


RNN
RNN需要一个叫做槽填充(slot filling)的技术。例如输入“我想订一张12月2号去台北的票”,有个“槽”可以识别“台北”属于目的地,“12月2号”属于日期,而其他词汇不属于这两类。
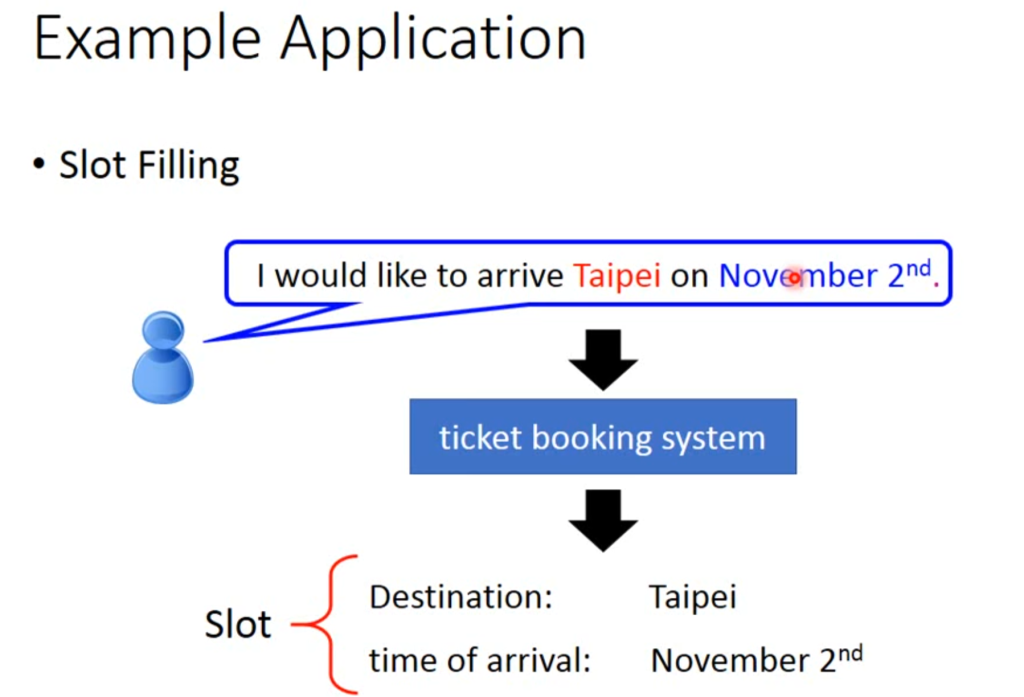
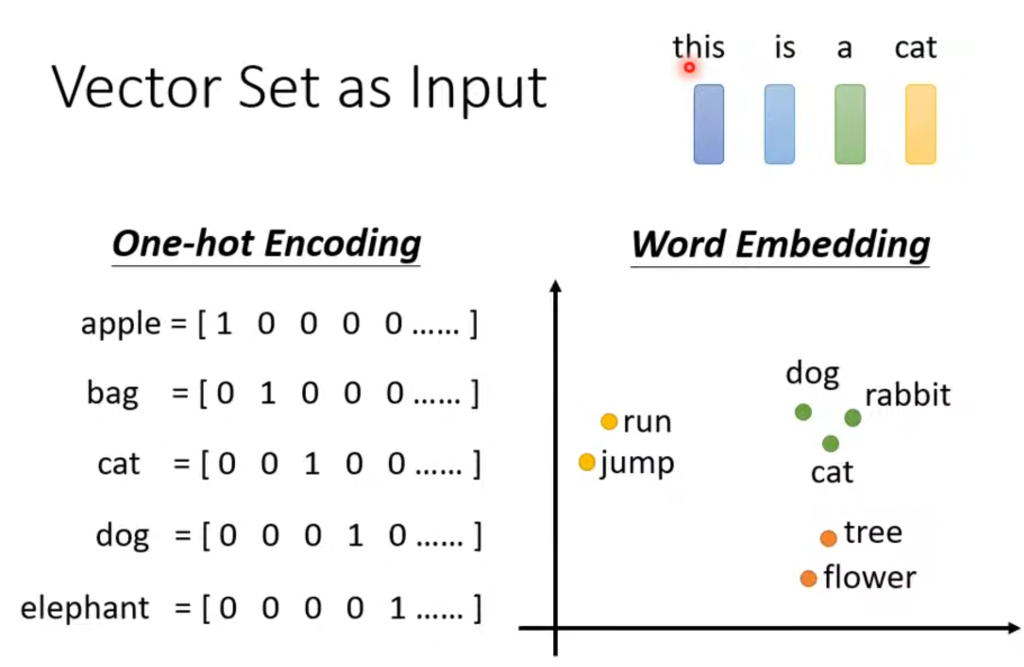
那怎么实现呢,首先我们需要将单词作为一个向量的形式输入到神经网络当中,方法有很多,例如1-of-N encoding

当然,肯定会有没遇到过的单词,因此可以在1-of-N encoding基础上再添加一个维度“other”用来表示不在向量内的单词。
其他的方法例如根据单词的字母表示的word hashing表示法也可以用向量表示单词。

将单词作为向量输入后,经过一个分类神经网络判断是属于“目的地”、“日期”还是“other”。
但这种神经网络是不行的,因为如果有个人说的是“我想在12月2号从台北出发”,那这句话的台北就是出发地而不是目的地。为了解决这个问题,需要让神经网络具有“记忆功能”,让它知道台北的前一个单词是离开还是到达的意思。
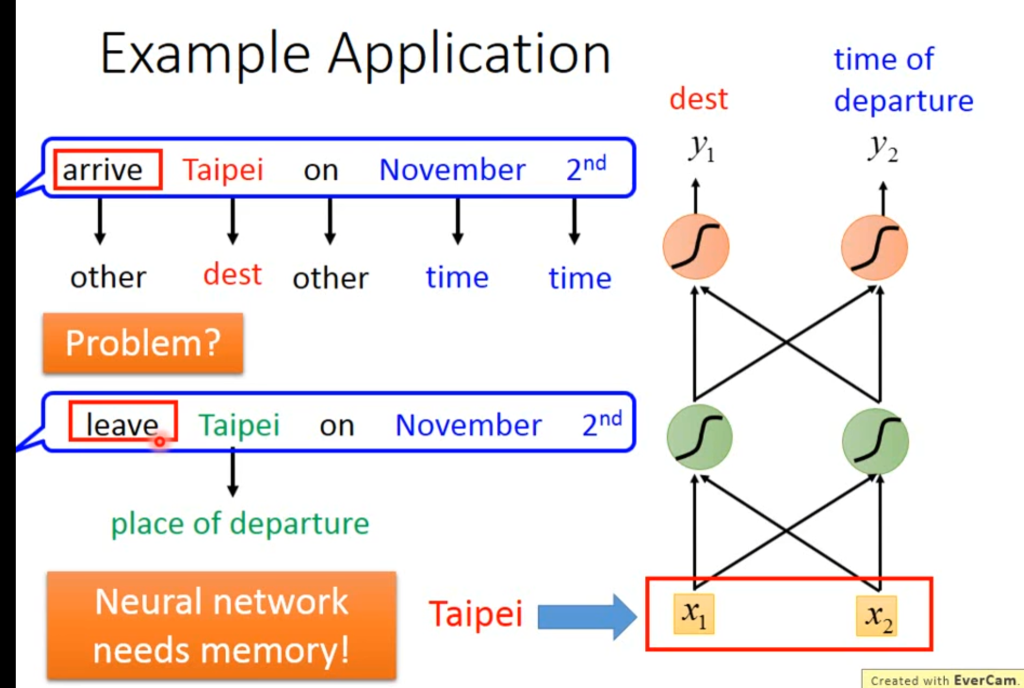
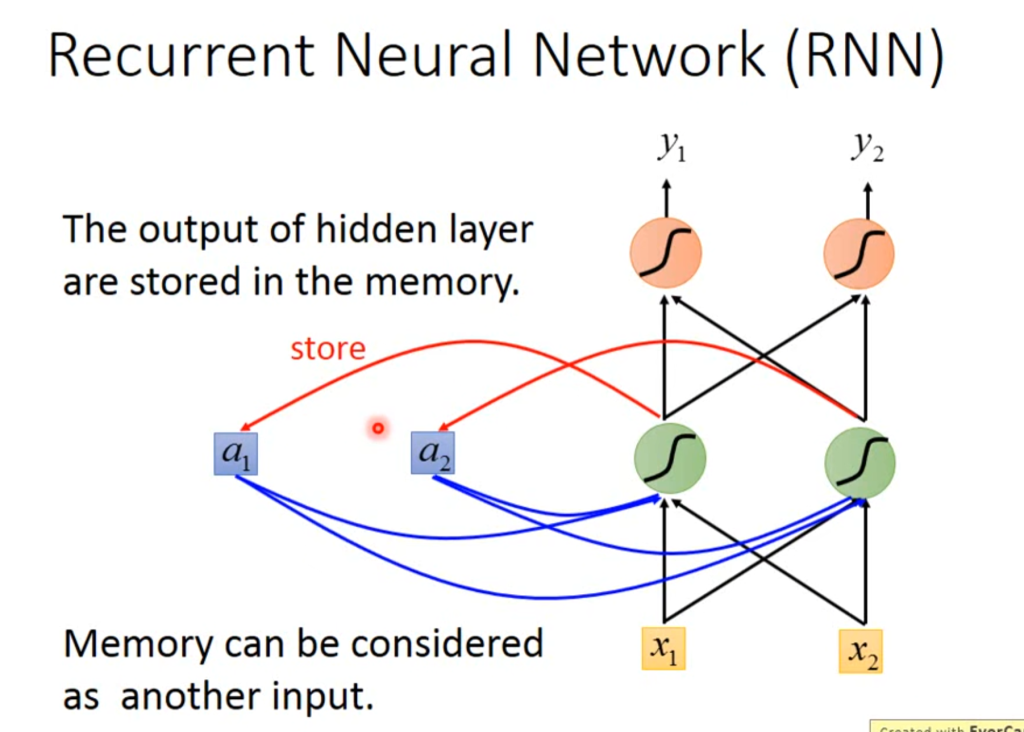
