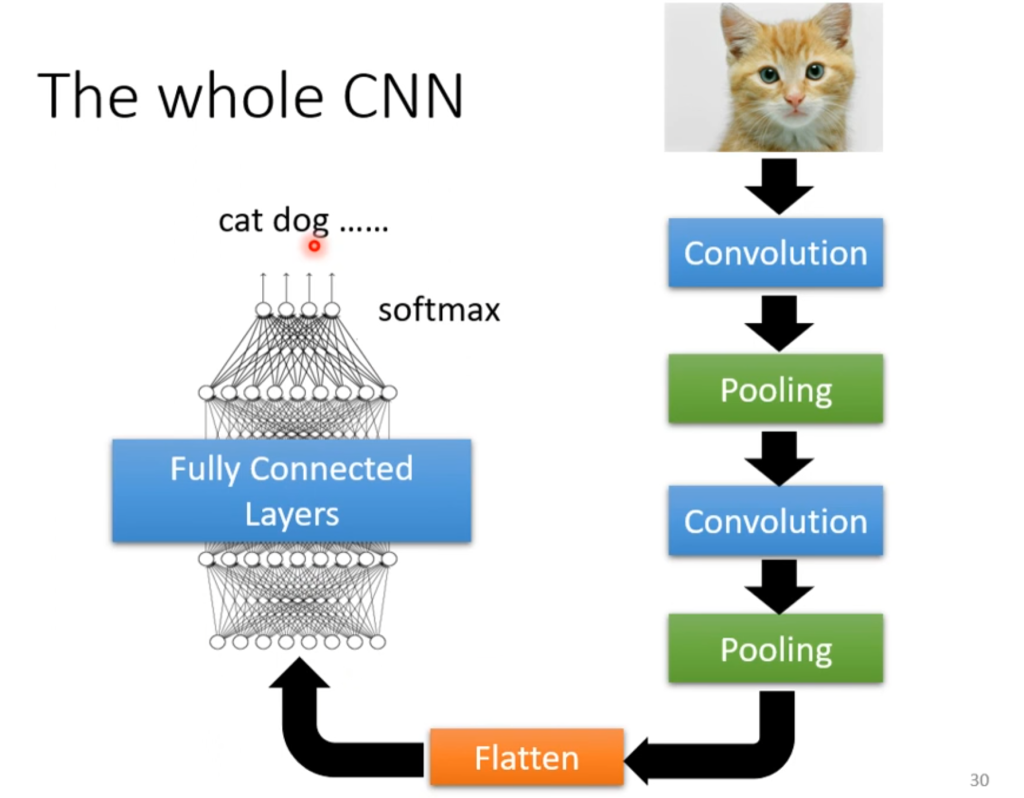
所以,CNN的总体流程如右图,在经过了一系列卷积和池化之后,再经过Flatten和softmax,就可以输出一个和为1的向量了。
Comments NOTHING