这种具有记忆能力的神经网络就叫做recurrent neural network,简称RNN。
RNN网络在每个隐含层都会储存该隐含层的信息(图中的a1和a2),当下一次神经网络输入时,就会考虑储存在a1和a2中的值。
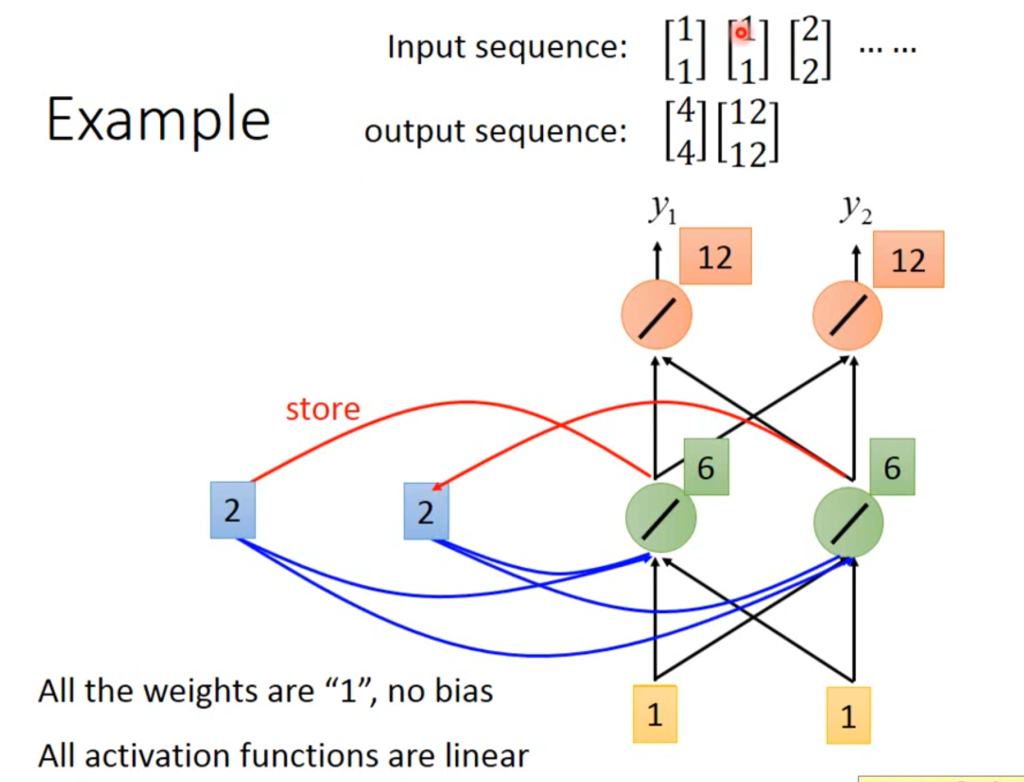
举个例子吧,例如一个简单的神经网络,w=1,b=0,输入分别是【1,1】,【1,1,】,【2,2】,一开始存储位置有一个初始值0。
当输入【1,1】的时候,隐含层的值为2,2,输出层的值为【4,4】,这时将2,2存储。
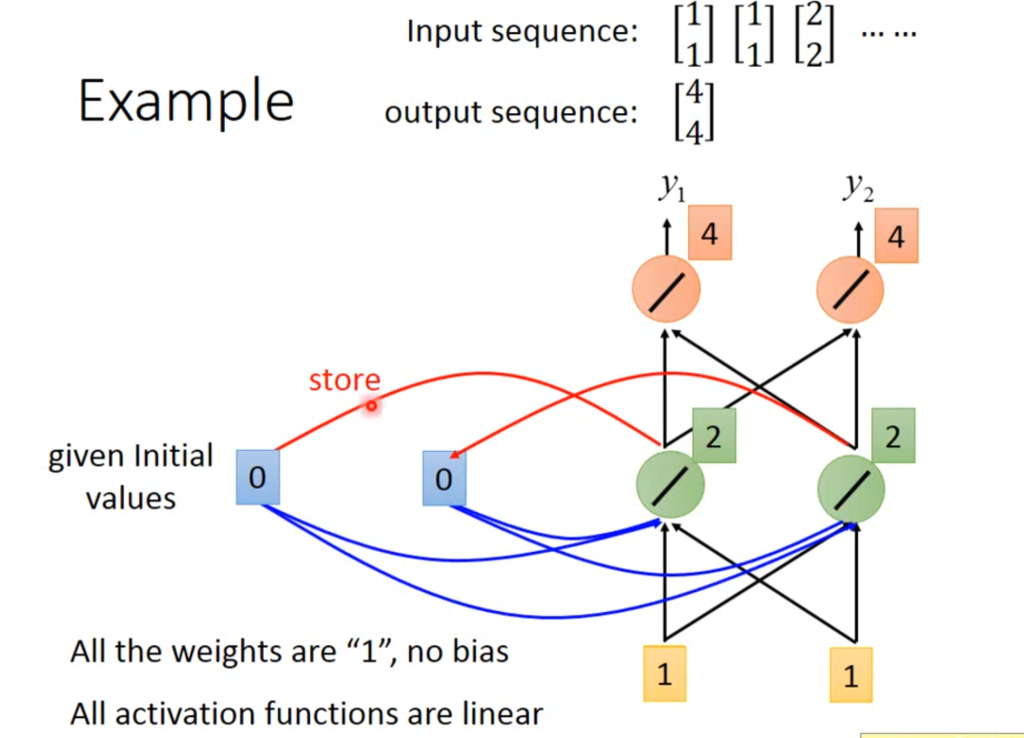
继续输入【1,1】,由于受到存储的影响,隐含层的值变为1+1+2+2=6.输出层的值为【12,12】,然后6,6会覆盖2,2存储进去。
因此,RNN网络即使输入的数据相同,输出也有可能不同,并且输入的顺序不同,输出的值也会不同
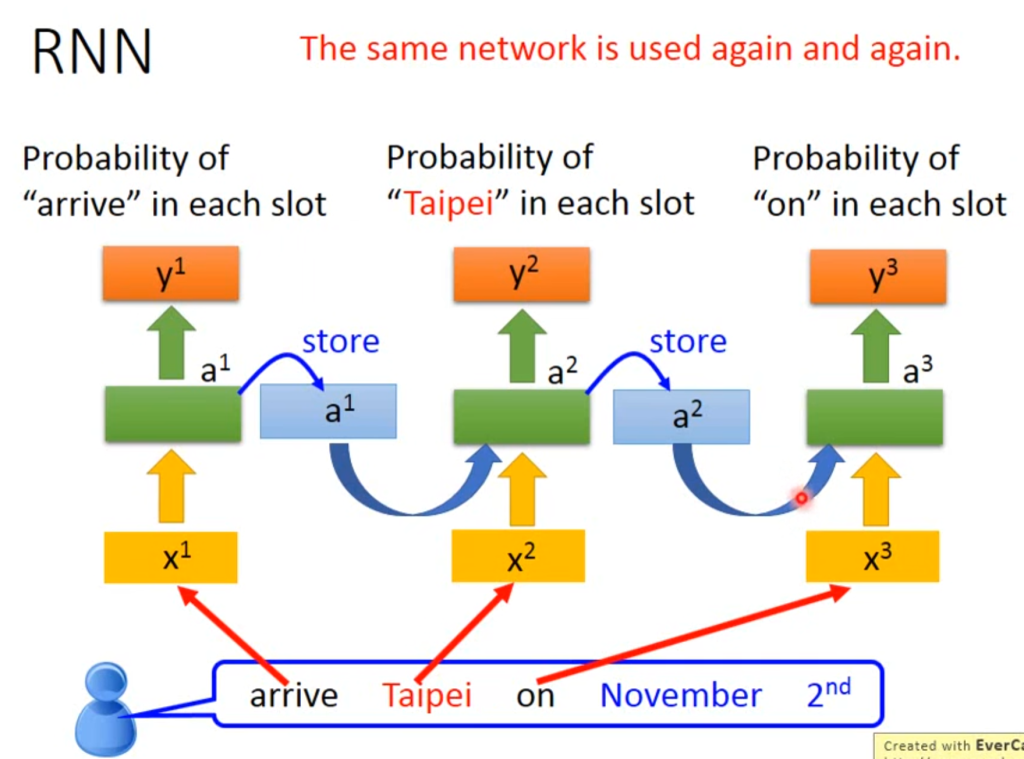
因此,RNN网络判断的流程是:
arrive输入,判断为“other”,并存储在a1中
taipei输入,根据a1确定为目的地,并存储在a2
on输入,根据a2确实为“other”,并存储在a3
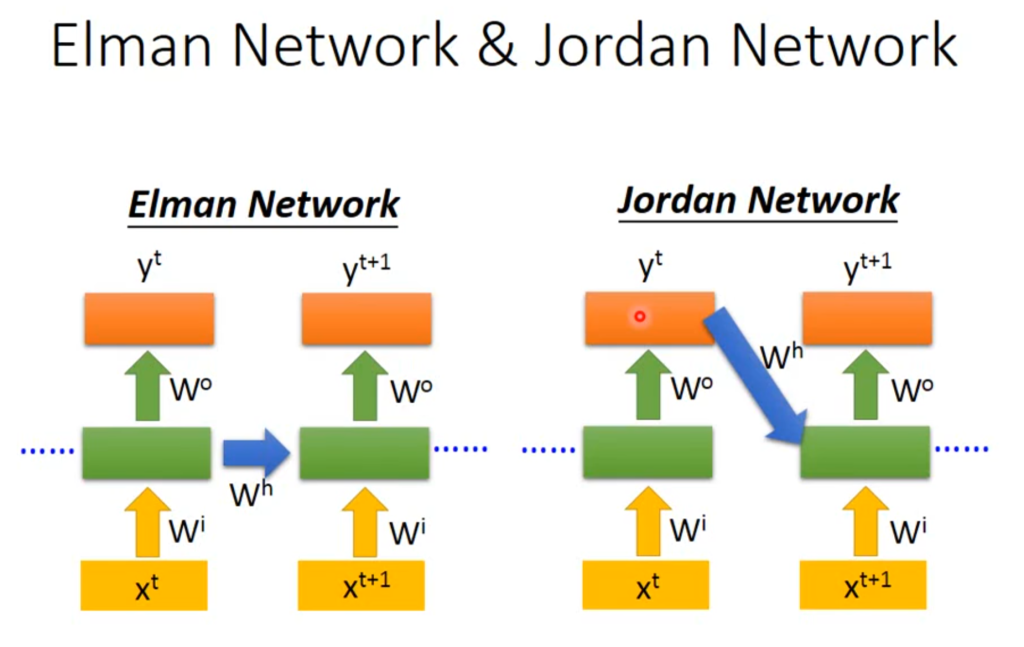
当然,RNN网络不只有一种形式,上面的是将隐含层的信息存储下来,也有将输出层的信息存储下来。
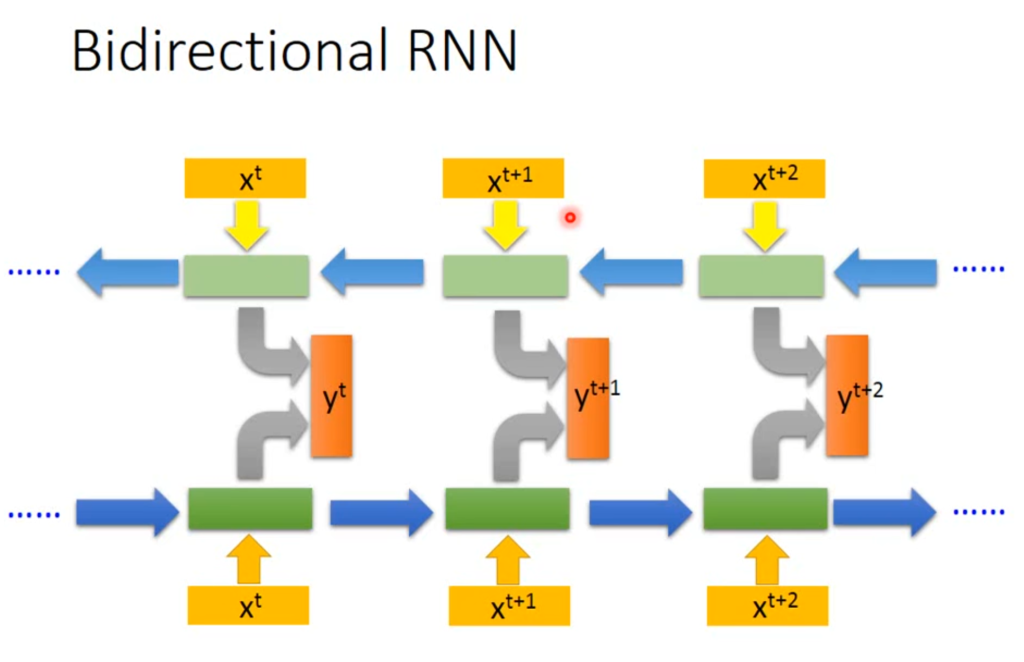
还有双向RNN,输出会考虑前一个单词和后一个单词
上面说的是最简单的一种RNN,随时存储随时读取。现在常用的一种RNN网络叫做Long Short-term Memory(LSTM),它有一个input gate决定是否允许存入,有一个output gate决定是否允许读出,有一个forget gate决定是否要清空现在的记忆池。
总体来看,LSTM有四个输入一个输出,四个输入分别是想进入input gate的信息,控制input gate的信号,控制output gate的信号,控制forget gate的信号。一个输出是从output gate输出的信息。
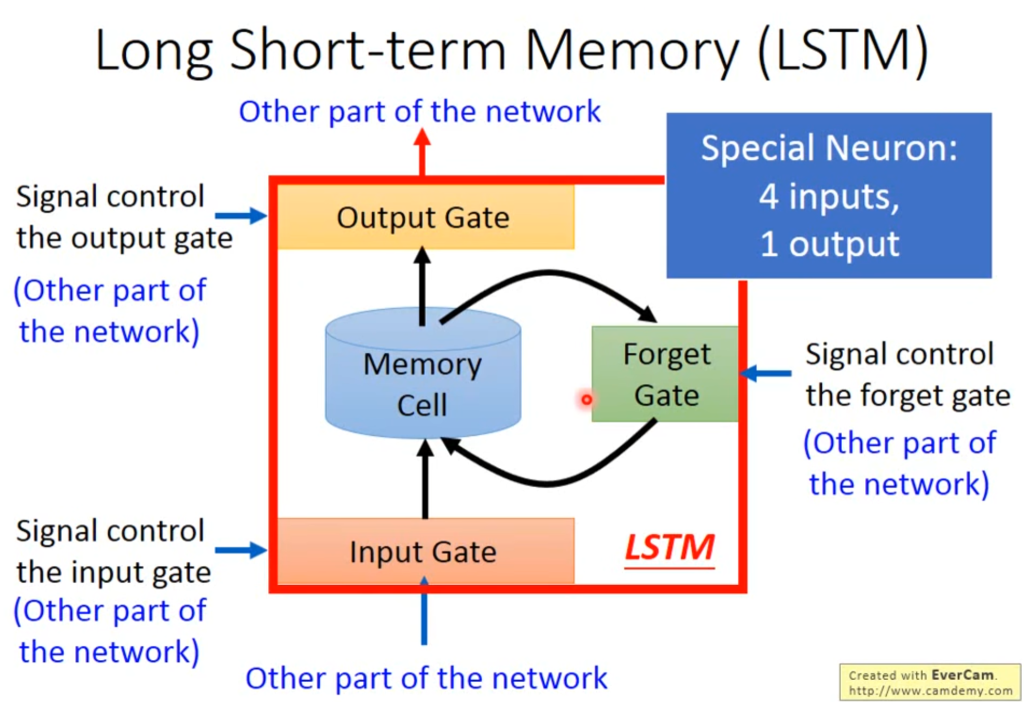
具体来讲,输入信息z经过函数g变成g(z),由f(zi)决定是否存储,由f(zf)决定是否遗忘。存储式子就是图中的式子,当f(zi)为0时相当于没存储进来,当f(zf)为1的时候相当于不遗忘以前的数据(这和感知相反,一般forget=1代表允许遗忘,这里=1代表记得)。输出同理,当f(zo)=0时相当于没读出去。
值得一提的是zi、zf、zo的sigmoid函数都是一样的,转换为了0-1之间的数,靠近0就是0,靠近1就是1.、、
(当zi和zf同时为0,代表清空记忆池里的数据)
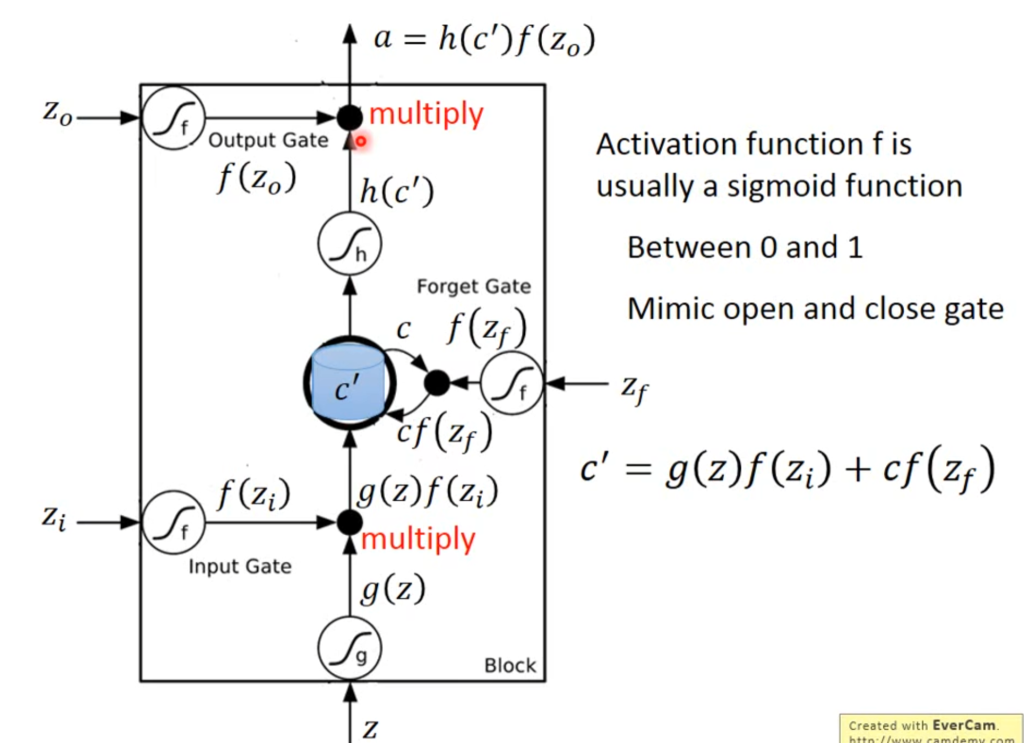
RNN和普通的神经网络的不同之处在于,普通神经网络的一个神经元只连接了一个输入端和一个输出端,RNN网络的每个神经元是上图这个大池子,有四个输入端和一个输出端。因此参数是普通神经网络的四倍。
在实际训练中,一般说使用RNN训练默认采用LSTM,只有说simpleRNN才是普通RNN网络的意思,还有一种RNN网络是GRU
在RNN网络刚出来的时候,出现过损失函数曲线和蹦极一样的一上一下的,这是因为普通RNN网络每次输入都会覆盖记忆存储地,导致每次梯度下降的步伐非常不稳定,时大时小。而LSTM的记忆池是叠加的,当forget gate打开的时候不会完全覆盖,会与记忆池里的数据相加,也就是说可以影响到后续训练,不会导致不稳定。而forget gate也经常是打开状态,不会频繁的遗忘。
自注意力机制
在上一章CNN网络中提到,假定每个图片都是100×100的,那么如果输入的一串向量是不规则的、长度不定的呢?
比如说输入是一个句子,可以用one-hot encoding,把每一个单词都当做向量中的一个值。不过这个方法有个缺点就是认为单词之间是没有联系的,它看不出来cat和dog都属于动物。另一种方法就是word embedding,它将语义相近的词都聚类在一起
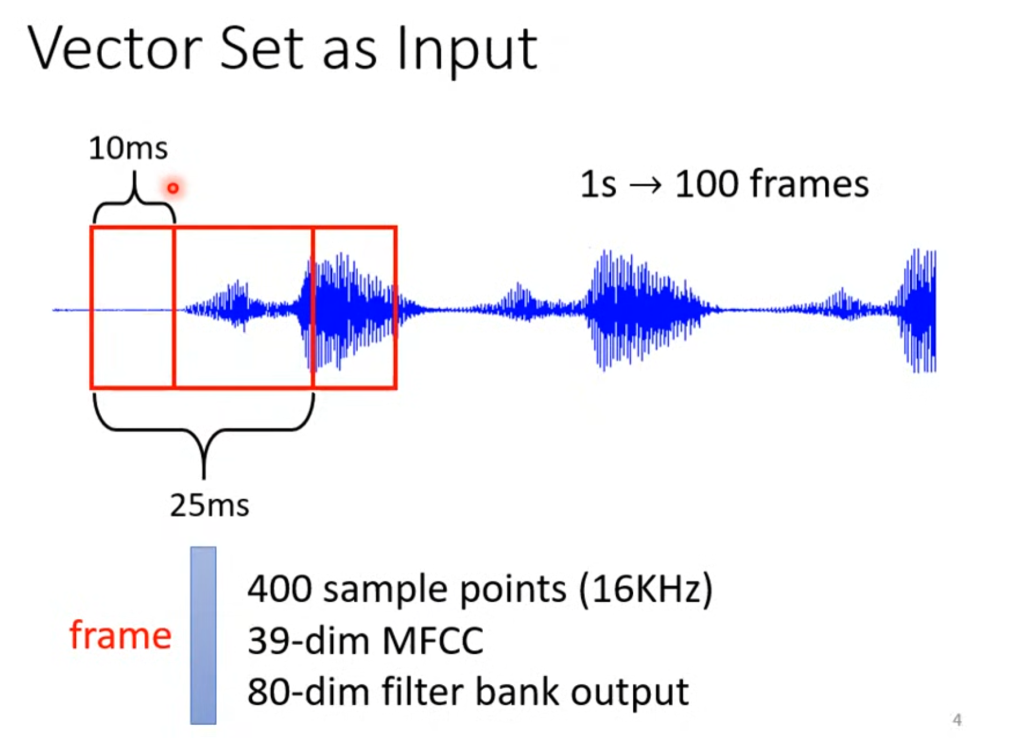
再比如输入是语音,语音的表示也是有一堆向量组成,设定25ms为一个窗(frame),将这个窗转化为一个向量,然后移动10ms划出下一个窗。因此一个1s的音频就有100个向量表示。
还有什么呢?图(数据结构)也是用一堆向量表示,关系网中的每一个节点都是一个向量,记录一个人的信息。
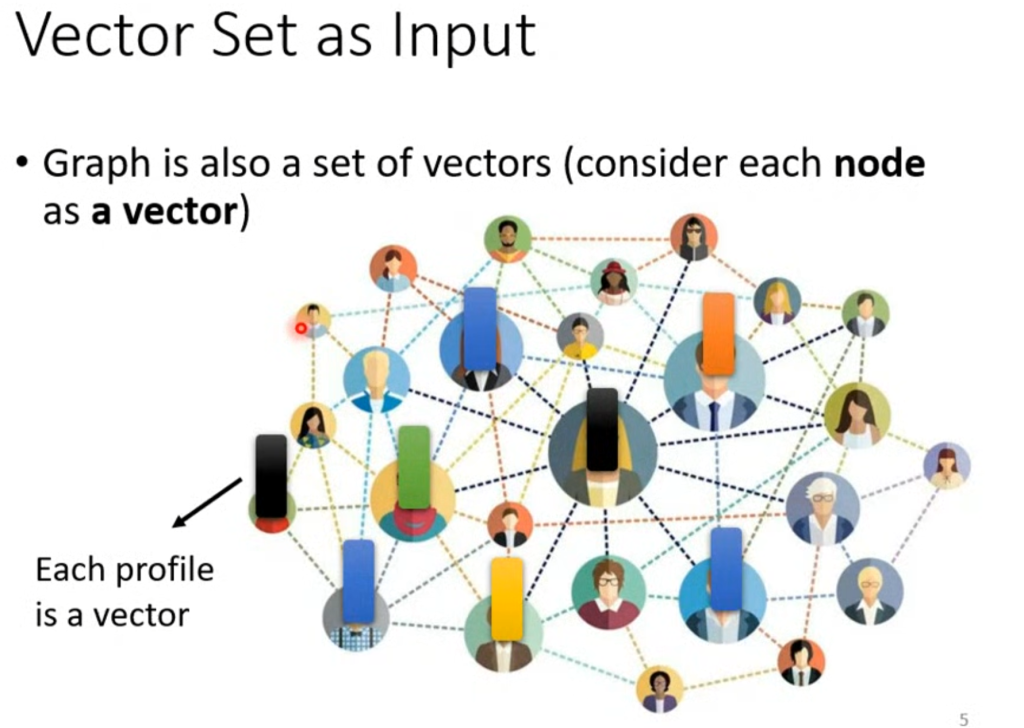
那么输入是一堆向量,输出会是什么呢?
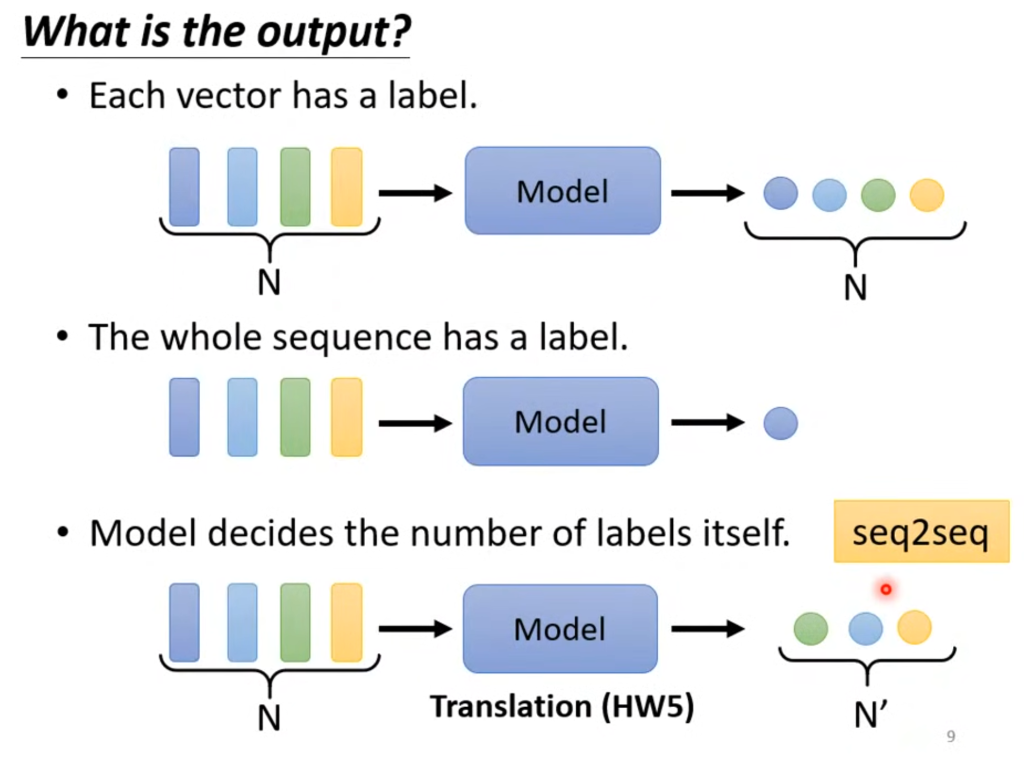
第一种:输出的个数和输入向量的个数相同,例如判断输入每个单词的词性。
第二种:输出个数为1,例如判断输入的一句话是正面还是负面评价
第三种:输出个数由神经网络自己决定,例如语音识别,输出的句子长度和输入的语音向量不同。
在这一章,只讲第一种情况。
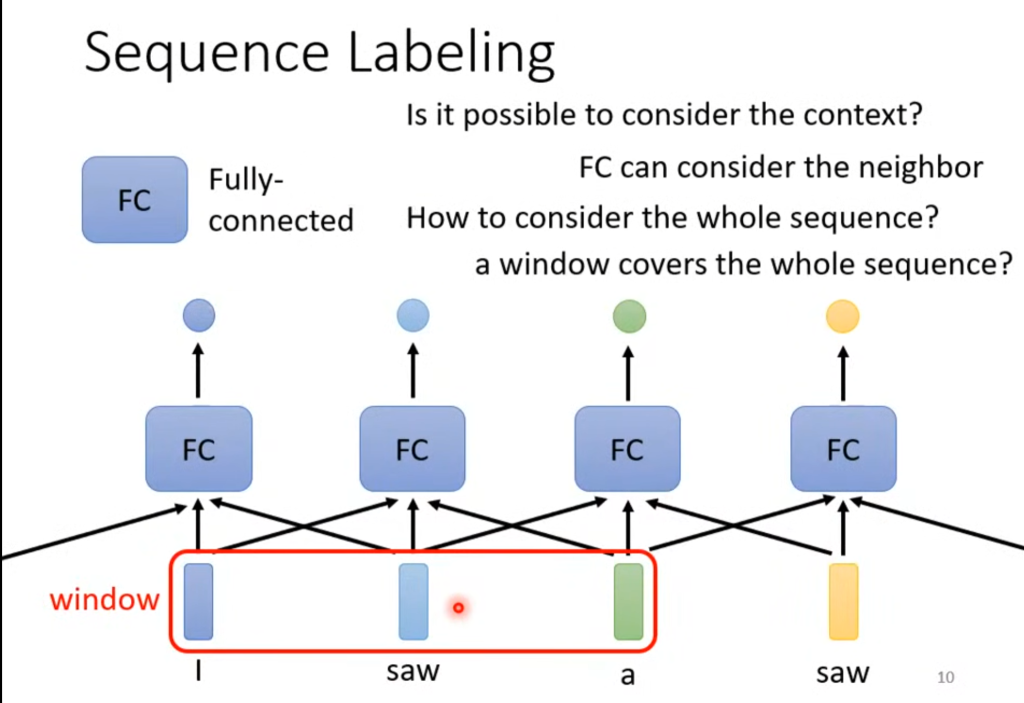
对于输入句子输出每一个单词的词性这个例子,我们可以怎么设计神经网络呢?
我们先尝试把每个单词分别传入一个全连接的神经网络来判断词性,但这显然是不行的,因为对于独立的神经网络来说,第一个saw和第二个saw在它眼里是一样的。那利用RNN让这个神经网络拥有前几个或者后几个训练的记忆呢?对于部分情况来说是可以的,但对于需要看完整个句子才能判断词性来说,是不合理的,因为你并不知道这个句子有多长。
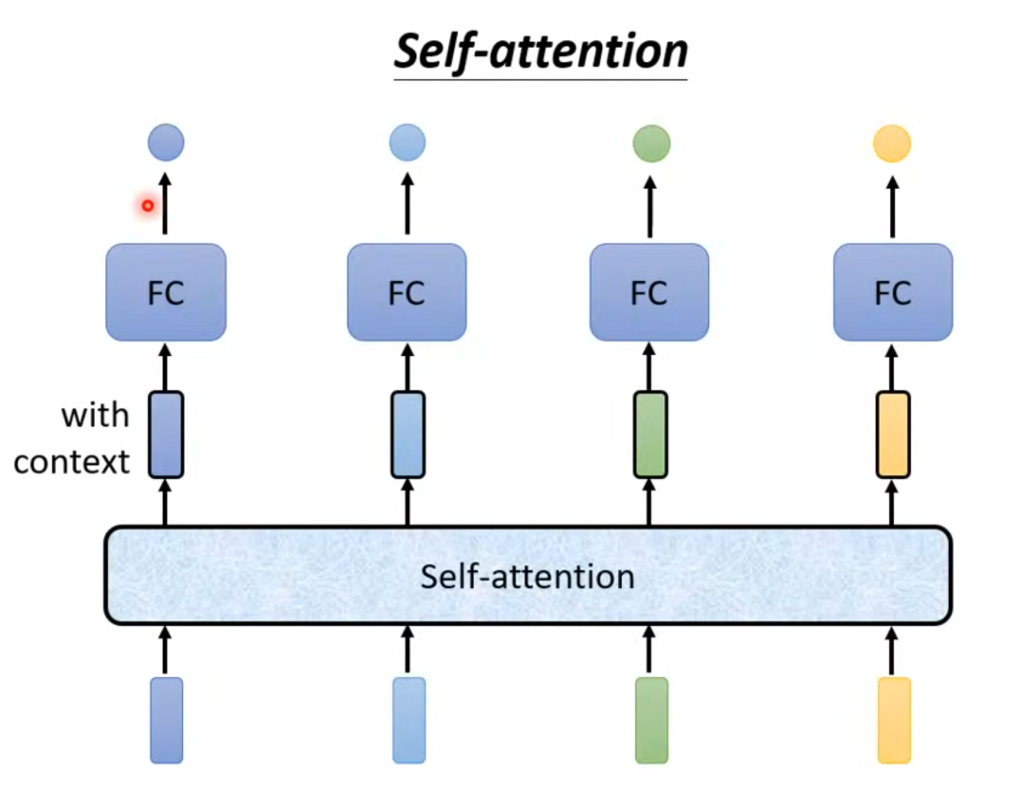
而考虑整个输入再决定输出的方法,就是自注意力机制(self attention),
如图,在经过自注意力机制后,每个输入都不只是单独的一个单词,而是考虑了整个句子(经过处理后的)的一个输入
那自注意力机制内部是什么构造呢?
自注意力的输入可以是输入层,也可以是隐含层,某个输入对应的输出是考虑了所有输入的结果。在自注意力内部,两两输入之间会有一个关联度α,
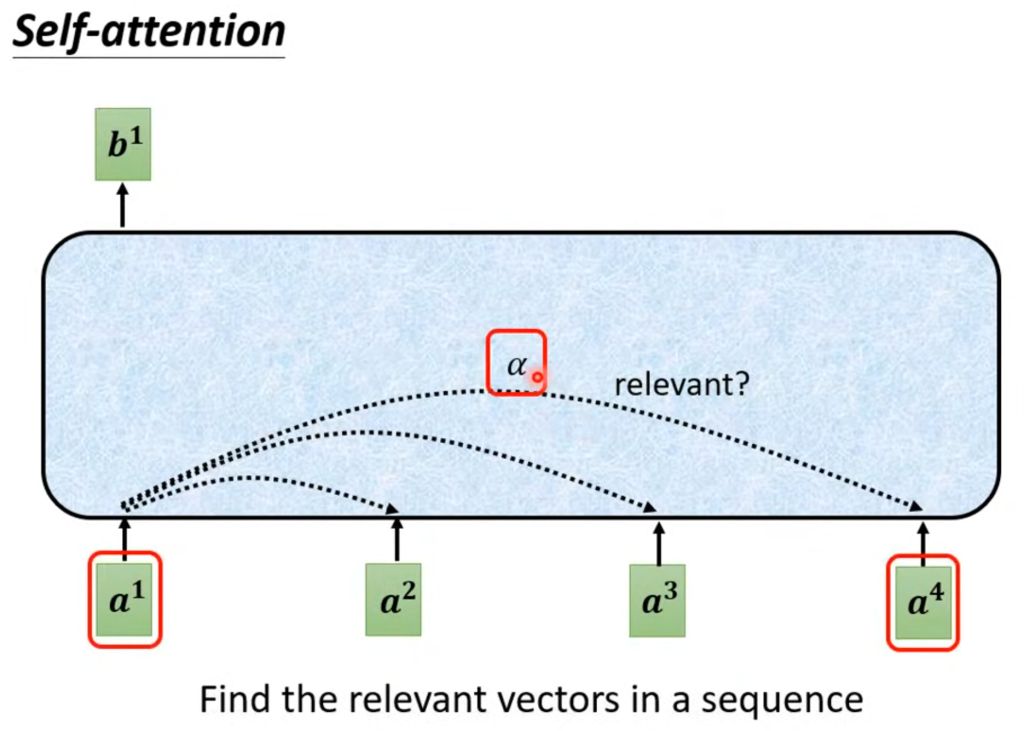
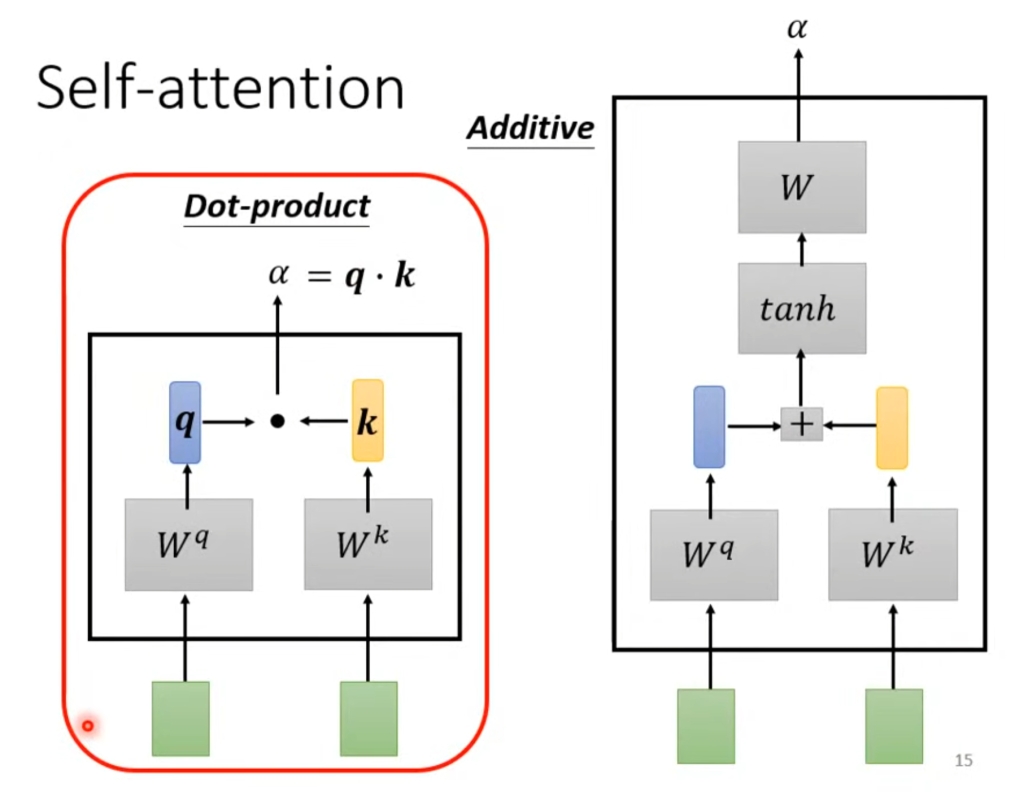
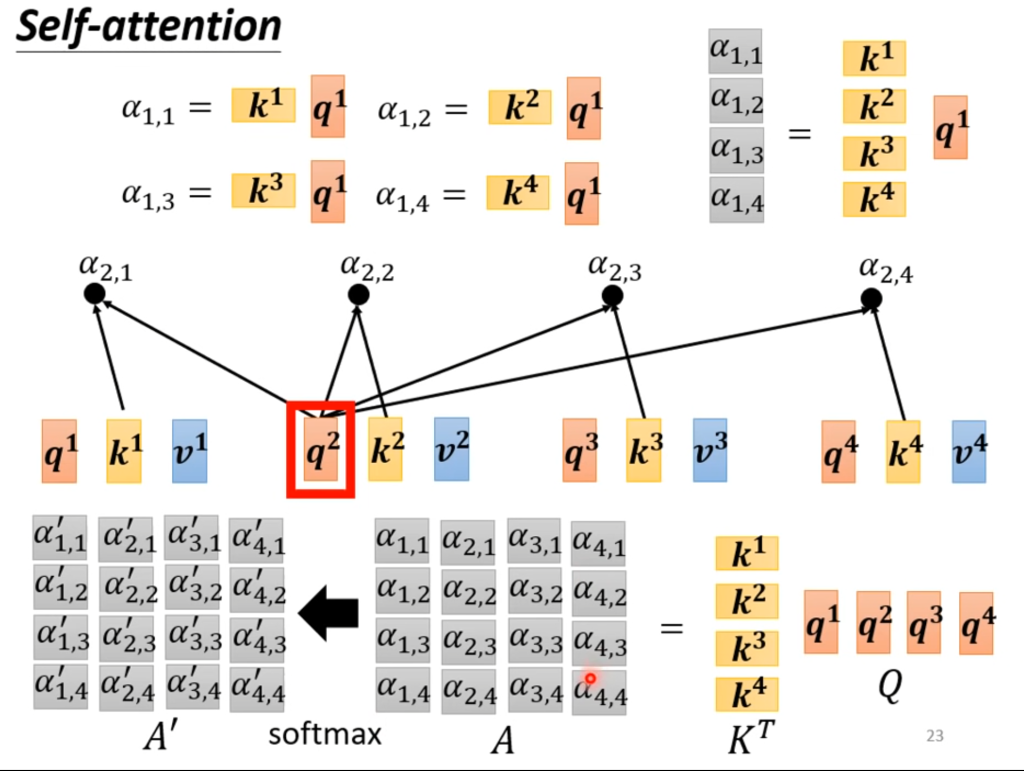
这个关联程度α是怎么得来的呢?有很多种计算方法,例如Dot-product将两个输入分别乘以两个矩阵Wq和Wk,然后将结果相乘得到相关度α。
其他的方法例如additive用的相加再取tan也是一种设置相关度的方法。在本章我们采用第一种,这也是实际情况中最常用的一种。
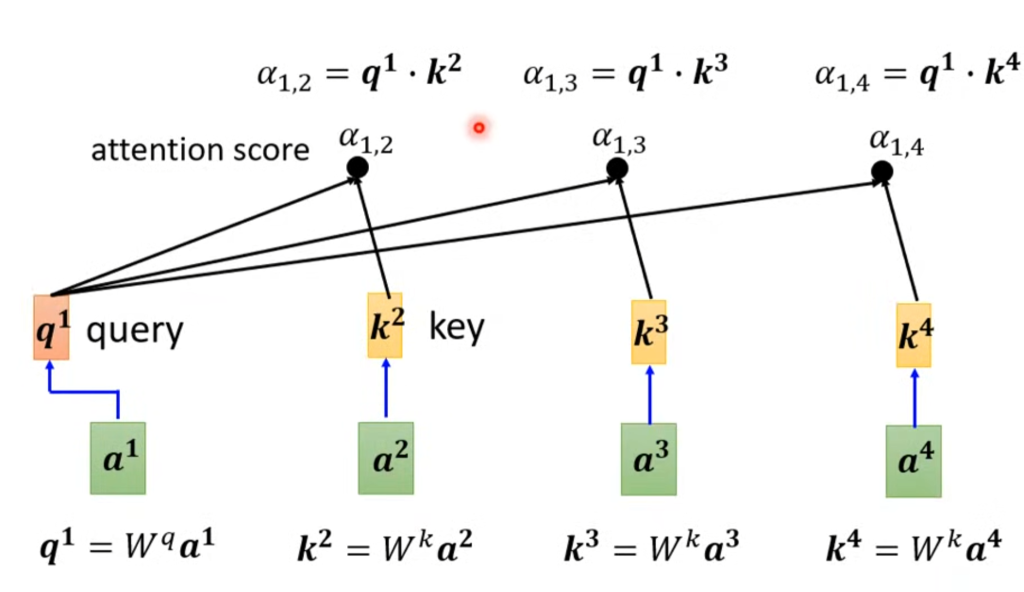
上面Wq和Wk的q表示query(询问我和其他人的关联度),k表示key(别人关联我的权值),因此将Wq×a1得到q1,将a2,a3,a4×Wk得到k2,k3,k4,将q1和k2相乘就得到由a1询问a2与自己的关联程度是多少,剩下同理。这个a(1,2)还有个名称叫做注意得分(attention score)。
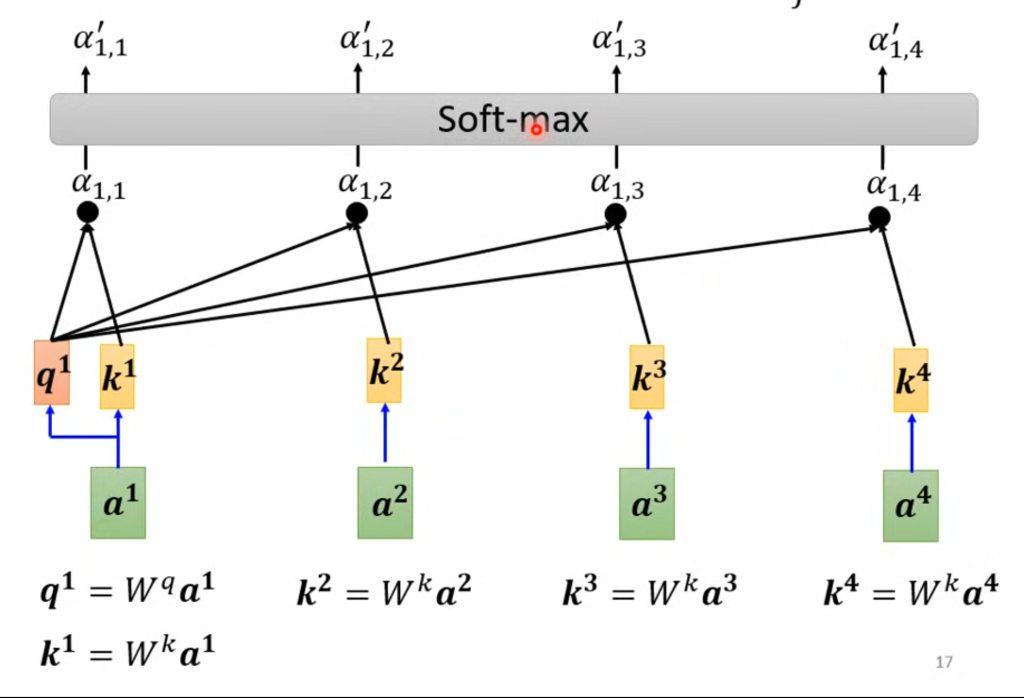
在算完了与各个输入之间的关联度之后,会经过soft-max处理,当然这里用soft-max只是因为常用,并不是必须。
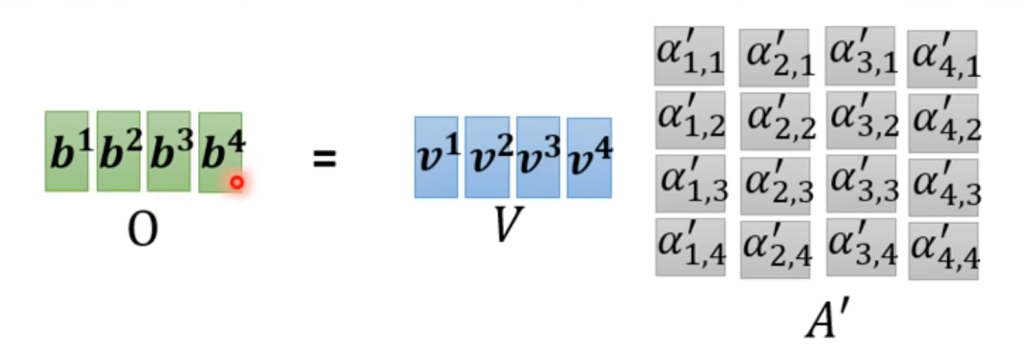
最后,每个输入还会乘上一个矩阵Wv,将各个相关度与对应的v相乘再相加得到a1的最终输出b1
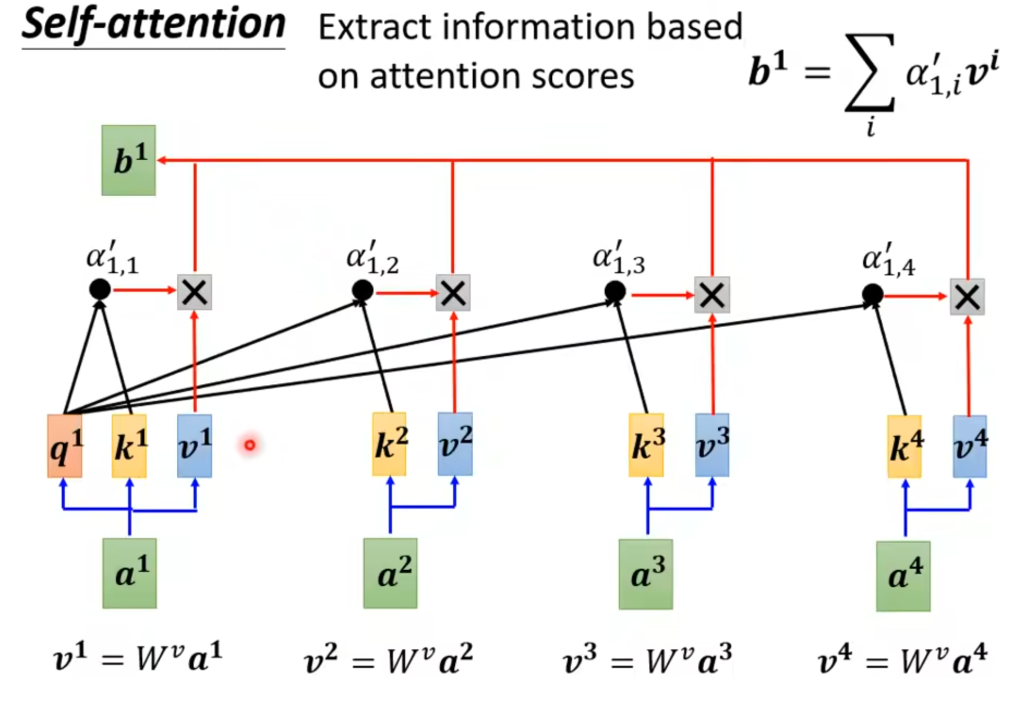
如果觉得上面的描述过于复杂,不妨从线代矩阵的角度入手,大量的运算其实只是两个矩阵相乘。
由此可以看出,其实未确定的只有Wq,Wk,Wv这三个矩阵。
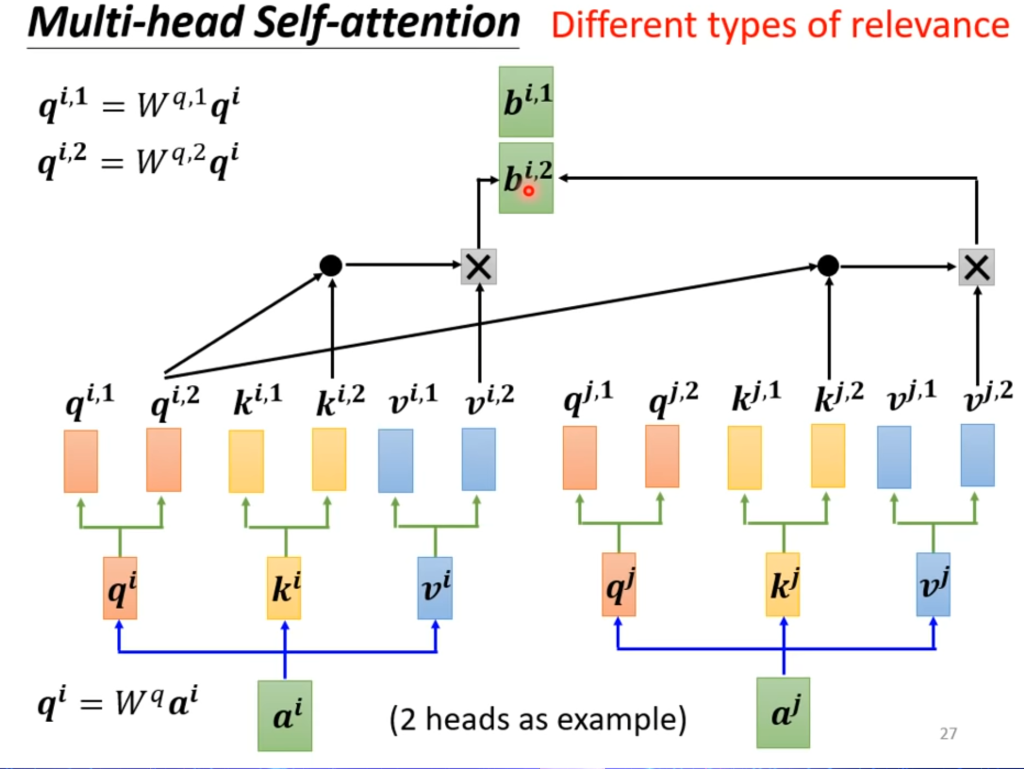
多头自注意力机制
在某些问题中,可能存在不同的相关度的算法,这就引出多头注意力机制,一个输入由两个q去询问,那自然k和v也有对应的两个。
自注意力机制和CNN的区别在于,CNN只关注自己负责的一块区域,自注意力也负责一块区域,但会把整个区域都看完。从某种角度上看算是一种复杂版的CNN。
自注意力机制和RNN的区别在于,RNN也会根据前一个或者后一个的信息影响当前的训练,但不会看完整体。
自注意力机制和下一章trainsformer密切相关,广义上的trainsformer就可以认为是自注意力机制,但自注意力机制的计算量太大了,因此后面衍生出了各种优化算法,以-former结尾的都是。
Comments NOTHING